IncarnaMind
1.0.0
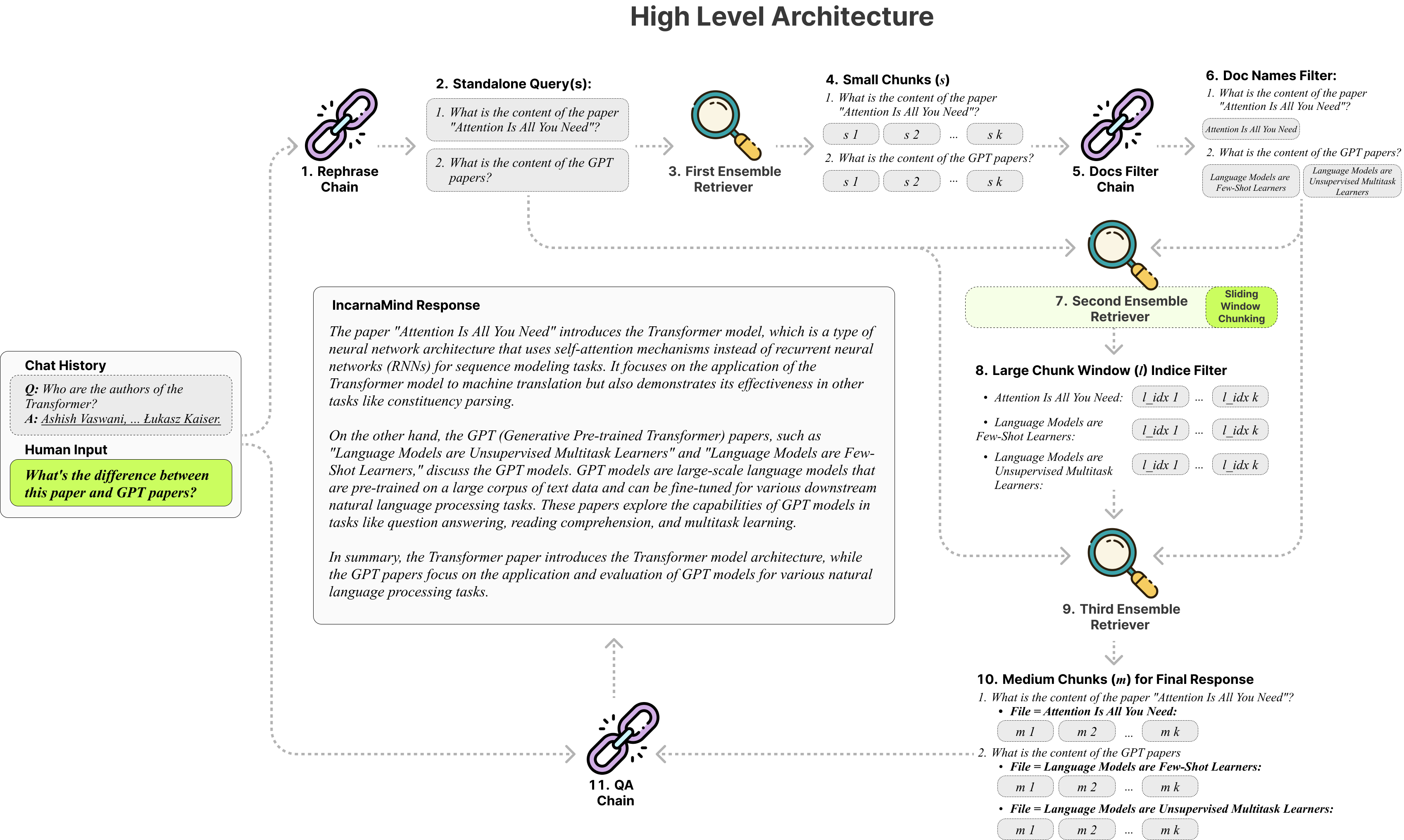
incarnamindを使用すると、個人の文書とチャットできますか? (PDF、TXT)GPT(アーキテクチャの概要)などの大規模な言語モデル(LLM)を使用しています。 Openaiは最近、GPTモデル向けに微調整APIを発売しましたが、基本前提型モデルが新しいデータを学習することはできず、応答は事実上の幻覚を起こしやすい可能性があります。スライディングウィンドウチャンキングメカニズムとアンサンブルレトリバーを使用すると、LLMSを強化するために、グラウンドトゥルースドキュメント内で細粒と粗粒の両方の情報を効率的にクエリすることができます。
自由に使用してください。フィードバックや新機能の提案を歓迎します。
これは、私がテストしたさまざまなモデルの比較表を参照してのみです。
| メトリック | GPT-4 | GPT-3.5 | クロード2.0 | llama2-70b | llama2-70b-gguf | llama2-70b-api |
|---|---|---|---|---|---|---|
| 推論 | 高い | 中くらい | 高い | 中くらい | 中くらい | 中くらい |
| スピード | 中くらい | 高い | 中くらい | 非常に低い | 低い | 中くらい |
| GPU RAM | n/a | n/a | n/a | 非常に高い | 高い | n/a |
| 安全性 | 低い | 低い | 低い | 高い | 高い | 低い |
固定チャンキング:従来のRAGツールは固定チャンクサイズに依存しており、さまざまなデータの複雑さとコンテキストを処理する際の適応性を制限します。
精度とセマンティクス:現在の検索方法は通常、セマンティック理解または正確な検索に焦点を当てていますが、両方ともめったにありません。
単一ドキュメントの制限:多くのソリューションは、一度に1つのドキュメントのみをクエリすることができ、マルチドキュメント情報の取得を制限します。
安定性:carnamindは、Openai GPT、人類のクロード、LLAMA2、およびその他のオープンソースLLMと互換性があり、安定した解析を確保します。
アダプティブチャンキング:スライディングウィンドウチャンキングテクニックは、データの複雑さとコンテキストに基づいて、微粒と粗粒のデータアクセスのバランスをとる、ラグのウィンドウサイズと位置を動的に調整します。
マルチドキュメント会話QA :複数のドキュメントで同時にシンプルなマルチホップクエリとマルチホップクエリをサポートし、単一ドキュメントの制限を破ります。
ファイル互換性:PDFとTXTファイル形式の両方をサポートします。
LLMモデルの互換性:Openai GPT、Anthropic Claude、LLAMA2およびその他のオープンソースLLMをサポートしています。

インストールは簡単です。コマンドをほとんど実行する必要があります。
git clone https://github.com/junruxiong/IncarnaMind
cd IncarnaMindコンドラの仮想環境を作成します:
conda create -n IncarnaMind python=3.10活性化:
conda activate IncarnaMindすべての要件をインストールする:
