Vector Search with FAISS
1.0.0
이 프로젝트는 Custom Index & Kmeans 구현을 통해 임베딩, FAISS 및 제품 정량화를 사용하여 강의 컨텐츠에 대한 효율적인 유사성 검색 시스템을 구현합니다. 이를 통해 텍스트 내용에 따라 유사한 강의를 찾을 수있어 빠른 검색 및 강의 권장 사항이 가능합니다.
저장소를 복제하십시오
git clone https://github.com/bariscamli/Vector-Search-with-FAISS.git
cd Vector-Search-with-FAISS가상 환경 생성 (선택 사항이지만 권장)
python -m venv venv
source venv/bin/activate # On Windows use `venvScriptsactivate`가상 환경 생성 (선택 사항이지만 권장)
pip install -r requirements.txt 강의 데이터 : config.py에서 LECTURE_FILE 이 지정한 파일에 강의 텍스트를 배치하십시오. 각 라인에는 하나의 강의가 포함되어야합니다.
쿼리 데이터 : config.py에서 QUERY_FILE 에 의해 지정된 파일에 쿼리 텍스트를 배치합니다. 각 라인에는 하나의 쿼리가 포함되어야합니다. 강의 형식 .txt :
Introduction to Machine Learning
Advanced Topics in Deep Learning
Statistical Methods in Data Science
...
queries.txt의 예제 형식 :
Basics of Neural Networks
Regression Analysis Techniques
Clustering Algorithms Overview
...
모든 구성은 config.py 파일을 통해 관리됩니다. 주요 매개 변수는 다음과 같습니다.
File Paths
- LECTURE_FILE: Path to the lecture data file.
- QUERY_FILE: Path to the query data file.
Embedding Model
- EMBEDDING_MODEL_NAME: Name or path of the embedding model to use.
- BATCH_SIZE: Batch size for computing embeddings.
FAISS Parameters
- FAISS_EFSEARCH_VALUES: List of efSearch values for performance evaluation.
Quantization Parameters
- PQ_M: Number of sub-vector quantizers.
- PQ_NBITS: Number of bits per sub-vector.
- KMEANS_MAX_ITER: Maximum iterations for k-means during PQ training.
전체 파이프 라인을 실행하려면 기본 스크립트를 실행하십시오.
python main.py데이터로드 및 전처리
임베딩 계산
EMBEDDING_MODEL_NAME 에 따라로드됩니다.기준 계산
FAISS 지수 구축 및 평가
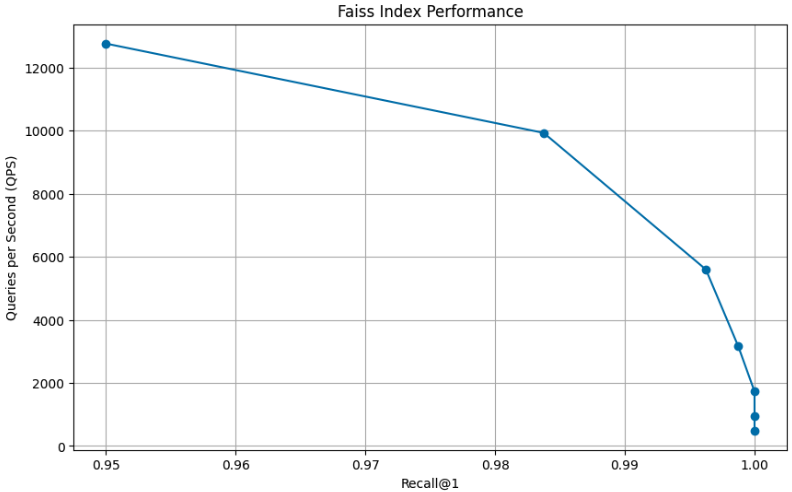
efSearch 값에 대해 평가됩니다.성능 시각화
양자화
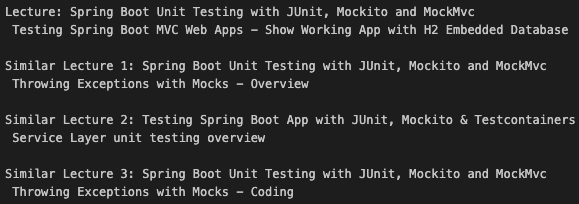
CustomIndexPQ )가 작성됩니다.예제 검색
numpymatplotlibfaiss (GPU가있는 경우 pip install faiss-cpu 또는 faiss-gpu 를 통해 설치)loggingtransformers ) 

