semester search
1.0.0
学期検索は、ダウンロード可能なクラス資料をすばやく検索するためのユーティリティであり、教授のウェブサイトで数十のリンクをクリックする時間を増やすことができます。
./documentsにディレクトリを作成して、ドキュメントを配置しますmain.goを実行しますドキュメント(これまでにPDF、PPTX、およびDOCでテストされた)をdocumentsディレクトリに配置した後、プログラムはそれらをスキャンし、検索ユーティリティを最後に開いたときから新しいドキュメントに注目します。
新しいドキュメントを追加していない場合、エンジンは(解析された)ドキュメントのキャッシュバージョンを使用して検索を実行します。
前回の検索以来ドキュメントを追加または削除した場合、エンジンはドキュメントを再インデックスします。これは、Tikaサーバーを起動し(インストールしていない場合はダウンロードすることを含む)、各ドキュメントをサービスに供給することで行います。サーバーはドキュメントの本体で応答し、検索するために保存されます。
ドキュメントをメモリにロードした後(キャッシュまたは解析による)、エンジンはコンテンツから全文検索インデックスを作成します。このインデックスを使用して、ユーザーは探しているものを含むドキュメントを検索することができます。この時点での結果は、ドキュメントごとのヒットによってソートされます。
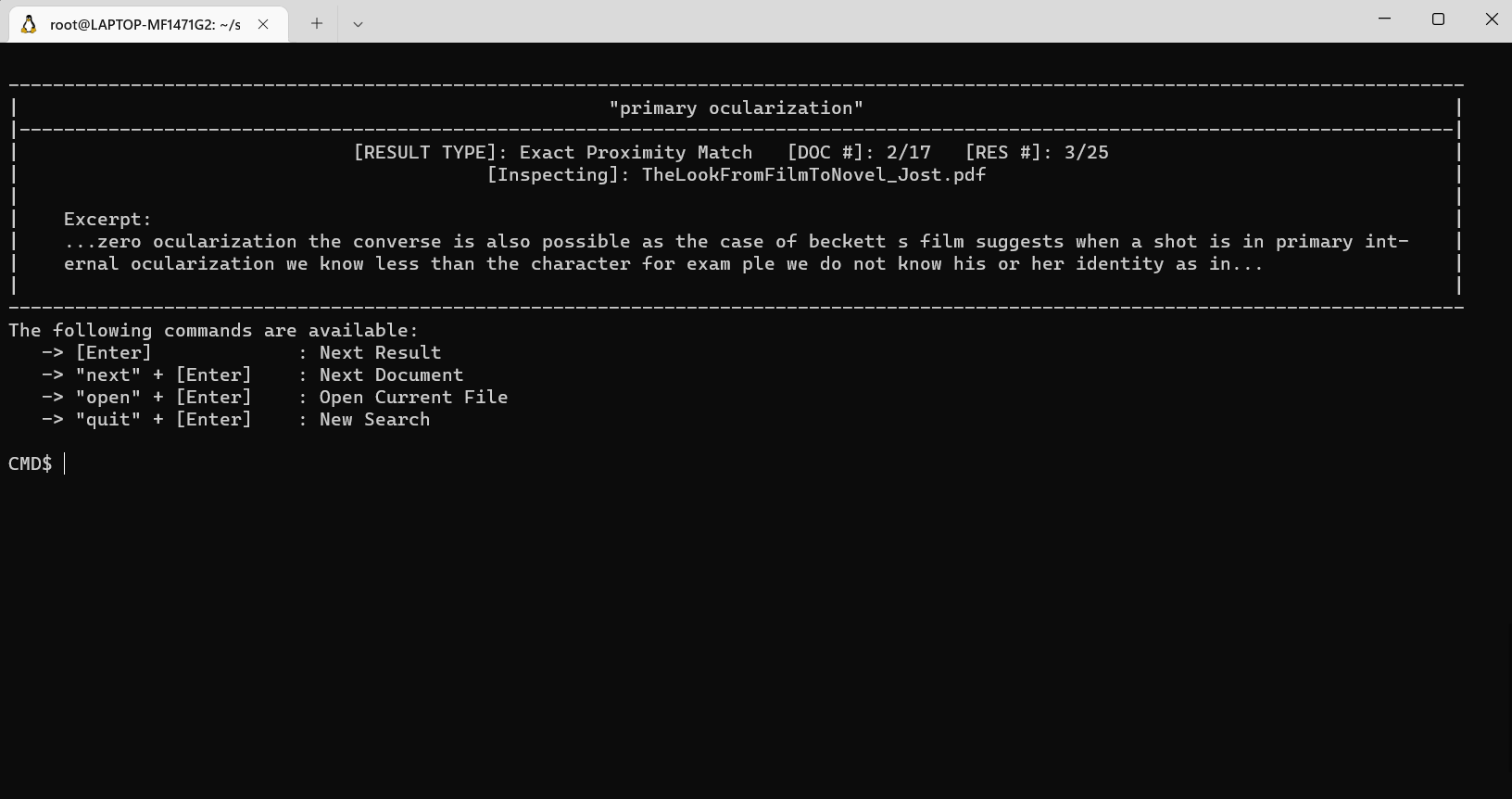
より深く潜るために、各ドキュメントでさらにテキスト検索が実行され、特定の抜粋を取得して、正しいドキュメントを確認していることを確認できる特定の抜粋を取得します。これらのドキュメント固有の検索方法には、正確なフレーズマッチング、茎のあるフレーズのマッチング、検索用語の近接マッチング、およびゆるい用語のマッチングが含まれます。
正しいドキュメントを見つけたとき(そして、抜粋だけを表示するのが不十分です)、専用のキーボードショートカットを使用してお気に入りのドキュメントビューアーで開くことができます。
注:Tikaドキュメントの解析サーバーはそれに依存しているため、このプロジェクトではJavaを実行する必要があります


