検索エンジンシステム
ベクトルの類似性を使用して、画像とテキストの両方の検索機能をサポートするスケーラブルな検索エンジンシステム。
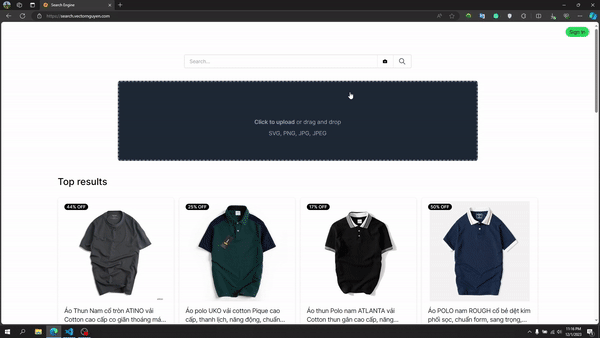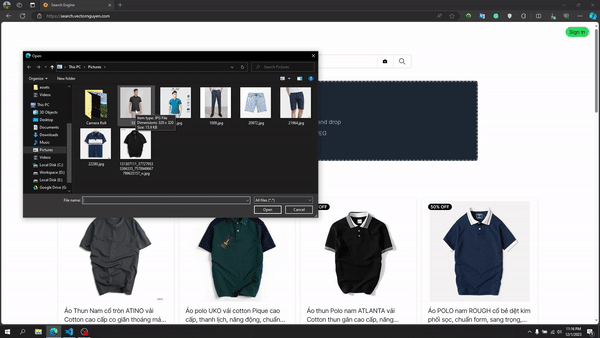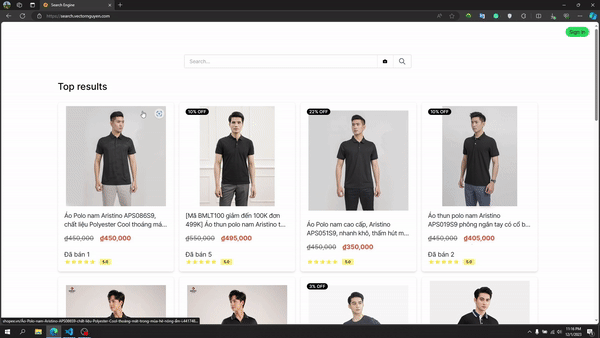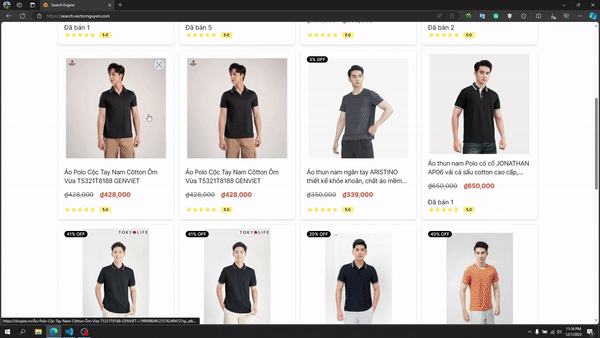
画像検索
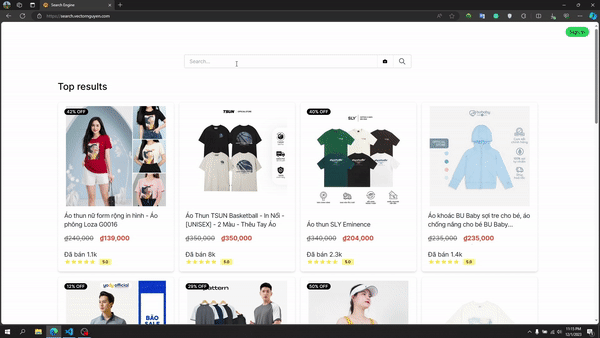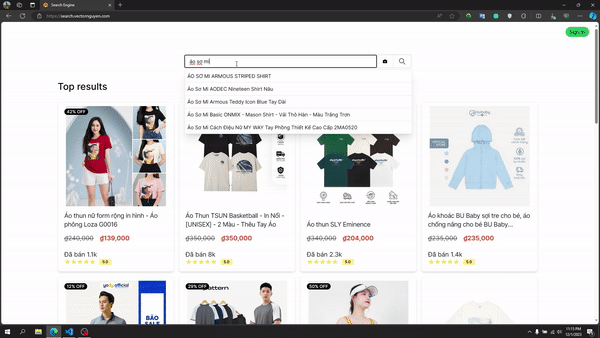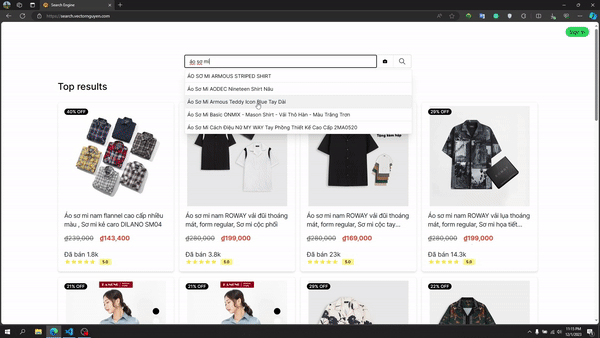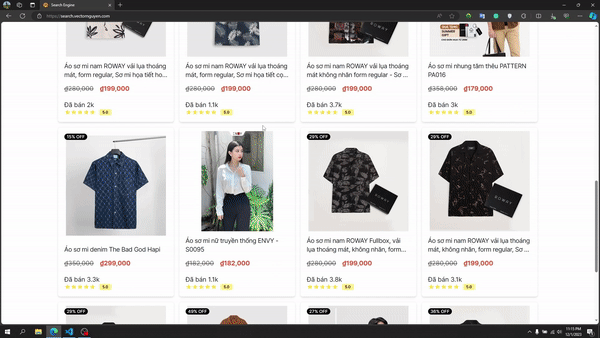
テキスト検索
システムアーキテクチャ
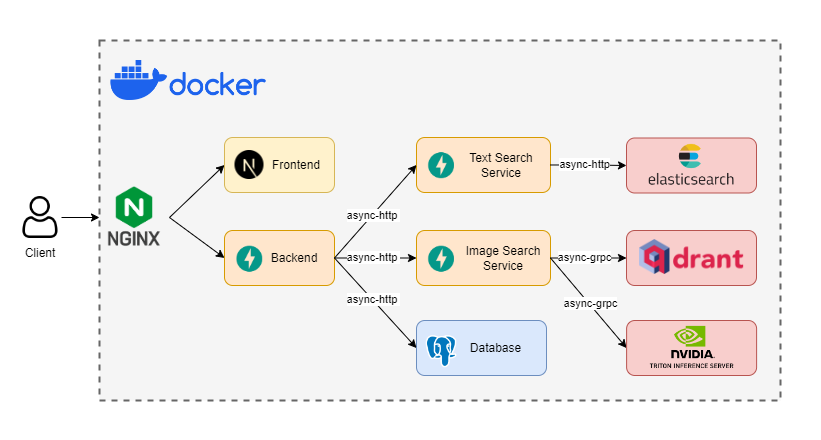
システムアーキテクチャ
特徴
技術的な詳細
画像検索パイプライン
前処理:
- 画像のサイズ変更と正規化
- トレーニングのためのデータ増強
- JPEG、PNG、およびWebP形式のサポート
機能抽出:
- ディープCNNアーキテクチャ(resnet/efficientnet)
- クロスプラットフォーム互換性のONNX形式
- GPU推論のためのTensortの最適化
- 出力:512/1024次元の埋め込みベクター
ベクトルストレージと検索:
- 効率的な類似性検索のためのQDRANTベクターデータベース
- 高速近くの近隣検索のためのHNSWインデックス
- 構成可能な距離メトリック(Cosine/Euclidean)
テキスト検索パイプライン
テキスト処理と分析:
- カスタムElasticsearchアナライザー:
- 小文字とASCII折りたたみを備えたキーワードアナライザー
- Autocomplete用のEdgeNgramアナライザー(min_gram:2、max_gram:5)
- フルテキスト検索用の標準アナライザー
- キャラクターフィルターとトークン化
- ベトナムのテキストのサポート
検索アプローチ:
AutoComplete(検索タイプ) :
- プレフィックスマッチング用のエッジNGRAMトークネザー
- カスタム完了提案者
- 即座の提案用に最適化されています
- 提案のための最低2文字
フルテキスト検索:
- フィールド全体のマルチマッチクエリ:
- オートファジネスと一致するファジー
- ビジネスメトリックに基づくカスタムスコアリング:
- 販売率(割引率)
- 販売量(> 1000販売ボーナス)
