huxley pdf
1.0.0
الدردشة مع مستندات PDF الشخصية الخاصة بك.

نظرة عامة على المستوى العالي لهذا التطبيق البطيء حسب الملف.
انقر هنا لتخطي تعليمات التثبيت
Huxley.py الوظيفة main() هي المسؤولة عن التعامل مع واجهة المستخدم ومعالجة ملف PDF الذي تم تحميله. إليك انهيار الرمز:
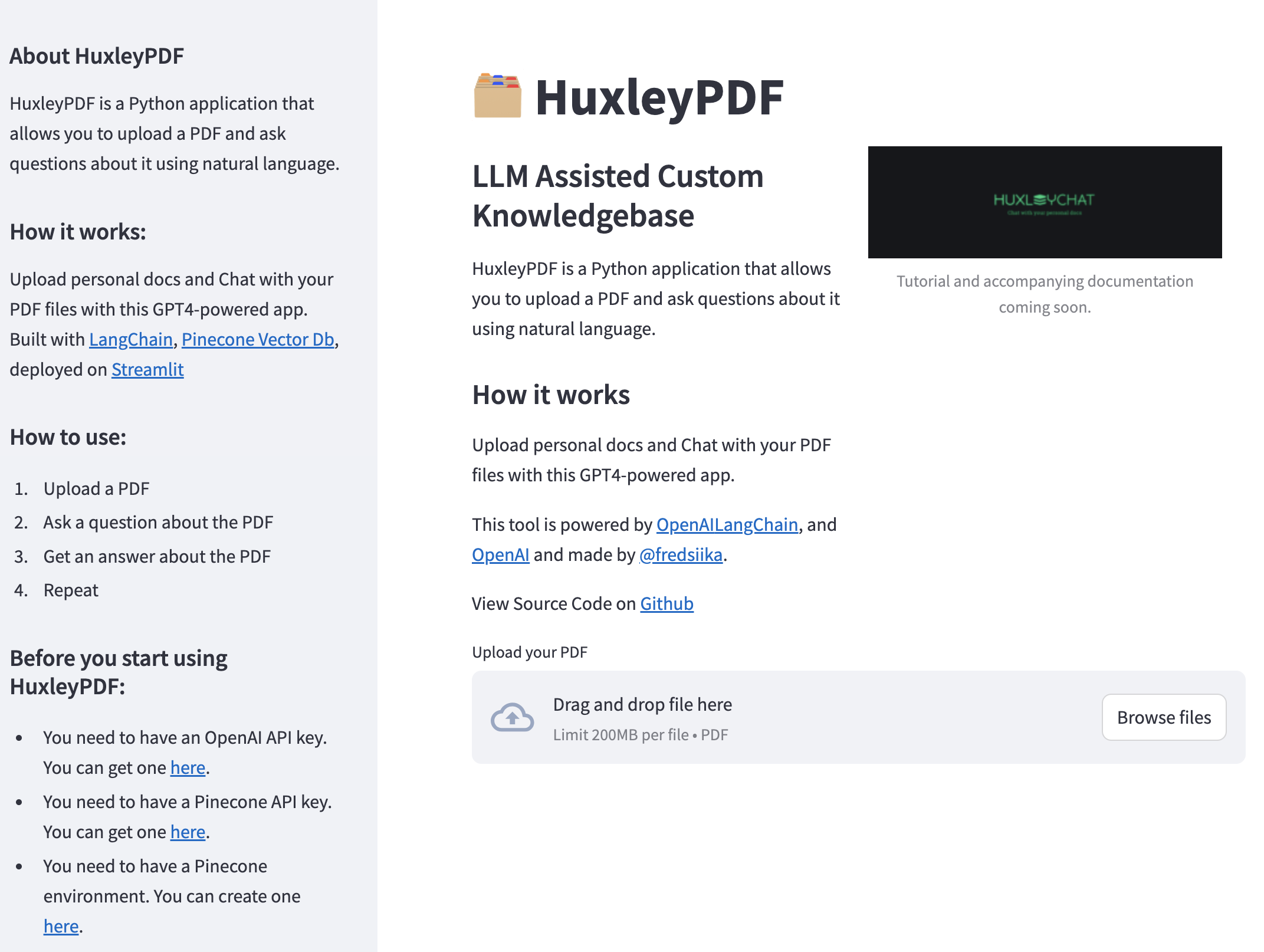
يتم استدعاء وظيفة render_header() لعرض قسم الرأس في التطبيق. ويشمل العنوان والوصف والصورة.
