Intelligent_Document_Finder
1.0.0
セマンティック検索を使用してドキュメントを見つけることができるツール。
これは、Intelligent-Document-Finderの即興版です
新機能のリスト -
昨年作成したドキュメントの正確な場所を覚えているのはどれほど簡単ですか?それほど簡単ではありませんよね?大規模な組織/人々は毎日何百もの文書を扱っており、ほとんどの場合、それらを忘れています。
しかし、いくつかの作業のためにその古いドキュメントをもう一度望んでいるが、残念ながら、そのドキュメントの名前や実際のコンテンツを覚えていない場合は、コンピューターの大規模なストレージから取得します。
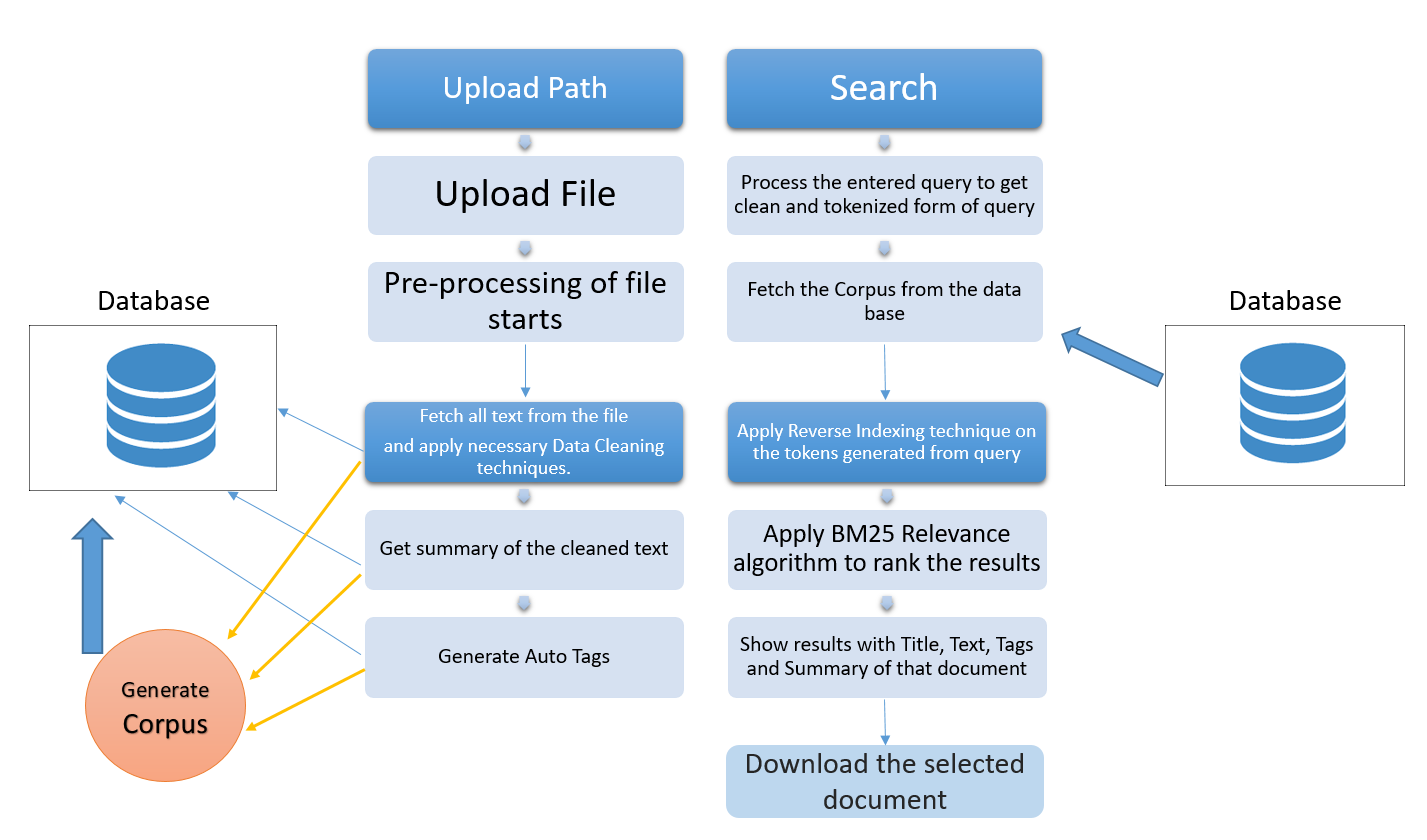
そのような場合、インテリジェントなドキュメントファインダーを使用すると、本当に大きな違いが生じる可能性があります。として、クエリ入力に基づいて、必要性のドキュメントを( semantically )検索できます。これは、ドキュメントへのより速いアクセスに役立つだけでなく、同様のドキュメントをグループ化して分析するのにも役立ちます。
プロジェクトのデモを見る:
現在、このリポジトリは、Webスクレイピングによって収集されたニュース記事の事前定義されたデータベースを使用しています。大きなファイルのアップロードに関するGitHubの制限により、ここにアップロードすることはできません。
まもなく、動的データベースのサポートを追加して、独自のデータベースにこのツールを使用して独自のカスタム検索エンジンを構築できるようにします。
Python3.6 JavaScript jQuery HTML & CSS
> mkdir IntelligentDocumentFinder
> cd IntelligentDocumentFinder
> git clone https://github.com/Sarthakjain1206/Intelligent_Document_Finder_2.0.git
インストールされていない場合は、vitual環境をインストールしてください
> python3 -m pip install --user virtualenv> py -m pip install --user virtualenv仮想環境を作成します
> python3 -m venv env> py -m venv env環境をアクティブにする:
> source env/bin/activate> .envScriptsactivate > pip install -r requirements.txt
このリンクからグローブワードの埋め込みをダウンロードし、それを減圧してglove.6B.100dをコピーします。6B.100D DataBaseフォルダーに
次に、このコマンド> python initial_file.pyを介してinitial_file.pyを実行します
今、あなたは行きます..あなたがそれにアクセスするたびにこのコマンドを入力し、Chrome/Firefoxでウェブサイトを開きます> python src/app.py
Linkedlnプロファイルで私たちと連絡を取ることができます
Sarthak Jain Machine Learning NLP Web Crawling
GitHubで私をフォローして、私の最新のプロジェクトについて最新の状態を維持することもできます
Rishabh Mishra Full Stack Web Developer
GitHubで私をフォローして、私の最新のプロジェクトについて最新の状態を維持することもできます
このリポジトリが気に入ったら、スターを与えることでサポートしてください
このツールに追加できる機能がたくさんあります。
これらの機能のいずれかを実装した経験がある場合は、貢献してください。
ウィキペディアのBM25ランキングアルゴリズムの素晴らしい記事-OkapiBM25
トピックモデリングに関するこの記事を読んでください
このプロジェクトのタグを生成するためのSVOSタグ付けに関するこの美しい記事に完全に従いました。
dorianbrownによるGitHubのこの素晴らしい包装版からのBM25ランキングFuctionの実装を使用しました。


