issuedigger
1.0.0
IssueDiggerは、類似した、以前に提出されたものに関する新しいGitHubの問題について著者に通知します。
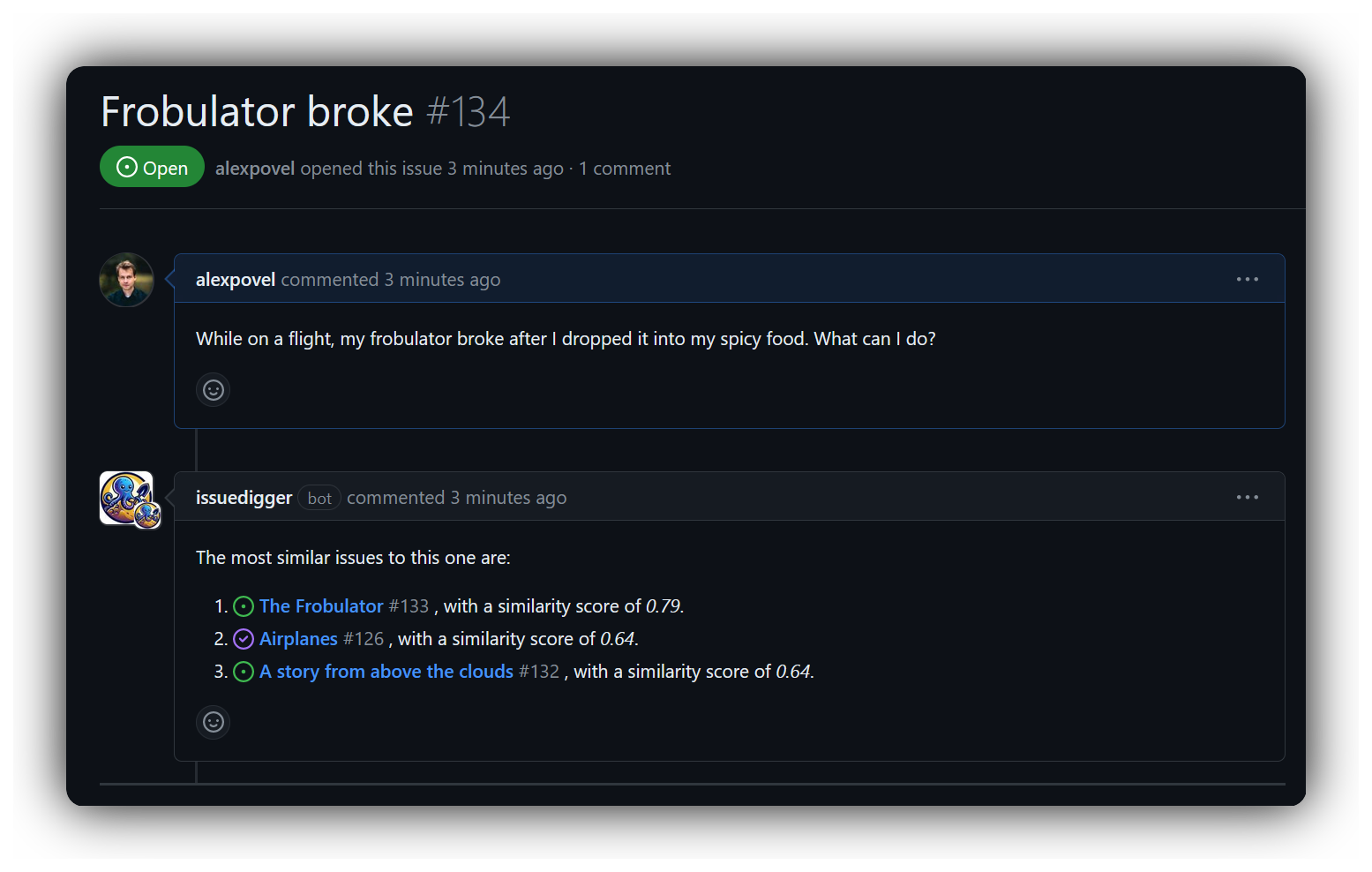
IssueDiggerは、メンテナーとエンドユーザーの両方が過去の問題を掘り下げる必要がないことを避けます(多くのプロジェクトが新しい問題を提出する前にユーザーがするように)。たとえば、上記のスクリーンショットでは、 「飛行機」というタイトルの問題が閉じられています。おそらく、ユーザーは問題の解決策を見つけますか?成功した場合、2番目の人間が関与する前に、新しい問題を解決できます。
副作用として、関連する問題のネットワーク(バグ、機能要求など)は、多くの場合、メンテナーの心に家賃のないスペースを占有し、自動化および外部化することができ、他の人がアクセスできるようにします。たとえば、複製はすぐにキャッチしてリンクできます(上記の問題と高い類似性スコアに注意してください):
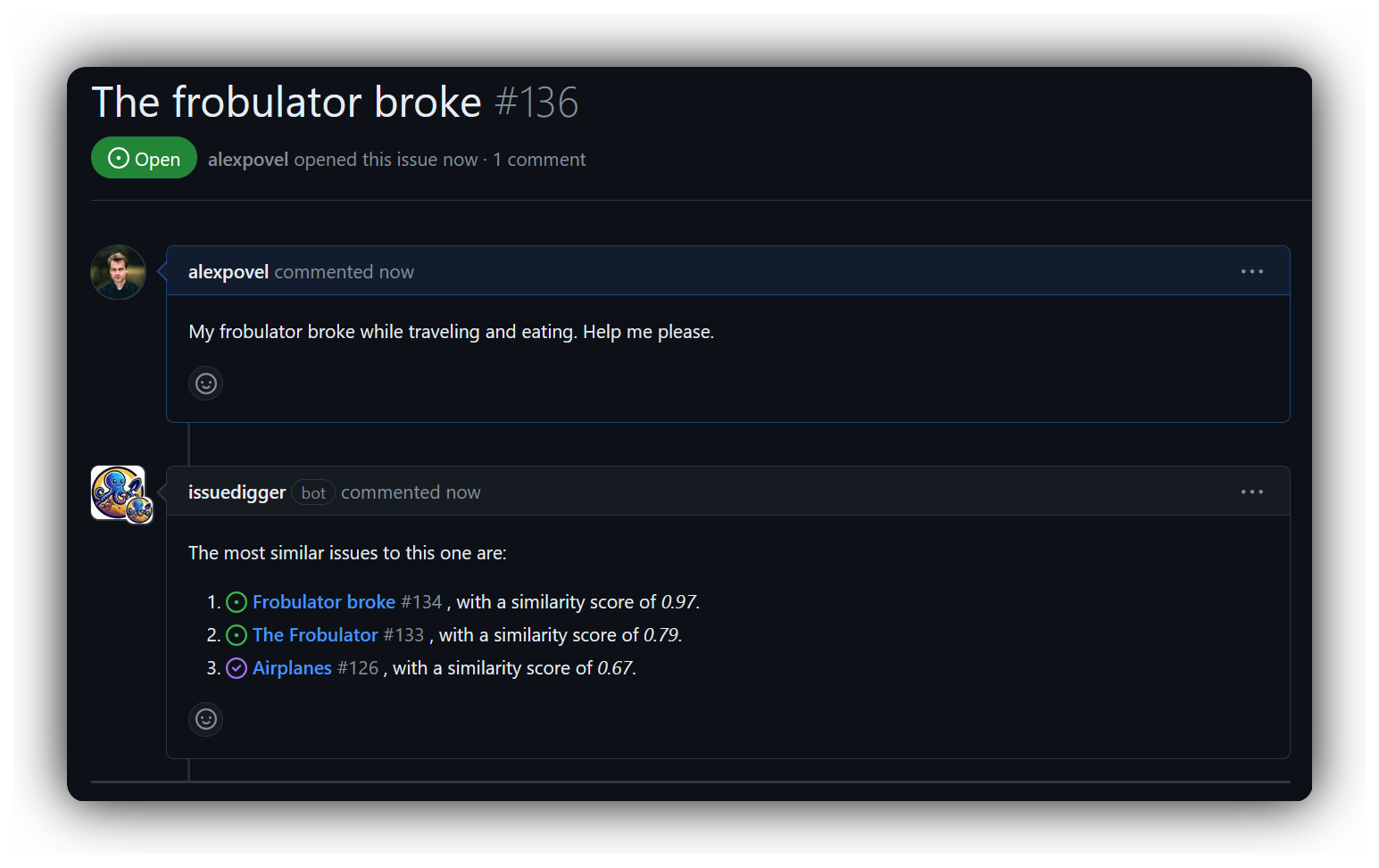
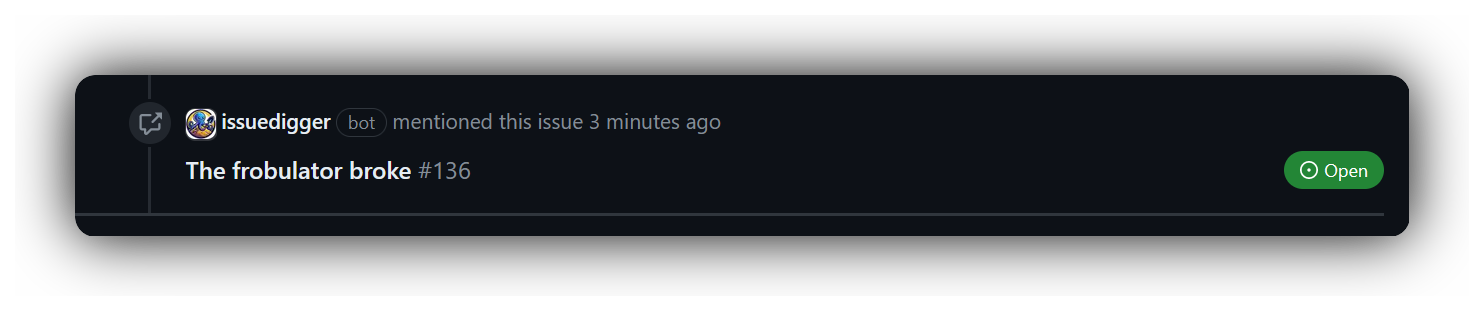
どのgithubが前述のリンクをリンクします、オリジナルの問題は自動的に次のとおりです。
