lstm char cnn tensorflow
1.0.0
Mise en œuvre de TensorFlow des modèles de langage neuronal conscient des caractères. Le code d'origine de l'auteur peut être trouvé ici.
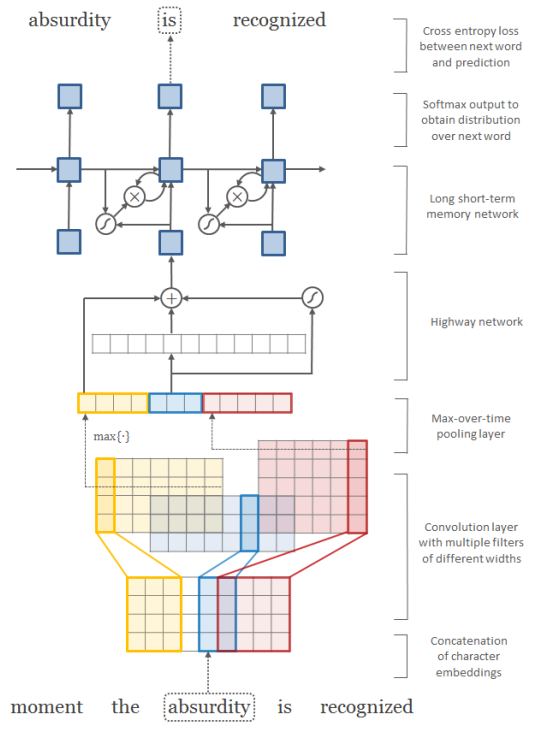
Cette implémentation contient:
L'implémentation actuelle a un problème de performance. Voir # 3.
Pour former un modèle avec un ensemble de données ptb :
$ python main.py --dataset ptb
Pour tester un modèle existant:
$ python main.py --dataset ptb --forward_only True
Pour voir toutes les options de formation, exécutez:
$ python main.py --help
qui imprimera
usage: main.py [-h] [--epoch EPOCH] [--word_embed_dim WORD_EMBED_DIM]
[--char_embed_dim CHAR_EMBED_DIM]
[--max_word_length MAX_WORD_LENGTH] [--batch_size BATCH_SIZE]
[--seq_length SEQ_LENGTH] [--learning_rate LEARNING_RATE]
[--decay DECAY] [--dropout_prob DROPOUT_PROB]
[--feature_maps FEATURE_MAPS] [--kernels KERNELS]
[--model MODEL] [--data_dir DATA_DIR] [--dataset DATASET]
[--checkpoint_dir CHECKPOINT_DIR]
[--forward_only [FORWARD_ONLY]] [--noforward_only]
[--use_char [USE_CHAR]] [--nouse_char] [--use_word [USE_WORD]]
[--nouse_word]
optional arguments:
-h, --help show this help message and exit
--epoch EPOCH Epoch to train [25]
--word_embed_dim WORD_EMBED_DIM
The dimension of word embedding matrix [650]
--char_embed_dim CHAR_EMBED_DIM
The dimension of char embedding matrix [15]
--max_word_length MAX_WORD_LENGTH
The maximum length of word [65]
--batch_size BATCH_SIZE
The size of batch images [100]
--seq_length SEQ_LENGTH
The # of timesteps to unroll for [35]
--learning_rate LEARNING_RATE
Learning rate [1.0]
--decay DECAY Decay of SGD [0.5]
--dropout_prob DROPOUT_PROB
Probability of dropout layer [0.5]
--feature_maps FEATURE_MAPS
The # of feature maps in CNN
[50,100,150,200,200,200,200]
--kernels KERNELS The width of CNN kernels [1,2,3,4,5,6,7]
--model MODEL The type of model to train and test [LSTM, LSTMTDNN]
--data_dir DATA_DIR The name of data directory [data]
--dataset DATASET The name of dataset [ptb]
--checkpoint_dir CHECKPOINT_DIR
Directory name to save the checkpoints [checkpoint]
--forward_only [FORWARD_ONLY]
True for forward only, False for training [False]
--noforward_only
--use_char [USE_CHAR]
Use character-level language model [True]
--nouse_char
--use_word [USE_WORD]
Use word-level language [False]
--nouse_word
Mais d'autres options peuvent être trouvées dans les modèles / lstmtdnn et les modèles / TDNN.
