advanced value counts
1.0.0
Advanced-Value-Counts ist ein Python-Package, das die Klasse AdvancedValueCounts enthält, die Pandas ' .value_counts() , .groupby() und Seaborn verwendet, um problemlos viele Informationen über die Zählungen einer (kategorischen) Spalte in einem Pandas-Datenfrequellen zu erhalten. Das Potenzial dieses Pakets ist auf dem Höhepunkt, wenn Sie Informationen über eine Spalte nach einer Gruppierung haben: df.groupby(groupby_col)[column].value_counts() . Sehen Sie die Verwendung der Verwendung von AdvancedValueCounts an. Lesen Sie diesen mittleren Artikel oder wenden Sie sich an dieses Notizbuch, um eine Erläuterung zum Mehrwert dieses Pakets zu erhalten.
Inhaltsverzeichnis :
pip install advanced-value-counts
Wenn Fehler auftreten
python3 -m pip install --upgrade pip
python3 -m pip install --upgrade setuptools
git clone https://github.com/sTomerG/advanced-value-counts.git
cd advanced-value-counts
pip install -e .
# optional but potentially crucial
pip install -r requirements/requirements.txt
Um zu testen, ob die Installation im Verzeichnis mit fortgeschrittenem Wert erfolgreich ausgeführt wurde ( Devistivewarnings werden erwartet)
pytest
Das folgende Beispiel verwendet eine modifizierte Version des Titanic -Datensatzes von Kaggle, die hier in diesem Gitrepo zu finden ist.
Der Code dieses Notizbuchs finden Sie hier.
from advanced_value_counts . avc import AdvancedValueCounts
import pandas as pd
# read in the data file
df = pd . read_csv ( '../tests/data/titanic.csv' , usecols = [ 'CabinArea' , 'Title' ])
df . head ()| Gehäuse | Titel | |
|---|---|---|
| 0 | Nan | Herr. |
| 1 | C | Frau |
| 2 | Nan | Vermissen. |
| 3 | C | Frau |
| 4 | Nan | Herr. |
# create an instance of AdvancedValueCounts
avc = AdvancedValueCounts ( df = df , column = 'Title' )
# print the AdvancedValueCounts DataFrame
avc . avc_df| Verhältnis | zählen | |
|---|---|---|
| Titel | ||
| Herr. | 0,580247 | 517 |
| Vermissen. | 0,204265 | 182 |
| Frau | 0,140292 | 125 |
| Master. | 0,044893 | 40 |
| _n / A | 0,007856 | 7 |
| Rev. | 0,006734 | 6 |
| Wesentlich. | 0,002245 | 2 |
| Col. | 0,002245 | 2 |
| Mlle. | 0,002245 | 2 |
| Gräfin. | 0,001122 | 1 |
| Capt. | 0,001122 | 1 |
| MS. | 0,001122 | 1 |
| Herr. | 0,001122 | 1 |
| Dame. | 0,001122 | 1 |
| Mme. | 0,001122 | 1 |
| Don. | 0,001122 | 1 |
| Jonkheer. | 0,001122 | 1 |
Setzen Sie min_group_count auf 5 auf Gruppen kleine Gruppen in die Gruppe '_other'
avc . min_group_count = 5
avc . avc_df| Verhältnis | zählen | |
|---|---|---|
| Titel | ||
| Herr. | 0,580247 | 517 |
| Vermissen. | 0,204265 | 182 |
| Frau | 0,140292 | 125 |
| Master. | 0,044893 | 40 |
| _andere | 0,015713 | 14 |
| _n / A | 0,007856 | 7 |
| Rev. | 0,006734 | 6 |
Parameter der Klasse AdvancedValueCounts , um kleine Gruppen für eine einzelne Spalte anzupassen:
dropna : bool = False
min_group_count : int = 1 # does not effect NA or the '_other' group
min_group_ratio : float = 0 # does not effect NA or the '_other' group Es ist auch möglich, column in Kombination mit Parameter groupy_col: str = None , um das Verhalten von df.groupby(groupby_col)[column].value_counts() nachzuahmen.