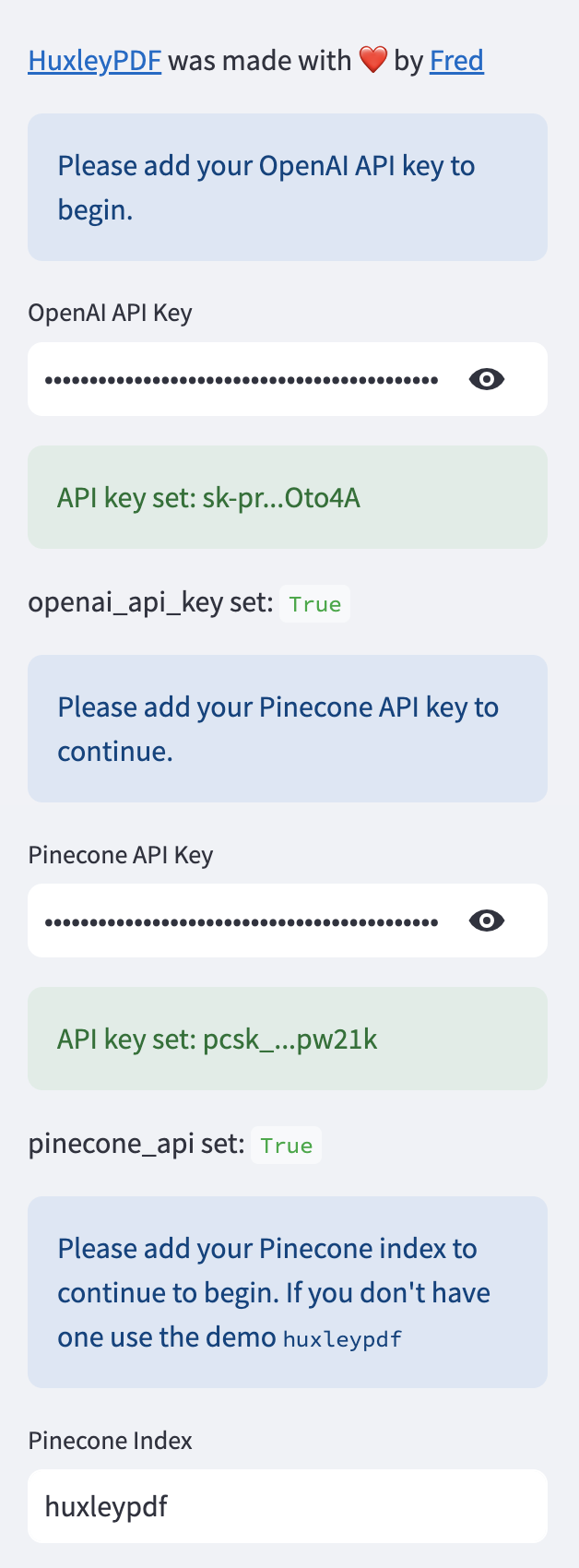
يتم استدعاء وظيفة sidebar() لعرض قسم الشريط الجانبي للتطبيق. ويتضمن معلومات حول HuxleyPDF ، وتعليمات حول كيفية استخدامه ، وحقول الإدخال لمفتاح Openai API.
يتم استدعاء وظيفة setup_environment() لإعداد البيئة. حاليًا ، يطبع رسالة تشير إلى أن الإعداد قيد التقدم.
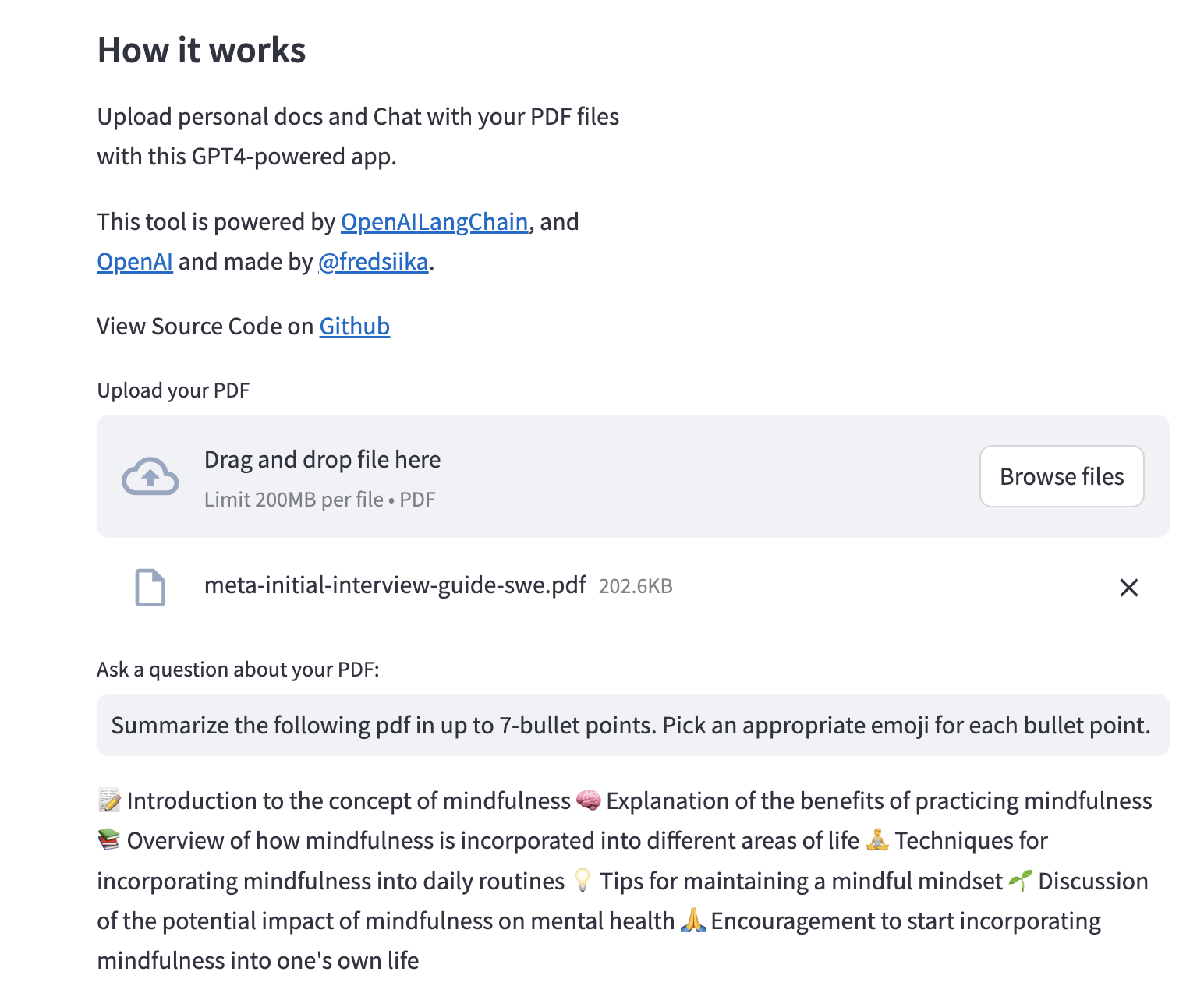
يتم استخدام وظيفة st.file_uploader() لتحميل ملف PDF. يُطلب من المستخدم تحديد ملف مع وصف "قم بتحميل PDF" وتعيين مرشح نوع الملف على "PDF".
ثم يجلب الرمز ملف PDF عن بُعد باستخدام فئة OnlinePDFLoader من المكتبة غير المهيكلة. تم التعليق هذا في الوقت الحالي.
إذا تم تحميل ملف PDF ، فإن الكود يستخرج النص من PDF باستخدام فئة PdfReader من مكتبة Pymupdf.
يتم تقسيم النص المستخرج إلى أجزاء باستخدام فئة CharacterTextSplitter من مكتبة Langchain. يتم ضبط حجم الجزء على 400 حرف ، ويتم ضبط التداخل بين القطع على 80 حرفًا.
يتم استخدام فئة OpenAIEmbeddings لإنشاء تضمينات لقطع النص.
