huxley pdf
1.0.0
あなたの個人的なPDFドキュメントとチャットします。

ファイルごとのこの流線アプリのハイレベルの概要。
ここをクリックして、インストール手順をスキップしてください
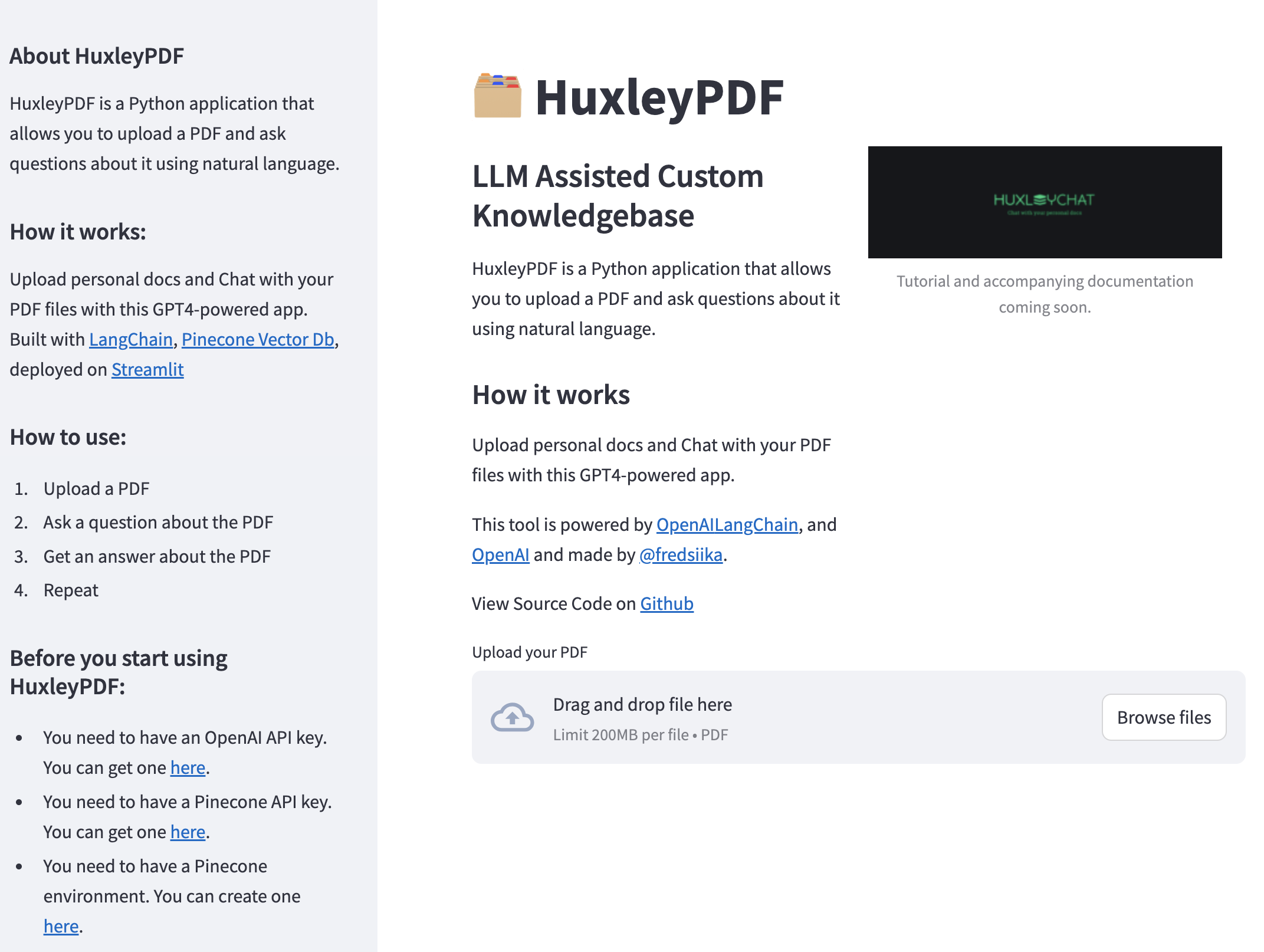
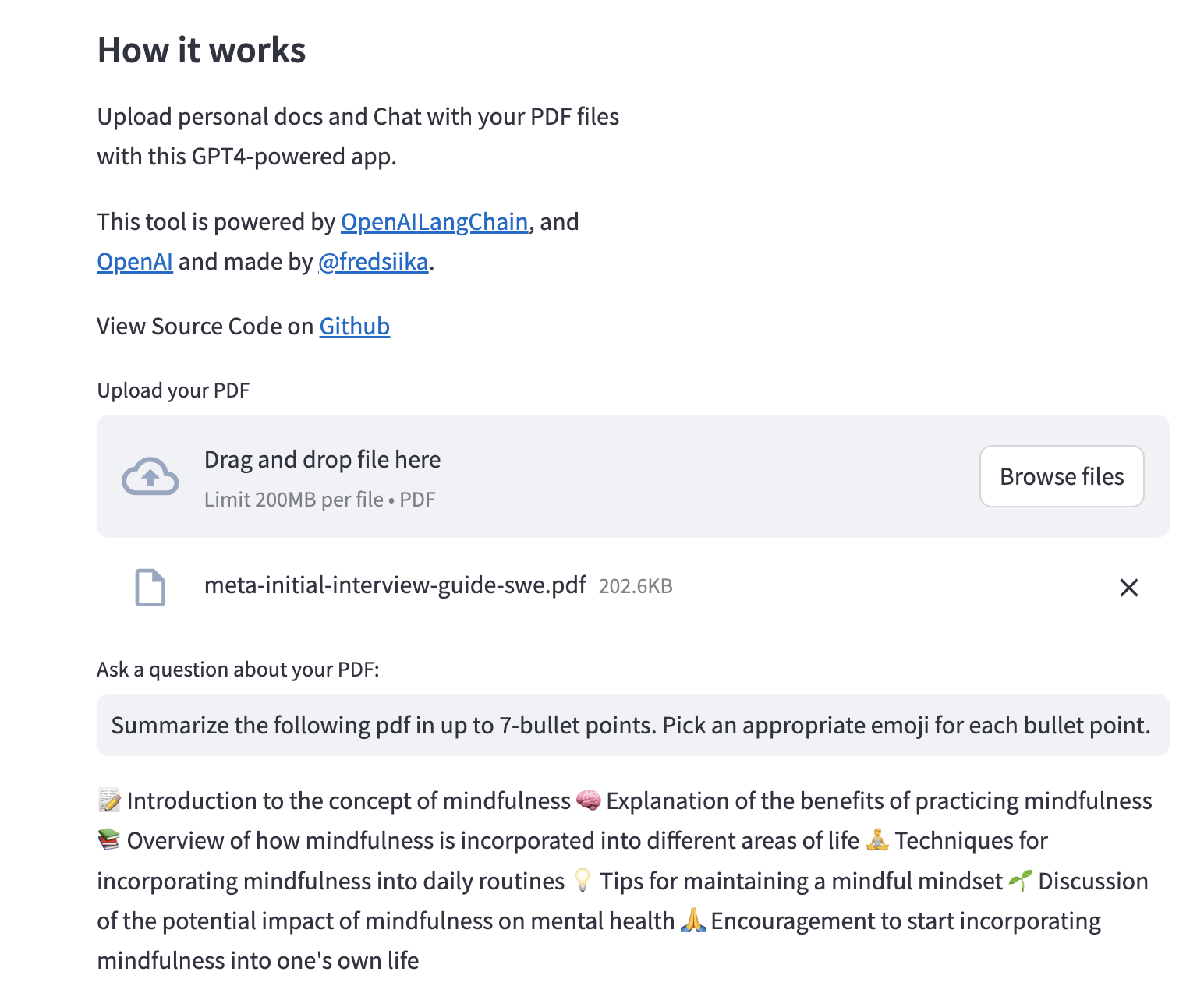
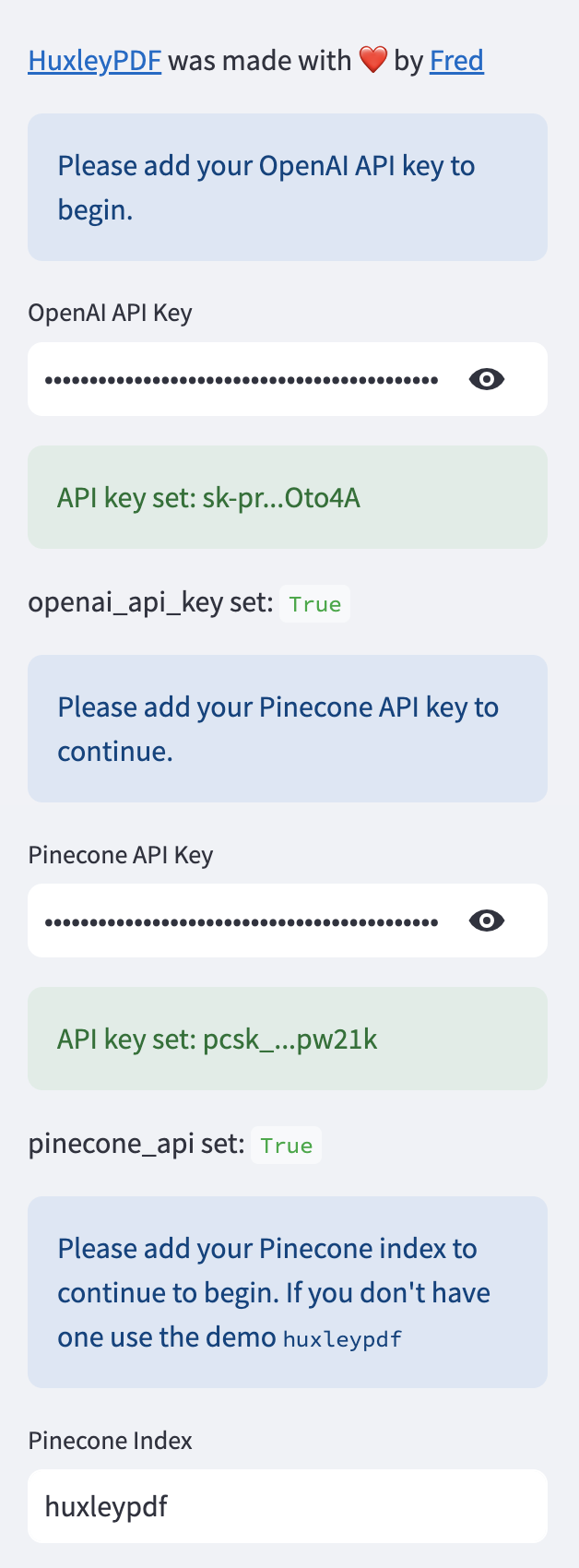
Huxley.py main()関数は、ユーザーインターフェイスの処理とアップロードされたPDFファイルの処理に責任があります。これがコードの内訳です:
render_header()関数は、アプリケーションのヘッダーセクションを表示するために呼び出されます。タイトル、説明、画像が含まれています。
sidebar()関数は、アプリケーションのサイドバーセクションを表示するために呼び出されます。 HuxLeypdfに関する情報、使用方法の指示、Openai APIキーの入力フィールドが含まれます。
環境をセットアップするために、 setup_environment()関数が呼び出されます。現在、セットアップが進行中であることを示すメッセージのみを印刷します。