avc_grouped = AdvancedValueCounts ( df = df , column = 'Title' , groupby_col = 'CabinArea' )
avc_grouped . avc_df| zählen | subgroup_ratio | subgr_r_diff_subgr_all | r_vs_total | ||
|---|---|---|---|---|---|
| Gehäuse | Titel | ||||
| A | Col. | 1 | 0,066667 | 0,064422 | 0,001122 |
| Dame. | 1 | 0,066667 | 0,065544 | 0,001122 | |
| Master. | 1 | 0,066667 | 0,021773 | 0,001122 | |
| Herr. | 11 | 0,733333 | 0,153086 | 0,012346 | |
| Herr. | 1 | 0,066667 | 0,065544 | 0,001122 | |
| ... | ... | ... | ... | ... | ... |
| _n / A | Frau | 81 | 0,117904 | -0.022388 | 0.090909 |
| MS. | 1 | 0,001456 | 0,000333 | 0,001122 | |
| Rev. | 6 | 0,008734 | 0,002000 | 0,006734 | |
| _n / A | 4 | 0,005822 | -0.002034 | 0,004489 | |
| _gesamt | 687 | 1.000000 | 0,000000 | 0,771044 |
74 Zeilen × 4 Spalten
Um einen besseren Überblick über die Daten zu erhalten, legen Sie Attribute fest, um die Gruppengröße anzupassen und die Verhältnisse zu runden
avc_grouped . min_group_ratio = 0.05
avc_grouped . min_subgroup_count = 5
avc_grouped . round_ratio = 3
avc_grouped . avc_df| zählen | subgroup_ratio | subgr_r_diff_subgr_all | r_vs_total | ||
|---|---|---|---|---|---|
| Gehäuse | Titel | ||||
| B | Vermissen. | 14 | 0,298 | 0,094 | 0,016 |
| Herr. | 16 | 0,340 | -0.240 | 0,018 | |
| Frau | 10 | 0,213 | 0,073 | 0,011 | |
| _n / A | 1 | 0,021 | 0,013 | 0,001 | |
| _andere | 6 | 0,127 | 0,111 | 0,007 | |
| _gesamt | 47 | 1.000 | 0,000 | 0,053 | |
| C | Vermissen. | 12 | 0,203 | -0.001 | 0,013 |
| Herr. | 29 | 0,492 | -0.088 | 0,033 | |
| Frau | 14 | 0,237 | 0,097 | 0,016 | |
| _n / A | 1 | 0,017 | 0,009 | 0,001 | |
| _andere | 3 | 0,051 | 0,035 | 0,003 | |
| _gesamt | 59 | 1.000 | 0,000 | 0,066 | |
| _alle | Master. | 40 | 0,045 | Nan | 0,045 |
| Vermissen. | 182 | 0,204 | Nan | 0,204 | |
| Herr. | 517 | 0,580 | Nan | 0,580 | |
| Frau | 125 | 0,140 | Nan | 0,140 | |
| Rev. | 6 | 0,007 | Nan | 0,007 | |
| _n / A | 7 | 0,008 | Nan | 0,008 | |
| _andere | 14 | 0,016 | Nan | 0,016 | |
| _gesamt | 891 | 1.000 | Nan | 1.000 | |
| _n / A | Master. | 33 | 0,048 | 0,003 | 0,037 |
| Vermissen. | 135 | 0,197 | -0.007 | 0,152 | |
| Herr. | 424 | 0,617 | 0,037 | 0,476 | |
| Frau | 81 | 0,118 | -0.022 | 0,091 | |
| Rev. | 6 | 0,009 | 0,002 | 0,007 | |
| _n / A | 4 | 0,006 | -0.002 | 0,004 | |
| _andere | 4 | 0,006 | -0.010 | 0,004 | |
| _gesamt | 687 | 1.000 | 0,000 | 0,771 | |
| _andere | Master. | 5 | 0,051 | 0,006 | 0,006 |
| Vermissen. | 21 | 0,214 | 0.010 | 0,024 | |
| Herr. | 48 | 0,490 | -0.090 | 0,054 | |
| Frau | 20 | 0,204 | 0,064 | 0,022 | |
| _n / A | 1 | 0.010 | 0,002 | 0,001 | |
