AudioMAE pytorch
1.0.0
이 repo는 듣는 종이 마스크 된 오토 코더의 비공식 구현입니다. Audio-Mae는 먼저 마스킹 비율이 높은 오디오 스펙트로 그램 패치를 인코딩하여 인코더 층을 통해 마스크가없는 토큰 만 공급합니다. 그런 다음 디코더는 입력 스펙트로 그램을 재구성하기 위해 마스크 토큰으로 패딩 된 인코딩 된 컨텍스트를 다시 표시하고 디코딩합니다. 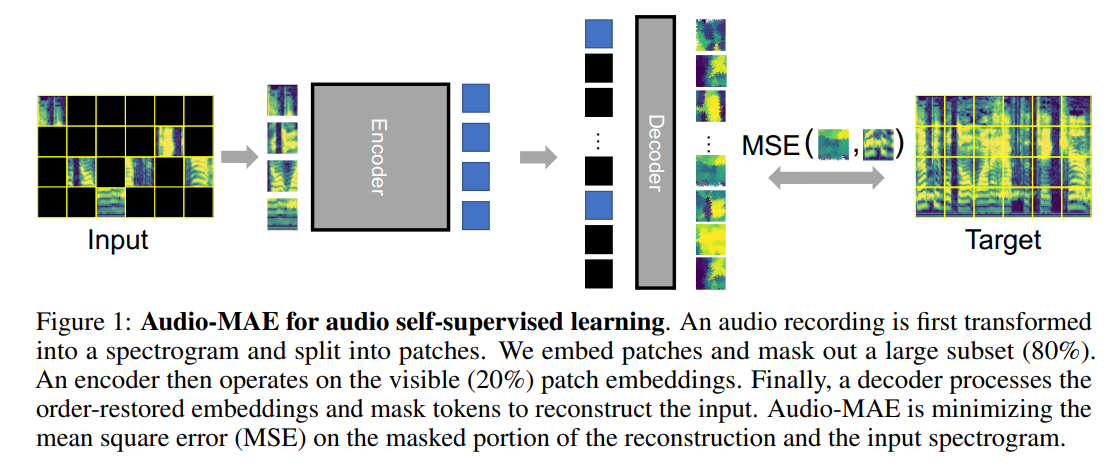
import torch
from audio_mae import AudioMaskedAutoencoderViT
audio_mels = torch . ones ([ 2 , 1 , 1024 , 128 ])
# Paper recommended archs
model = AudioMaskedAutoencoderViT (
num_mels = 128 , mel_len = 1024 , in_chans = 1 ,
patch_size = 16 , embed_dim = 768 , encoder_depth = 12 , num_heads = 12 ,
decoder_embed_dim = 512 , decoder_depth = 16 , decoder_num_heads = 16 ,
mlp_ratio = 4 , norm_layer = partial ( nn . LayerNorm , eps = 1e-6 ))
loss , pred , mask = model ( audio_mels ) @misc{https://doi.org/10.48550/arxiv.2207.06405,
doi = {10.48550/ARXIV.2207.06405},
url = {https://arxiv.org/abs/2207.06405},
author = {Huang, Po-Yao and Xu, Hu and Li, Juncheng and Baevski, Alexei and Auli, Michael and Galuba, Wojciech and Metze, Florian and Feichtenhofer, Christoph},
keywords = {Sound (cs.SD), Artificial Intelligence (cs.AI), Machine Learning (cs.LG), Audio and Speech Processing (eess.AS), FOS: Computer and information sciences, FOS: Computer and information sciences, FOS: Electrical engineering, electronic engineering, information engineering, FOS: Electrical engineering, electronic engineering, information engineering},
title = {Masked Autoencoders that Listen},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
@misc{https://doi.org/10.48550/arxiv.2203.16691,
doi = {10.48550/ARXIV.2203.16691},
url = {https://arxiv.org/abs/2203.16691},
author = {Baade, Alan and Peng, Puyuan and Harwath, David},
keywords = {Audio and Speech Processing (eess.AS), Artificial Intelligence (cs.AI), Computation and Language (cs.CL), Machine Learning (cs.LG), Sound (cs.SD), FOS: Electrical engineering, electronic engineering, information engineering, FOS: Electrical engineering, electronic engineering, information engineering, FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {MAE-AST: Masked Autoencoding Audio Spectrogram Transformer},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}


