Système de moteur de recherche
Un système de moteur de recherche évolutif prenant en charge les capacités de recherche d'image et de texte à l'aide de la similitude vectorielle.
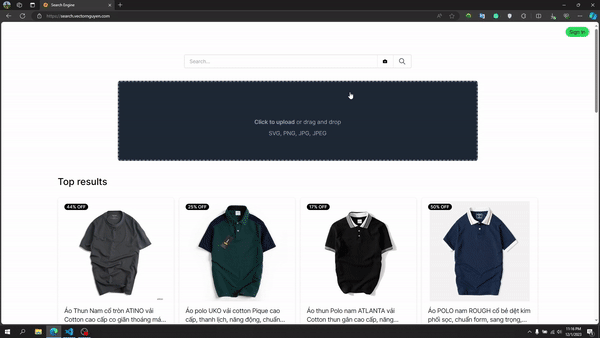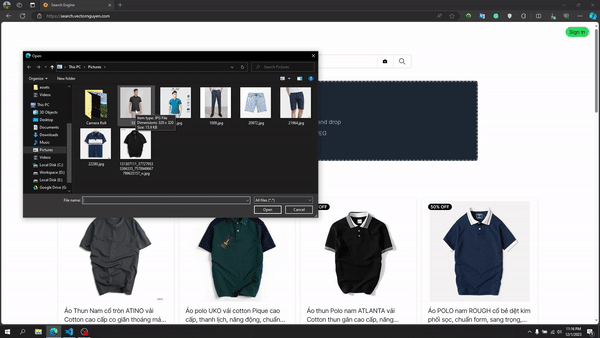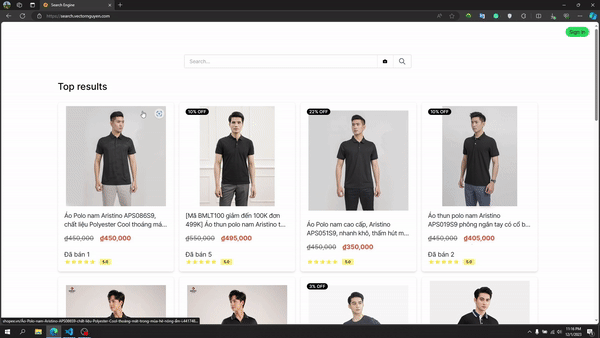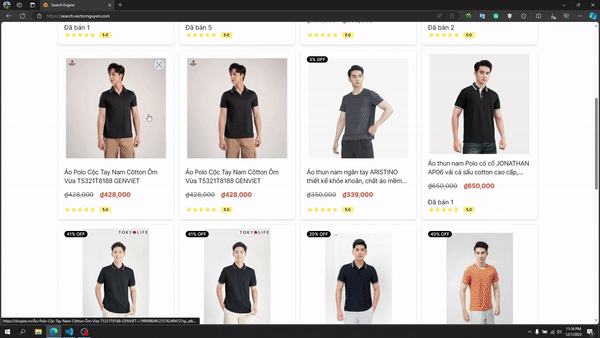
Recherche d'image
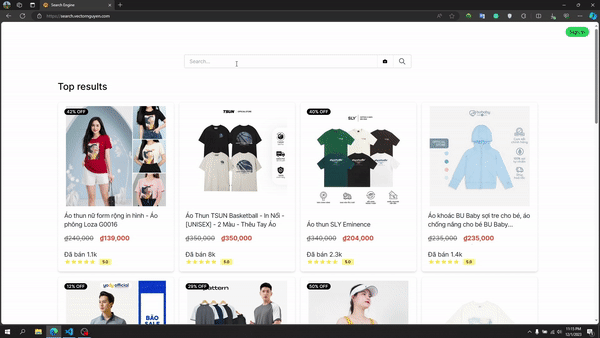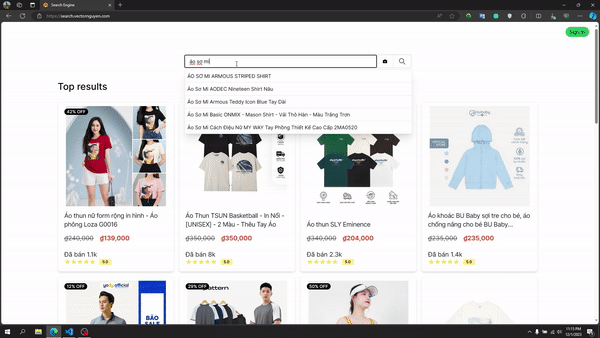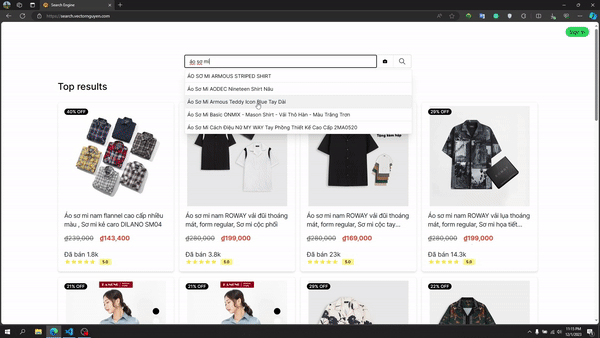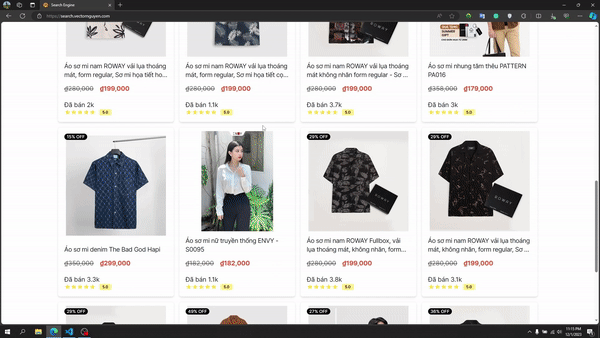
Recherche de texte
Architecture du système
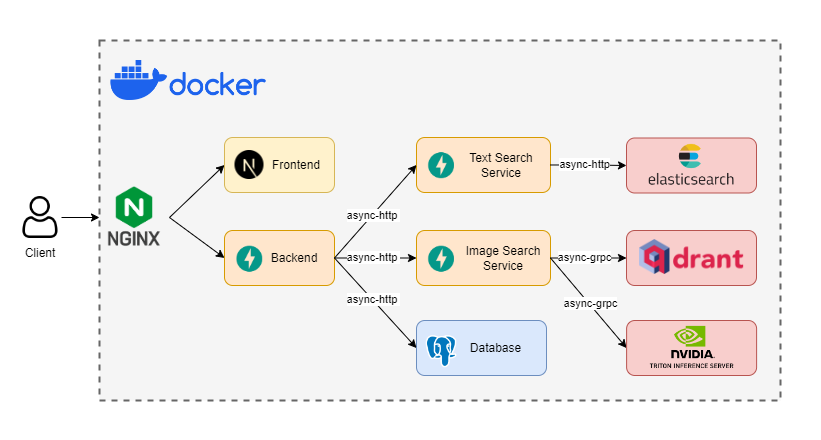
Architecture du système
Caractéristiques
Détails techniques
Pipeline de recherche d'images
Pipeline de recherche de texte
Traitement et analyse du texte :
- Analyseurs de recherche Elasticsearch personnalisés:
- Analyseur de mots clés avec pliage minuscule et ASCII
- Edge Ngram Analyzer pour la saisie semi-automatique (min_gram: 2, max_gram: 5)
- Analyseur standard pour la recherche en texte intégral
- Filtres de caractère et tokenisation
- Prise en charge du texte vietnamien
Approches de recherche :
Ambordage automatique (recherche de type astuce) :
- Tokenizer Edge Ngram pour la correspondance du préfixe
- Suggester d'achèvement personnalisé
- Optimisé pour les suggestions instantanées
- Minimum 2 caractères pour les suggestions
Recherche de texte intégral :
- Requête multi-match à travers les champs:
- Match flou avec le flou automatique
- Score personnalisé en fonction des mesures commerciales:
- Taux de vente (pourcentage de remise)
- Volume des ventes (> 1000 bonus de vente)
- Normalisation des prix de l'article
Optimisation de la recherche :
- Modèle de notation personnalisé à l'aide de scripts Elasticsearch
