semester search
1.0.0
학기 검색은 다운로드 가능한 클래스 자료를 통해 빠르게 검색하기위한 유틸리티로, 더 많은 시간을 배우고 교수 웹 사이트의 수십 개의 링크를 클릭하는 데 더 많은 시간을 할애 할 수 있습니다.
./documents 에서 디렉토리를 작성하여 문서를 배치하십시오.main.go 실행하십시오 문서 (PDF, PPTX 및 Doc으로 테스트 된)를 documents 디렉토리에 배치 한 후에는 검색 유틸리티를 마지막으로 열었을 때부터 새로운 문서를 언급하면서 프로그램을 스캔합니다.
새 문서를 추가하지 않은 경우 엔진은 캐시 된 버전의 (구문 분석 된) 문서를 사용하여 검색을 수행합니다.
마지막 검색 이후 문서를 추가하거나 제거한 경우 엔진은 문서를 다시 구사합니다. Tika 서버를 시작하여 설치하지 않은 경우 다운로드 포함 한 다음 각 문서를 서비스에 공급하여이를 수행합니다. 서버는 문서 본문에 응답 한 다음 검색하도록 저장됩니다.
문서를 메모리 (캐시 또는 구문 분석을 통해)에로드 한 후 엔진은 컨텐츠에서 전체 텍스트 검색 색인을 만듭니다. 이 색인을 사용하여 사용자는 원하는 내용이 포함 된 문서를 찾을 수 있습니다. 이 시점의 결과는 문서 당 HITS로 정렬됩니다.
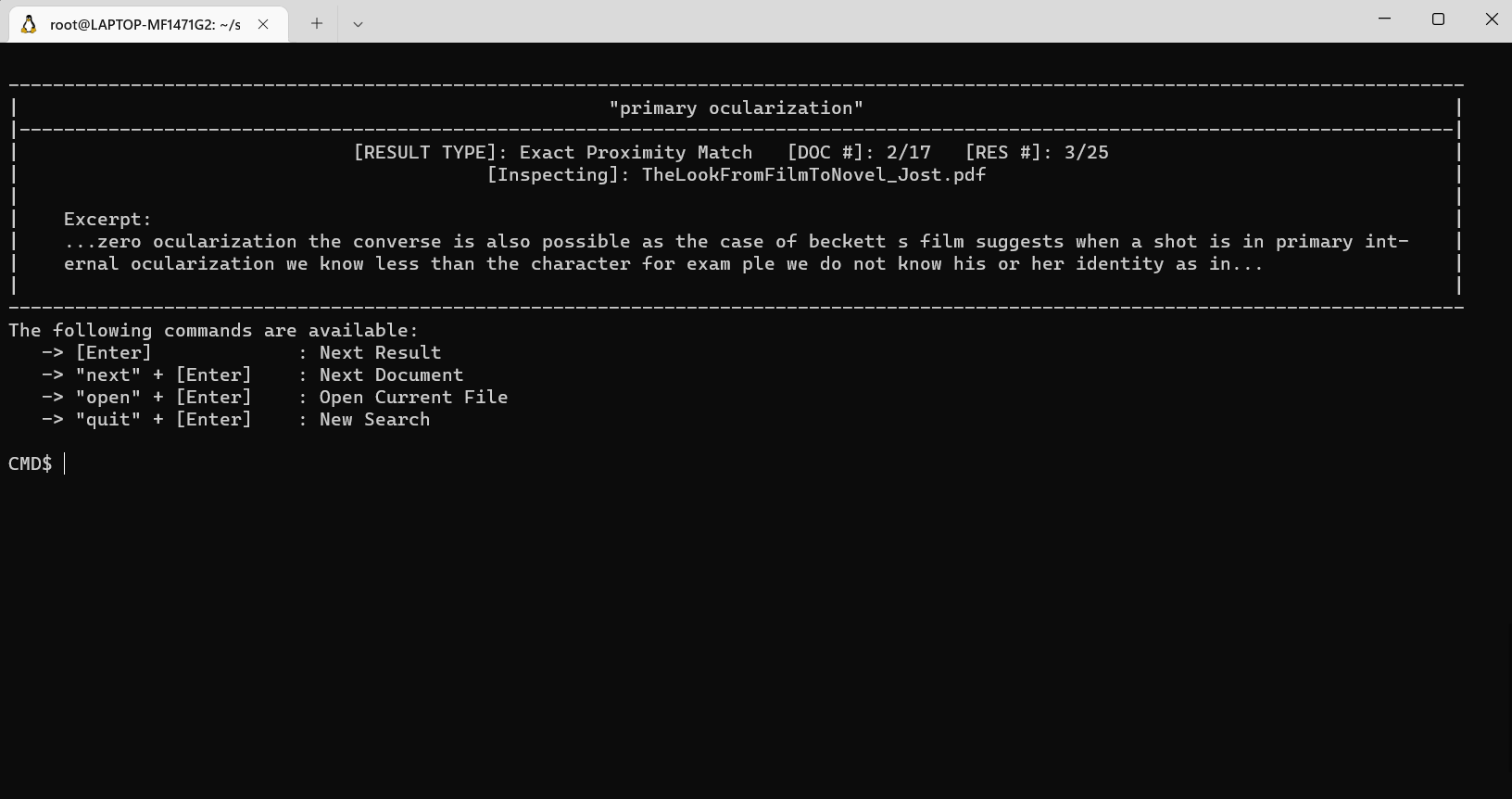
더 깊이 다루려면 각 문서에서 추가 텍스트 검색이 수행되어 올바른 문서를보고 있는지 확인할 수있는 특정 발췌문을 얻을 수 있습니다. 이 문서 구체적인 검색 방법에는 정확한 문구 일치, 줄기가있는 문구 일치, 검색어 근접 일치 및 느슨한 용어 일치가 포함됩니다.
올바른 문서를 발견하고 (발췌 한 내용 만 볼 수 있으면 불충분) 전용 키보드 단축키를 사용하여 좋아하는 문서 뷰어에서 열 수 있습니다.
참고 :이 프로젝트는 Tika 문서 구문 분석 서버가 이에 달려 있으므로 Java가 실행해야합니다.