- アイテムの価格正規化
検索最適化:
- ElasticSearchスクリプトを使用したカスタムスコアリングテンプレート
- 効率的なデータ摂取のためのバッチインデックス
- 非同期検索操作
- 構成可能な結果サイズ
- エラー処理とロギング
ElasticSearch機能:
- カスタムインデックスマッピング
- 複数のフィールドタイプとアナライザー
- 関数スコアクエリ
- スクリプトベースのスコアリング
- バルクインデックス操作
テクノロジースタック
モデルサービング
- Nvidia Triton Inference Server :
- Tritonサーバーのドキュメント
- モデルバージョン化とA/Bテスト
- 動的バッチ
- 同時モデルの実行
- Tensortを使用したGPU最適化
- モデル形式変換パイプライン:
インフラストラクチャー
コンテナ化:
- Dockerマルチステージビルド
- 最適化されたコンテナ画像
- Dockerは開発のために作曲します
オーケストレーション:
- Kubernetesの展開
- パッケージ管理のためのヘルムチャート
- 水平ポッドの自動化
- リソース管理とスケーリング
監視とロギング:
- プロメテウスメトリック
- グラファナダッシュボード
- 分散トレース
- パフォーマンス監視
はじめる
- リポジトリをクローンします:
git clone https://github.com/vectornguyen76/search-engine-system.git
- Docker Composeを使用してサービスを開始します。
- サービスへのアクセス:
- 画像検索UI:http:// localhost:8501
- テキスト検索UI:http:// localhost:8502
- Triton Server:http:// localhost:8000
発達
CI/CDパイプライン
開発環境:
- コードリント(flake8)
- ユニットテスト
- 統合テスト
ステージング環境:
- パフォーマンステスト
- 負荷テスト
- セキュリティスキャン
生産環境:
コード品質
- Pythonコードの糸くずのFLAKE8
- ヒントとドキュメントを入力します
- CI/CDパイプラインでの自動テスト
- コードレビュープロセス
貢献
- リポジトリをフォークします
- 機能ブランチを作成します
- あなたの変更をコミットします
- 枝に押します
- 新しいプルリクエストを作成します
ライセンス
このプロジェクトは、MITライセンスに基づいてライセンスされています。詳細については、ライセンスファイルを参照してください。