pip install -r requirements.txt量子化されたローカルLLMを実行する場合は、llama-cppを別々にインストールします。
NVIDIA GPUSサポートには、 cuBLASを使用してくださいCMAKE_ARGS= " -DLLAMA_CUBLAS=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirM1/M2 )サポートの場合、使用しますCMAKE_ARGS= " -DLLAMA_METAL=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirconfigparser.iniファイルで1つ/すべてのAPIキーをセットアップします。
[tokens]
OPENAI_API_KEY = (replace_me)
ANTHROPIC_API_KEY = (replace_me)
TOGETHER_API_KEY = (replace_me)
# if you use full Meta-Llama models, you may need Huggingface token to access.
HUGGINGFACE_TOKEN = (replace_me)(オプション) configparser.iniファイルでカスタムパラメーターをセットアップします。
[parameters]
PARAMETERS 1 = (replace_me)
PARAMETERS 2 = (replace_me)
...
PARAMETERS n = (replace_me)すべてのファイルを/データディレクトリにすべてのファイルを配置し(パフォーマンスを最大化するには、各ファイルに名前を付けてください)、次のコマンドを実行してすべてのデータを摂取します。
python docs2db.py会話を開始するには、次のようなコマンドを実行します。
python main.pyスクリプトが以下のようにあなたの入力を要求するのを待ちます。
Human:チャットを開始すると、システムは自動的にcannamind.logファイルを生成します。ロギングを編集する場合は、 configparser.iniファイルで編集してください。
[logging]
enabled = True
level = INFO
filename = IncarnaMind.log
format = %(asctime)s [%(levelname)s] %(name)s: %(message)sLangchain、Chroma DB、Localgpt、Llama-CPPに、オープンソースコミュニティへの貴重な貢献に感謝します。彼らの仕事は、cannamindプロジェクトを現実にするのに役立ちました。
私たちの作品を引用したい場合は、次のBibtexエントリを使用してください。
@misc { IncarnaMind2023 ,
author = { Junru Xiong } ,
title = { IncarnaMind } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub Repository } ,
howpublished = { url{https://github.com/junruxiong/IncarnaMind} }
}Apache 2.0ライセンス