st.file_uploader()関数は、PDFファイルをアップロードするために使用されます。ユーザーは、「PDFのアップロード」と「PDF」に設定されたファイルタイプフィルターを含むファイルを選択するように求められます。
次に、このコードは、非構造化ライブラリからOnlinePDFLoaderクラスを使用してリモートPDFファイルを取得します。これは今のところコメントアウトされています。
PDFファイルがアップロードされている場合、コードはPYMUPDFライブラリのPdfReaderクラスを使用してPDFからテキストを抽出します。
抽出されたテキストは、LangchainライブラリのCharacterTextSplitterクラスを使用してチャンクに分割されます。チャンクサイズは400文字に設定されており、チャンク間のオーバーラップは80文字に設定されます。
OpenAIEmbeddingsクラスは、テキストの塊の埋め込みを作成するために使用されます。
FAISS.from_texts()関数は、テキストのチャンクとその埋め込みからFAISSインデックスを作成するために使用されます。これは今のところコメントアウトされています。
ユーザーは、 st.text_input()関数を使用してPDFに関する質問を入力するように求められます。
質問が入力された場合、コードは、 similarity_search()メソッドを使用してユーザーの質問に最も類似したFAISSインデックスからドキュメントを取得します。
OpenAI()クラスは、OpenAI APIのインスタンスを作成するために使用されます。
load_qa_chain()関数は、OpenAI APIと「スタッフ」チェーンタイプを使用して、質問を回答するチェーンを作成するために使用されます。
get_openai_callback()コンテキストマネージャーは、OpenAI APIからのコールバック情報をキャプチャするために使用されます。
chain.run()メソッドは、入力ドキュメントとユーザーの質問で質問を回答するチェーンを実行するために使用されます。応答が印刷されます。
応答はst.write()関数を使用して表示されます。
全体として、 main()関数内のコードはユーザーインターフェイスを処理し、アップロードされたPDFファイルを処理し、OpenAI APIとLangchainライブラリを使用して質問回答タスクを実行します。


