lstm char cnn tensorflow
1.0.0
문자 인식 신경 언어 모델의 텐서 플로 구현. 저자의 원래 코드는 여기에서 찾을 수 있습니다.
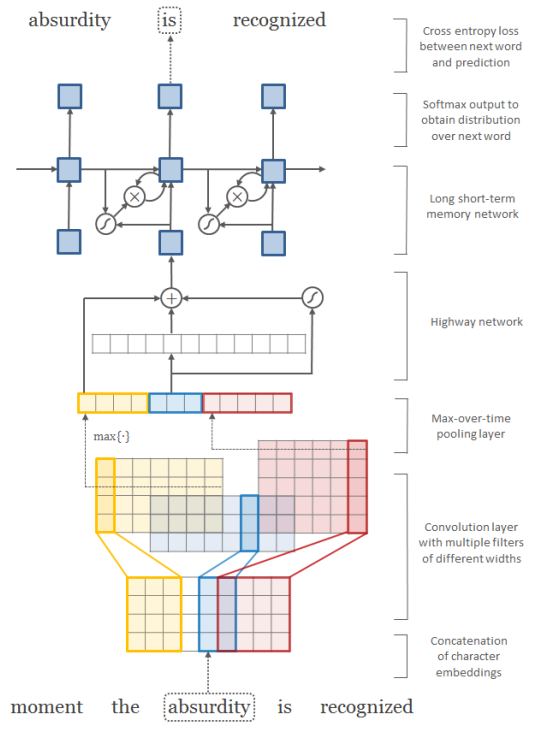
이 구현에는 다음이 포함됩니다.
현재 구현에는 성능 문제가 있습니다. #3 참조.
ptb 데이터 세트로 모델을 훈련하려면 :
$ python main.py --dataset ptb
기존 모델을 테스트하려면 :
$ python main.py --dataset ptb --forward_only True
모든 교육 옵션을 보려면 실행하십시오.
$ python main.py --help
인쇄 할 것입니다
usage: main.py [-h] [--epoch EPOCH] [--word_embed_dim WORD_EMBED_DIM]
[--char_embed_dim CHAR_EMBED_DIM]
[--max_word_length MAX_WORD_LENGTH] [--batch_size BATCH_SIZE]
[--seq_length SEQ_LENGTH] [--learning_rate LEARNING_RATE]
[--decay DECAY] [--dropout_prob DROPOUT_PROB]
[--feature_maps FEATURE_MAPS] [--kernels KERNELS]
[--model MODEL] [--data_dir DATA_DIR] [--dataset DATASET]
[--checkpoint_dir CHECKPOINT_DIR]
[--forward_only [FORWARD_ONLY]] [--noforward_only]
[--use_char [USE_CHAR]] [--nouse_char] [--use_word [USE_WORD]]
[--nouse_word]
optional arguments:
-h, --help show this help message and exit
--epoch EPOCH Epoch to train [25]
--word_embed_dim WORD_EMBED_DIM
The dimension of word embedding matrix [650]
--char_embed_dim CHAR_EMBED_DIM
The dimension of char embedding matrix [15]
--max_word_length MAX_WORD_LENGTH
The maximum length of word [65]
--batch_size BATCH_SIZE
The size of batch images [100]
--seq_length SEQ_LENGTH
The # of timesteps to unroll for [35]
--learning_rate LEARNING_RATE
Learning rate [1.0]
--decay DECAY Decay of SGD [0.5]
--dropout_prob DROPOUT_PROB
Probability of dropout layer [0.5]
--feature_maps FEATURE_MAPS
The # of feature maps in CNN
[50,100,150,200,200,200,200]
--kernels KERNELS The width of CNN kernels [1,2,3,4,5,6,7]
--model MODEL The type of model to train and test [LSTM, LSTMTDNN]
--data_dir DATA_DIR The name of data directory [data]
--dataset DATASET The name of dataset [ptb]
--checkpoint_dir CHECKPOINT_DIR
Directory name to save the checkpoints [checkpoint]
--forward_only [FORWARD_ONLY]
True for forward only, False for training [False]
--noforward_only
--use_char [USE_CHAR]
Use character-level language model [True]
--nouse_char
--use_word [USE_WORD]
Use word-level language [False]
--nouse_word
그러나 모델/lstmtdnn 및 Models/Tdnn에서 더 많은 옵션을 찾을 수 있습니다.