| _andere | 3 | 0,031 | 0,015 | 0,003 | |
| _gesamt | 98 | 1.000 | 0,000 | 0,110 |
Parameter der AdvancedValueCounts -Klasse, um Gruppen in einem gruppy-by AdvancedValueCounts anzupassen
# for groupby_col:
dropna : bool = False
max_groups : int = None # does not effect NA or the '_other' group
min_group_count : int = 1 # does not effect NA or the '_other' group
min_group_ratio : float = 0 # does not effect NA or the '_other' group
# for column:
dropna : bool = False
max_subgroups : int = None # does not effect NA or the '_other' group
min_subgroup_count : int = 1 # does not effect NA or the '_other' group
min_subgroup_ratio : float = 0 # does not effect NA or the '_other' group
min_subgroup_ratio_vs_total : float = 0 # does not effect NA or the '_other' group Um eine Handlung der AdvancedValueCounts.avc_df zu erhalten.AVC_DF:
avc_grouped . get_plot ( normalize = True ) # normalize = True is default value 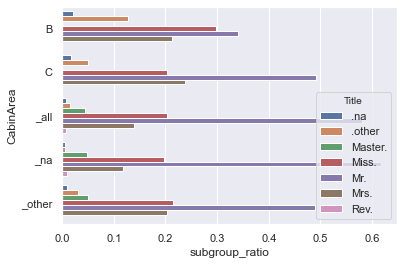
Um einen Datenrahmen ohne die summary_statistics wie '_all' und '_total' zu erhalten:
avc_grouped . unsummerized_df| zählen | subgroup_ratio | subgr_r_diff_subgr_all | r_vs_total | ||
|---|---|---|---|---|---|
| Gehäuse | Titel | ||||
| B | Vermissen. | 14 | 0,298 | 0,094 | 0,016 |
| Herr. | 16 | 0,340 | -0.240 | 0,018 | |
| Frau | 10 | 0,213 | 0,073 | 0,011 | |
| _n / A | 1 | 0,021 | 0,013 | 0,001 | |
| _andere | 6 | 0,127 | 0,111 | 0,007 | |
| C | Vermissen. | 12 | 0,203 | -0.001 | 0,013 |
| Herr. | 29 | 0,492 | -0.088 | 0,033 | |
| Frau | 14 | 0,237 | 0,097 | 0,016 | |
| _n / A | 1 | 0,017 | 0,009 | 0,001 | |
| _andere | 3 | 0,051 | 0,035 | 0,003 | |
| _n / A | Master. | 33 | 0,048 | 0,003 | 0,037 |
| Vermissen. | 135 | 0,197 | -0.007 | 0,152 | |
| Herr. | 424 | 0,617 | 0,037 | 0,476 | |
| Frau | 81 | 0,118 | -0.022 | 0,091 | |
| Rev. | 6 | 0,009 | 0,002 | 0,007 | |
| _n / A | 4 | 0,006 | -0.002 | 0,004 | |
| _andere | 4 | 0,006 | -0.010 | 0,004 | |
| _andere | Master. | 5 | 0,051 | 0,006 | 0,006 |
| Vermissen. | 21 | 0,214 | 0.010 | 0,024 | |
| Herr. | 48 | 0,490 | -0.090 | 0,054 | |
| Frau | 20 | 0,204 | 0,064 | 0,022 | |
| _n / A | 1 | 0.010 | 0,002 | 0,001 | |
| _andere | 3 | 0,031 | 0,015 | 0,003 |
git clone https://github.com/sTomerG/advanced-value-counts.git
cd advanced-value-counts
python3 -m venv .venv
Aktivieren Sie die virtuelle Umgebung
Fenster:
..venvScriptsactivate
Linux / macos:
source .venv/bin/activate
Anforderungen installieren
python -m pip install --upgrade pip
pip install -r requirements/requirements.txt
Test, wenn alles richtig funktioniert
( Abschaltungen werden erwartet)
Mit Tox
tox
Ohne Tox
pip install -e .
pytest