独自の使用のためにインストールする前に、このリポジトリで問題を作成したり、コメントを発行したりして、発行中のタイヤをお気軽にキックしてください!
警告
このアプリケーションはベータ品質です。それは、それ自体がベータ版であるいくつかの製品に依存しています(CloudFlareキュー、CloudFlare Vectorize、CloudFlare Workers AI)。プロジェクトにはテストがありません(理由がないわけではありません)。新しいテクノロジー(TypeScript、 "AI"(埋め込み、ベクトルストレージなど)、CloudFlareの開発者製品)で遊んだり学ぶための言い訳と考えてください。
埋め込みは単純に処理されます。彼ら(さらには、発行された、発行、提案)が実際のシナリオでどれほど有用であるかは不明です。
IssueDiggerのインフラストラクチャを実行するのは安いですが、無料ではありません。意図は、それを無期限に利用できるようにすることですが、明らかにいつでもシャットダウンするリスクがあります。 wrangler.tomlは必要なすべてのインフラストラクチャ定義が含まれているため、アプリは自分のアカウントでスピンアップするのがそれほど難しくないはずです(このリポジトリ、 npx wrangler deployを実行し、機能するまで欠落しているエラーを修正します...)。
それでおしまい!以下は今起こっています:
新たに開かれた問題について一度コメントし、いつでもリクエストに応じてコメントします( @issuedigger dig 1をコメント)。
(最初のインストール時に、結果が上がる前にデータベースを入力する時間を与えてください)
すべての新しいアイテム(問題と問題のコメント)をインデックスし、類似性検索に利用できるようにします
問題スレッドは単一のユニットとして扱われます。最初の問題自体とすべてのコメント(発行済みの発行者自体に関連するものを除く)は、類似性に等しく貢献します。そのため、(潜在的に完全に無関係な)概念Bに言及するコメントを使用して、概念Aに言及している問題機関は、 Aおよび/またはBの両方に関連する問題を開くユーザーに後で提案できます。これは、XYの問題を軽減するのに役立ちます。
詳細な概要については、architecture.mdを参照してください。
通常のユーザーに対しては、 @ typing @はオートコンプリートを開始しません。アプリに言及することはそのようには機能しません。心配しないでください、あなたのコメントはまだ取り上げられます。 ↩


