api for open llm
latest
【2024.06.13】サポートMiniCPM-Llama3-V-2_5モデル、環境変数MODEL_NAME=minicpm-v PROMPT_NAME=minicpm-v DTYPE=bfloat16を変更する
[2024.06.12] GLM-4Vモデルをサポートし、環境変数MODEL_NAME=glm-4v PROMPT_NAME=glm-4v DTYPE=bfloat16を変更します。テスト例についてはGLM4Vを参照してください。
【 QWEN2モデルがサポートされています。環境変数MODEL_NAME=qwen2 PROMPT_NAME=qwen2を変更します
【2024.06.05はGLM4モデルをサポートし、環境変数MODEL_NAME=chatglm4 PROMPT_NAME=chatglm4を変更する
【2024.04.18】サポートCode Qwenモデル、SQL Q&Aデモ
【2024.04.16】 Rerank注文モデル、使用方法をサポートします
【 QWEN1.5 】環境変数MODEL_NAME=qwen2 PROMPT_NAME=qwen2
その他のニュースと歴史については、こちらをご覧ください
このプロジェクトの主な内容
このプロジェクトは、オープンソースの大規模モデルの推論のために統一されたバックエンドインターフェイスを実装します。これは、 OpenAIの応答と一致しており、次の特性を持っています。
OpenAI ChatGPT APIの形でさまざまなオープンソースモデルを呼び出す
?§は、プリンター効果を実現するためのストリーミング応答をサポートしています
テキスト埋め込みモデルを実装して、ドキュメントの知識Q&Aのサポートを提供する
?️は、大規模な言語モデル開発ツールであるlangchainのさまざまな機能をサポートしています
? chatgptの代替モデルとしてオープンソースモデルを使用するために、環境変数を単純に変更するだけで、さまざまなアプリケーションにバックエンドサポートが提供されます。
自己訓練されたloraモデルの負荷をサポートします
⚡vllm推論の加速と同時リクエストの処理
| 章 | 説明する |
|---|---|
| ?? ♂サポートモデル | このプロジェクトと簡単な情報でサポートされているオープンソースモデル |
| ?開始方法 | 起動モデルの環境構成と起動コマンド |
| ⚡vllm起動方法 | vLLMを使用してモデルを開始するための環境構成と起動コマンド |
| 通話方法 | モデルを開始した後に呼び出す方法 |
| ❓faq | いくつかのFAQへの返信 |
言語モデル
| モデル | モデルパラメーターサイズ |
|---|---|
| バイチュアン | 7b/13b |
| chatglm | 6b |
| deepseek | 7b/16b/67b/236b |
| internlm | 7b/20b |
| ラマ | 7b/13b/33b/65b |
| llama-2 | 7b/13b/70b |
| llama-3 | 8b/70b |
| Qwen | 1.8b/7b/14b/72b |
| QWEN1.5 | 0.5b/1.8b/4b/7b/14b/32b/72b/110b |
| QWEN2 | 0.5b/1.5b/7b/57b/72b |
| yi(1/1.5) | 6b/9b/34b |
詳細については、VLLM起動方法とトランスフォーマーの起動方法を参照してください。
埋め込みモデル
| モデル | 寸法 | 重量リンク |
|---|---|---|
| bge-large-zh | 1024 | bge-large-zh |
| M3E-Large | 1024 | Moka-ai/M3e-large |
| text2vec-large-chinese | 1024 | text2vec-large-chinese |
| bce-embedding-base_v1(推奨) | 768 | bce-embedding-base_v1 |
OPENAI_API_KEY :ここで文字列を入力してください
OPENAI_API_BASE :http://192.168.0.xx:80/v1などのバックエンド起動のインターフェイスアドレス
cd streamlit-demo
pip install -r requirements.txt
streamlit run streamlit_app.py
from openai import OpenAI
client = OpenAI (
api_key = "EMPTY" ,
base_url = "http://192.168.20.59:7891/v1/" ,
)
# Chat completion API
chat_completion = client . chat . completions . create (
messages = [
{
"role" : "user" ,
"content" : "你好" ,
}
],
model = "gpt-3.5-turbo" ,
)
print ( chat_completion )
# 你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
# stream = client.chat.completions.create(
# messages=[
# {
# "role": "user",
# "content": "感冒了怎么办",
# }
# ],
# model="gpt-3.5-turbo",
# stream=True,
# )
# for part in stream:
# print(part.choices[0].delta.content or "", end="", flush=True) from openai import OpenAI
client = OpenAI (
api_key = "EMPTY" ,
base_url = "http://192.168.20.59:7891/v1/" ,
)
# Chat completion API
completion = client . completions . create (
model = "gpt-3.5-turbo" ,
prompt = "你好" ,
)
print ( completion )
# 你好!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。 from openai import OpenAI
client = OpenAI (
api_key = "EMPTY" ,
base_url = "http://192.168.20.59:7891/v1/" ,
)
# compute the embedding of the text
embedding = client . embeddings . create (
input = "你好" ,
model = "text-embedding-ada-002"
)
print ( embedding )OPENAI_API_BASE環境変数を変更することにより、ほとんどのchatgptアプリケーションとフロントエンドプロジェクトをシームレスに接続できます!