N'a pas réussi à reproduire les résultats du papier (2016.02.12) . Si vous recherchez un code qui reproduit le résultat du papier, consultez https://github.com/mkroutikov/tf-lstm-char-cnn.
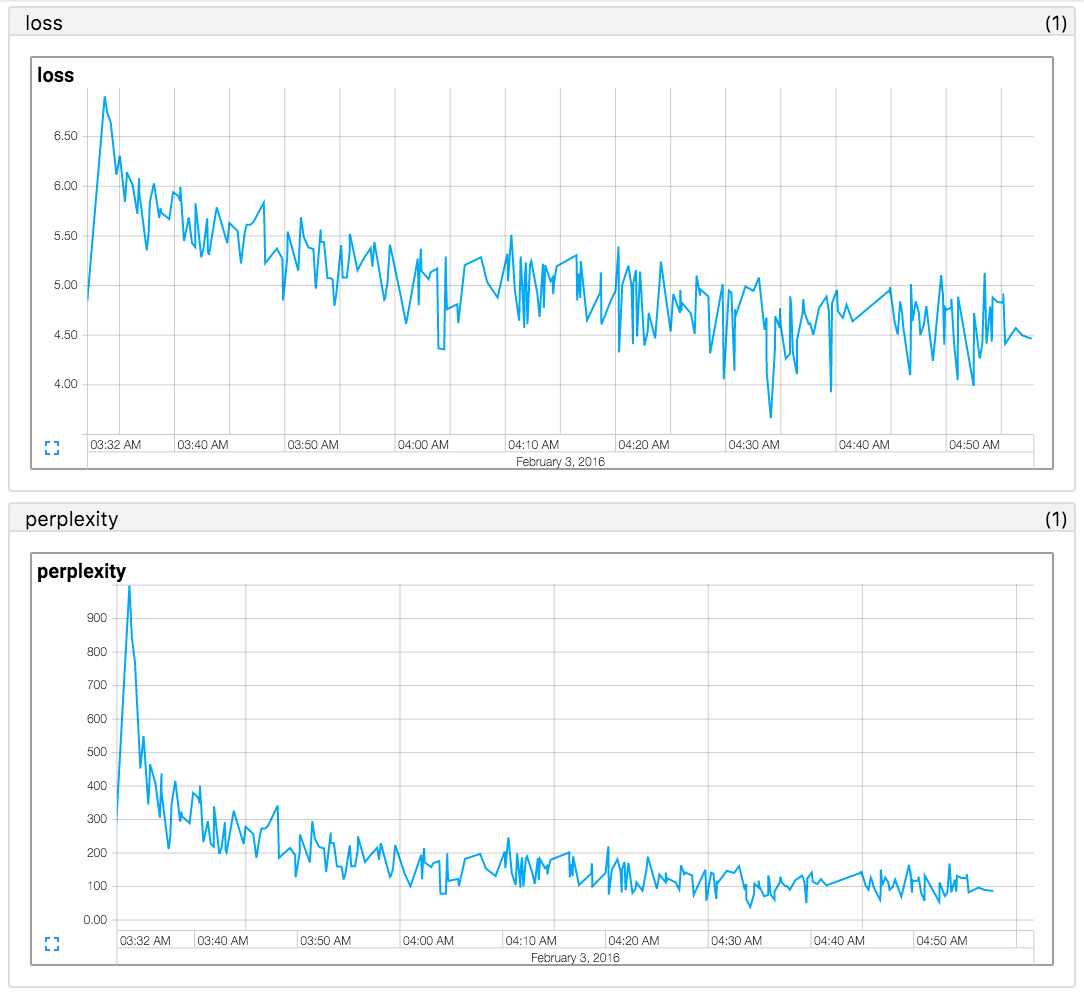
La perplexité sur les ensembles de tests des corpus de Penn Treebank (PTB).
| Nom | Incorporer le caractère | LSTM Unités cachées | Paper (Y Kim 2016) | Ce repo. |
|---|---|---|---|---|
| LSTM-Char-Small | 15 | 100 | 92.3 | en cours |
| LSTM-Char-Garg | 15 | 150 | 78.9 | en cours |
Taehoon Kim / @ CARPEDM20