يتم استخدام وظيفة FAISS.from_texts() لإنشاء فهرس faiss من قطع النص وتضميناتها. تم التعليق هذا في الوقت الحالي.
يُطلب من المستخدم إدخال سؤال حول PDF باستخدام وظيفة st.text_input() .
إذا تم إدخال سؤال ، فإن الكود يسترجع المستندات من فهرس FAISS الذي يشبه سؤال المستخدم باستخدام طريقة similarity_search() .
يتم استخدام فئة OpenAI() لإنشاء مثيل من API Openai.
يتم استخدام وظيفة load_qa_chain() لإنشاء سلسلة إجابة للأسئلة باستخدام API Openai و "الأشياء".
يتم استخدام مدير سياق get_openai_callback() لالتقاط معلومات رد الاتصال من Openai API.
يتم استخدام طريقة chain.run() لتشغيل سلسلة الإجابة على الأسئلة على مستندات الإدخال وسؤال المستخدم. يتم طباعة الاستجابة.
يتم عرض الاستجابة باستخدام وظيفة st.write() .
بشكل عام ، يعالج الكود الموجود في الدالة main() واجهة المستخدم ، ويعالج ملف PDF الذي تم تحميله ، ويقوم بمهمة إجادة الأسئلة باستخدام API Openai ومكتبة Langchain.


