Vector Search with FAISS
1.0.0
このプロジェクトは、カスタムインデックスとKmeansの実装を使用した埋め込み、FAISS、および製品の量子化を使用して、講義コンテンツの効率的な類似性検索システムを実装しています。これにより、テキストコンテンツに基づいて同様の講義を見つけることができ、迅速な検索と講義の推奨を可能にします。
リポジトリをクローンします
git clone https://github.com/bariscamli/Vector-Search-with-FAISS.git
cd Vector-Search-with-FAISS仮想環境を作成します(オプションですが推奨)
python -m venv venv
source venv/bin/activate # On Windows use `venvScriptsactivate`仮想環境を作成します(オプションですが推奨)
pip install -r requirements.txt講義データ: LECTURE_FILEがconfig.pyで指定したファイルに講義テキストを配置します。各行には1つの講義が含まれている必要があります。
クエリデータ:config.pyのQUERY_FILEで指定されたファイルにクエリテキストを配置します。各行には1つのクエリが含まれている必要があります。 lectures.txtの例の形式:
Introduction to Machine Learning
Advanced Topics in Deep Learning
Statistical Methods in Data Science
...
queries.txtの例の形式:
Basics of Neural Networks
Regression Analysis Techniques
Clustering Algorithms Overview
...
すべての構成は、config.pyファイルを介して管理されます。重要なパラメーターは次のとおりです。
File Paths
- LECTURE_FILE: Path to the lecture data file.
- QUERY_FILE: Path to the query data file.
Embedding Model
- EMBEDDING_MODEL_NAME: Name or path of the embedding model to use.
- BATCH_SIZE: Batch size for computing embeddings.
FAISS Parameters
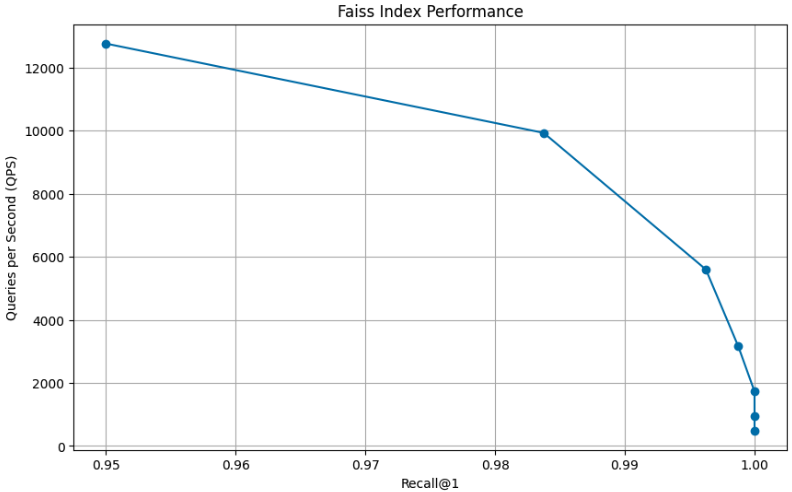
- FAISS_EFSEARCH_VALUES: List of efSearch values for performance evaluation.
Quantization Parameters
- PQ_M: Number of sub-vector quantizers.
- PQ_NBITS: Number of bits per sub-vector.
- KMEANS_MAX_ITER: Maximum iterations for k-means during PQ training.
メインスクリプトを実行して、完全なパイプラインを実行します。
python main.pyデータの読み込みと前処理
埋め込み計算
EMBEDDING_MODEL_NAMEに従ってロードされます。ベースライン計算
FAISSインデックスの構築と評価
efSearch値に対して評価されます。パフォーマンスの視覚化
量子化
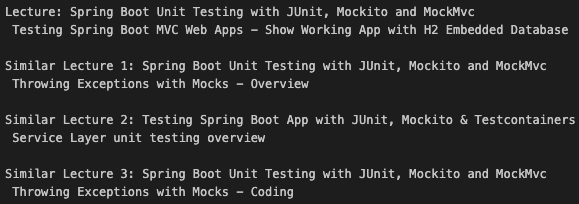
CustomIndexPQ )が作成されます。検索の例
numpymatplotlibfaiss (GPUをお持ちの場合は、 pip install faiss-cpuまたはfaiss-gpuをインストールしてください)loggingtransformers ) 