docker run -d -p 3000:3000
-e OPENAI_API_KEY= " sk-xxxx "
-e BASE_URL= " http://192.168.0.xx:80 "
yidadaa/chatgpt-next-web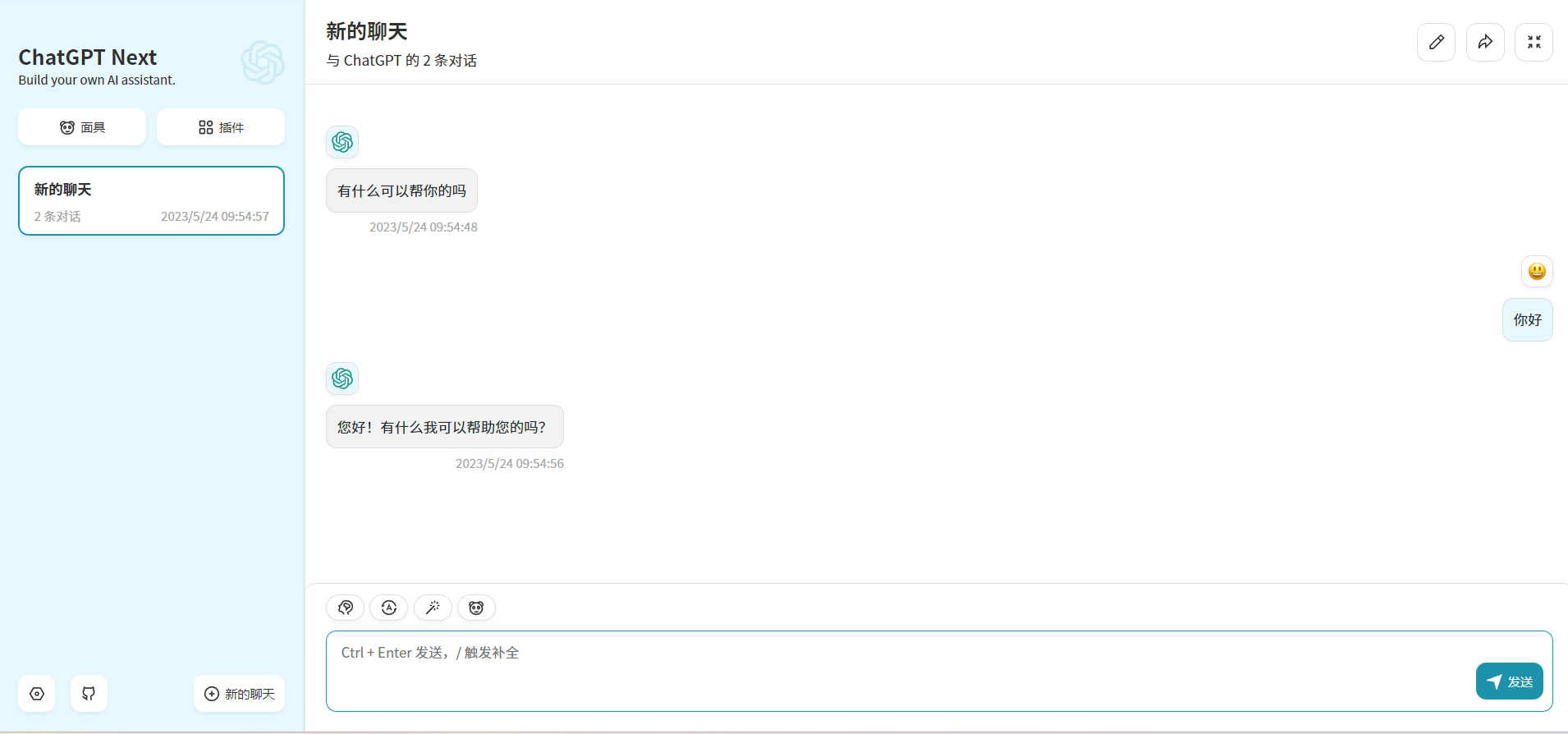
# 在docker-compose.yml中的api和worker服务中添加以下环境变量
OPENAI_API_BASE: http://192.168.0.xx:80/v1
DISABLE_PROVIDER_CONFIG_VALIDATION: ' true ' 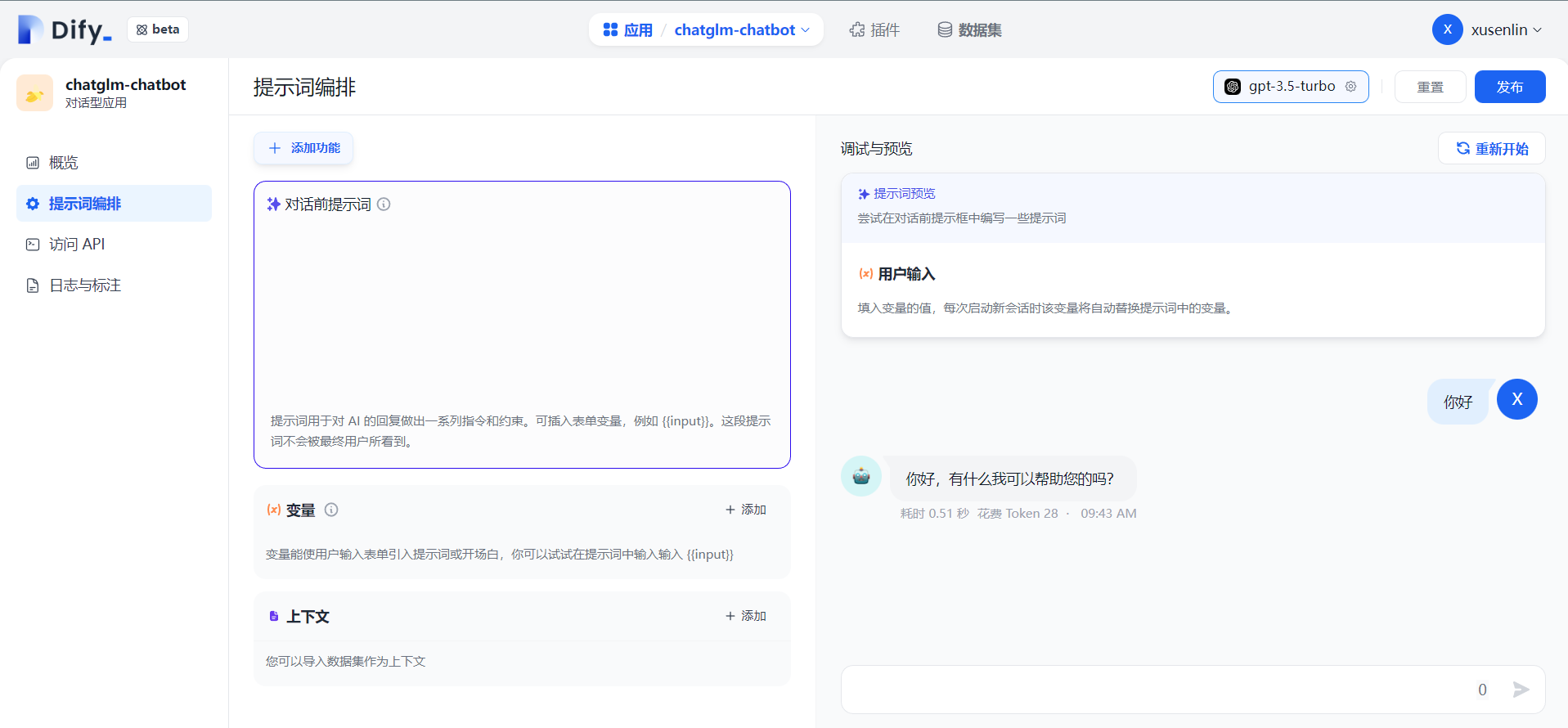
このプロジェクトは、 Apache 2.0ライセンスの下でライセンスされています。詳細については、ライセンスファイルを参照してください。
ChatGlm:オープンバイリンガルの対話言語モデル
Bloom:176B-Parameterオープンアクセス多言語言語モデル
ラマ:オープンで効率的な基礎言語モデル
中国のラマとアルパカ向けの効率的で効果的なテキストエンコード
フェニックス:言語間でChatGptを民主化する
Moss:オープンソースのプラグインを介した会話言語モデル
FastChat:大規模な言語モデルベースのチャットボットのトレーニング、提供、評価のためのオープンプラットフォーム
Langchain:複合性を通じてLLMを使用したアプリケーションを構築します
chuanhuchatgpt


