pandas ai
v2.4.0
パンダサイは、自然言語のデータに簡単に質問することができるPythonプラットフォームです。非技術的なユーザーがより自然な方法でデータと対話するのに役立ち、技術的なユーザーがデータを使用するときに時間と労力を節約するのに役立ちます。
パンダサイはさまざまな方法で使用できます。 Jupyterノートブックやretrylidアプリで簡単に使用できます。または、FastapiやFlaskなどのREST APIとして展開できます。
マネージドパンダサイクラウドまたは自己ホストされたエンタープライズオファリングに興味がある場合は、お問い合わせください。
パンダサイの完全なドキュメントはこちらをご覧ください。
JupyterノートブックでPandasaiを使用したり、Remollitアプリを使用したり、リポジトリのクライアントとサーバーアーキテクチャを使用することを決定できます。
Pandasai Platformは、Dockerized Client-Serverアーキテクチャを使用しています。 Dockerをマシンにインストールする必要があります。
git clone https://github.com/sinaptik-ai/pandas-ai/
cd pandas-ai
docker-compose buildプラットフォームを構築したら、次のように実行できます。
docker-compose upこれにより、クライアントとサーバーが起動し、 http://localhost:3000でクライアントにアクセスできます。
PIPまたは詩を使用してパンダサイライブラリをインストールできます。
ピップ付き:
pip install pandasai詩:
poetry add pandasaiブラウザでパンダサイライブラリを自分で試してみてください。
import os
import pandas as pd
from pandasai import Agent
# Sample DataFrame
sales_by_country = pd . DataFrame ({
"country" : [ "United States" , "United Kingdom" , "France" , "Germany" , "Italy" , "Spain" , "Canada" , "Australia" , "Japan" , "China" ],
"revenue" : [ 5000 , 3200 , 2900 , 4100 , 2300 , 2100 , 2500 , 2600 , 4500 , 7000 ]
})
# By default, unless you choose a different LLM, it will use BambooLLM.
# You can get your free API key signing up at https://pandabi.ai (you can also configure it in your .env file)
os . environ [ "PANDASAI_API_KEY" ] = "YOUR_API_KEY"
agent = Agent ( sales_by_country )
agent . chat ( 'Which are the top 5 countries by sales?' ) China, United States, Japan, Germany, Australia
または、より複雑な質問をすることができます:
agent . chat (