종이 결과를 재현하지 못했습니다 (2016.02.12) . 논문의 결과를 재현 한 코드를 찾고 있다면 https://github.com/mkroutikov/tf-lstm-char-cnn을 참조하십시오.
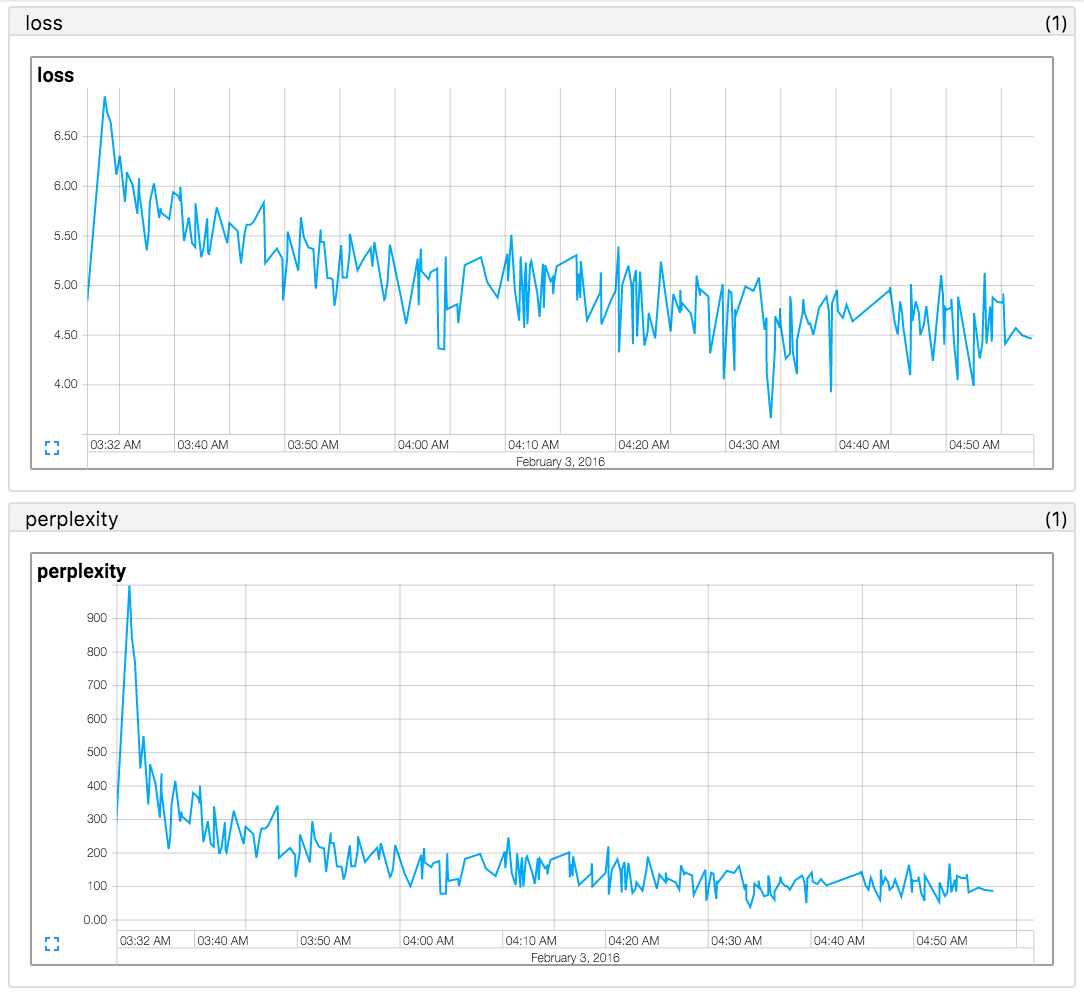
Penn TreeBank (PTB) Corpora의 테스트 세트에 대한 당황.
| 이름 | 캐릭터 임베드 | LSTM 숨겨진 장치 | 종이 (y kim 2016) | 이 repo. |
|---|---|---|---|---|
| lstm-char-small | 15 | 100 | 92.3 | 진행 중 |
| LSTM-char-large | 15 | 150 | 78.9 | 진행 중 |
Taehoon kim / @carpedm20


