Intelligent_Document_Finder
1.0.0
시맨틱 검색을 사용하여 모든 문서를 찾을 수있는 도구.
이것은 지능형 문서 파인더의 즉흥적 인 버전입니다
새로운 기능 목록-
작년에 만든 문서의 정확한 위치를 기억하는 것이 얼마나 쉽습니까? 쉽지 않습니까? 대기업/사람들은 매일 수백 개의 문서를 다루고 대부분의 시간을 잊어 버립니다.
그러나 우리가 어떤 작업에 대해 오래된 문서를 다시 원한다면, 불행히도 컴퓨터의 큰 저장소에서 그것을 검색하기 위해 해당 문서의 이름이나 실제 내용을 기억하지 못합니다.
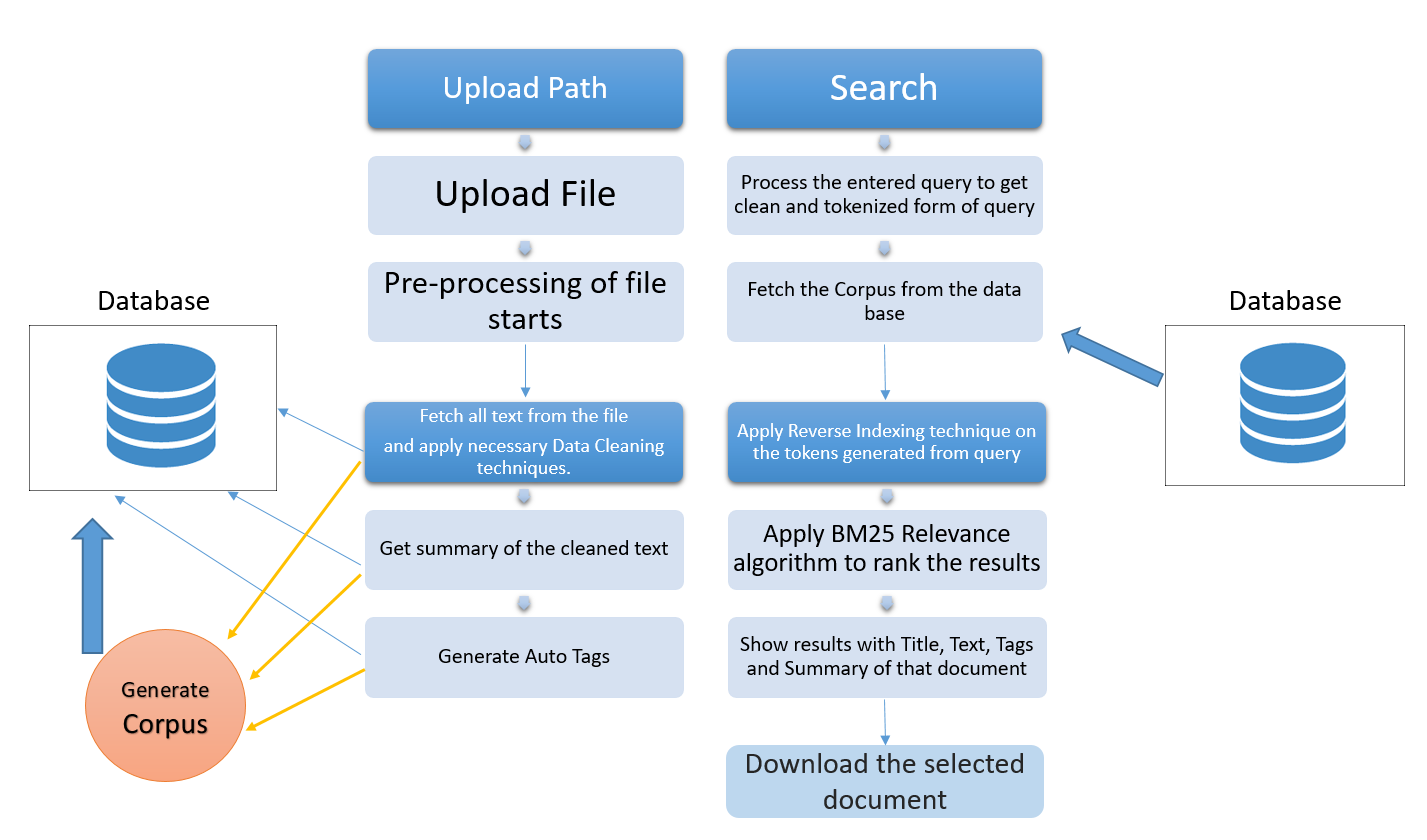
이러한 경우 지능형 문서 파인더를 사용하면 실제로 큰 차이가 생길 수 있습니다. 쿼리 입력을 semantically 으로 필요에 대한 문서를 검색 할 수 있습니다. 이것은 문서에 대한 빠른 액세스에 도움이 될뿐만 아니라 유사한 문서를 함께 그룹화하고 분석하는 데 도움이됩니다.
시청 프로젝트 데모 :
현재이 저장소는 Web Scraping에서 수집 한 미리 정의 된 뉴스 기사 데이터베이스를 사용하고 있습니다. 대형 파일 업로드에 대한 GitHub 제한으로 인해 여기에서 업로드 할 수 없습니다.
곧 동적 데이터베이스의 지원을 추가하여 자체 데이터베이스 에이 도구를 사용하여 고유 한 사용자 정의 검색 엔진을 구축 할 수 있습니다.
Python3.6 JavaScript jQuery HTML & CSS
> mkdir IntelligentDocumentFinder
> cd IntelligentDocumentFinder
> git clone https://github.com/Sarthakjain1206/Intelligent_Document_Finder_2.0.git
설치되지 않은 경우 유리체 환경을 설치하십시오
> python3 -m pip install --user virtualenv> py -m pip install --user virtualenv가상 환경을 만듭니다
> python3 -m venv env> py -m venv env환경 활성화 :
> source env/bin/activate 에서> .envScriptsactivate > pip install -r requirements.txt
이 링크에서 글러브 단어 임베딩을 다운로드하고 , 압축을 제거하고 glove.6B.100d 복사하십시오 .6B.100D 파일 DataBase 폴더에서.
그런 다음이 명령 > python initial_file.py 를 통해 initial_file.py를 실행하십시오
이제 당신은 갈 수 있습니다.
> python src/app.py
linkedln 프로필에서 우리와 연락 할 수 있습니다.
Sarthak Jain Machine Learning NLP Web Crawling
Github에서 나를 팔로우하여 최신 프로젝트에 대한 업데이트를 계속할 수 있습니다.
Rishabh Mishra Full Stack Web Developer
Github에서 나를 팔로우하여 최신 프로젝트에 대한 업데이트를 계속할 수 있습니다.
이 저장소가 마음에 들었다면 별 을 줘서 지원하십시오.
이 도구에 추가 할 수있는 많은 기능이 있습니다.
이러한 기능을 구현 한 경험이 있으시면 기여를 하십시오.
Wikipedia에서 BM25 순위 알고리즘의 awsome 기사 -Okapi BM25
주제 모델링 에서이 기사를 읽으십시오
이 프로젝트에 대한 태그를 생성하기위한 SVOS 태그에 대한이 아름다운 기사를 완전히 따랐습니다.
dorianbrown 의 Github에 대한이 위대한 저장소에서 BM25 Ranking Futuction 구현을 사용했습니다.