- Indexation par lots pour une ingestion de données efficace
- Opérations de recherche asynchrones
- Taille des résultats configurables
- Gestion des erreurs et journalisation
Caractéristiques Elasticsearch :
- Mappages d'index personnalisés
- Plusieurs types de champs et analyseurs
- Requêtes de score de fonction
- Score basé sur des scripts
- Opérations d'indexation en vrac
Pile technologique
Modèle de service
- Nvidia Triton Inference Server :
- Documentation du serveur Triton
- Versioning modèle et tests A / B
- Lots dynamiques
- Exécution du modèle simultané
- Optimisation du GPU avec Tensorrt
- Pipeline de conversion de format de modèle:
- Pytorch → Onnx → Tensorrt
Infrastructure
Commencer
- Clone le référentiel:
git clone https://github.com/vectornguyen76/search-engine-system.git
- Démarrez les services à l'aide de Docker Compose:
- Accéder aux services:
- Image Search UI: http: // localhost: 8501
- Recherche de texte UI: http: // localhost: 8502
- Serveur Triton: http: // localhost: 8000
Développement
Pipeline CI / CD
Environnement de développement :
- Code Linting (Flake8)
- Tests unitaires
- Tests d'intégration
Environnement de mise en scène :
- Tests de performance
- Tests de charge
- Analyse de sécurité
Environnement de production :
- Déploiement bleu-vert
- Recul automatisé
- Surveillance des performances
Qualité du code
- Flake8 pour le code de code python
- Tapez des conseils et de la documentation
- Tests automatisés dans le pipeline CI / CD
- Processus d'examen du code
Contributif
- Fourchez le référentiel
- Créez votre branche de fonctionnalité
- Engager vos modifications
- Pousser à la branche
- Créer une nouvelle demande de traction
Licence
Ce projet est autorisé en vertu de la licence MIT - voir le fichier de licence pour plus de détails.