"What is the total sales for the top 3 countries by sales?"
) The total sales for the top 3 countries by sales is 16500.
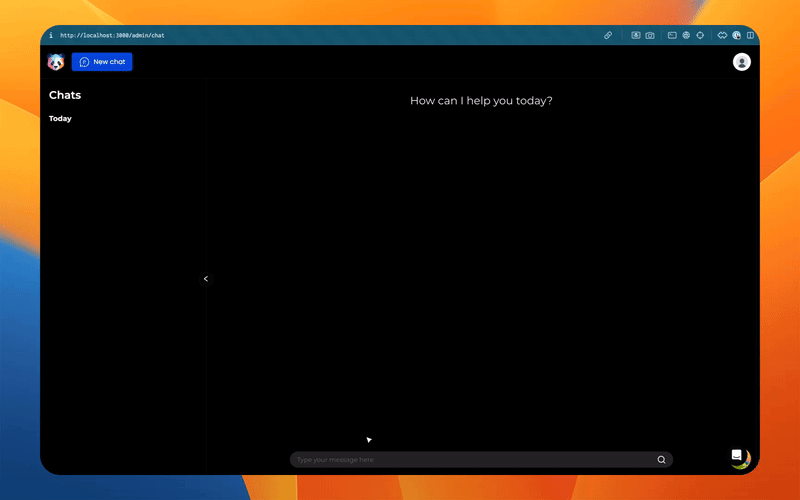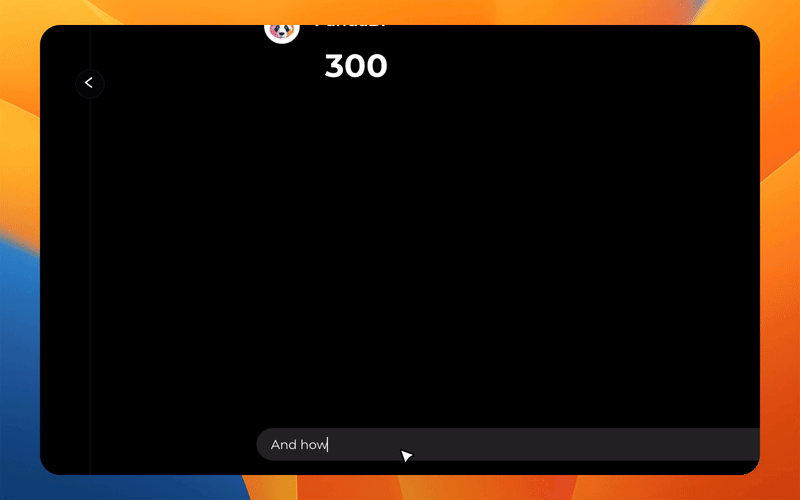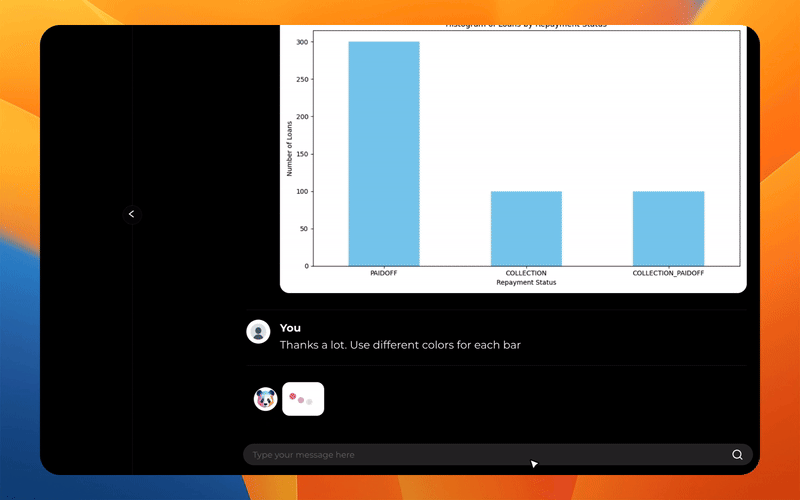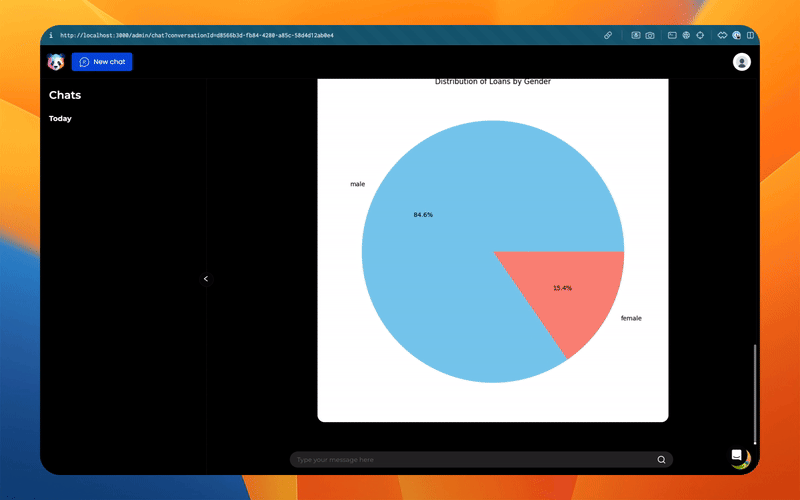
また、パンダサイにチャートを生成するように依頼することもできます。
agent . chat (
"Plot the histogram of countries showing for each one the gd. Use different colors for each bar" ,
)
また、複数のデータフレームをパンダサイに渡して、それらに関連する質問をすることもできます。
import os
import pandas as pd
from pandasai import Agent
employees_data = {
'EmployeeID' : [ 1 , 2 , 3 , 4 , 5 ],
'Name' : [ 'John' , 'Emma' , 'Liam' , 'Olivia' , 'William' ],
'Department' : [ 'HR' , 'Sales' , 'IT' , 'Marketing' , 'Finance' ]
}
salaries_data = {
'EmployeeID' : [ 1 , 2 , 3 , 4 , 5 ],
'Salary' : [ 5000 , 6000 , 4500 , 7000 , 5500 ]
}
employees_df = pd . DataFrame ( employees_data )
salaries_df = pd . DataFrame ( salaries_data )
# By default, unless you choose a different LLM, it will use BambooLLM.
# You can get your free API key signing up at https://pandabi.ai (you can also configure it in your .env file)
os . environ [ "PANDASAI_API_KEY" ] = "YOUR_API_KEY"
agent = Agent ([ employees_df , salaries_df ])
agent . chat ( "Who gets paid the most?" ) Olivia gets paid the most.
例ディレクトリには、より多くの例を見つけることができます。
実行するPythonコードを生成するために、データフレームからいくつかのランダムサンプルを使用して、ランダム化します(ランダム生成を使用して機密データを使用し、非感受性データにシャッフルします)。
プライバシーをさらに強制したい場合は、Pandasaiをenforce_privacy = Trueでインスタンス化できます。
パンダサイは、 pandasai/eeディレクトリを除き、MIT Expatライセンスの下で入手できます(該当する場合はここにライセンスがあります。
マネージドパンダサイクラウドまたは自己ホストされたエンタープライズオファリングに興味がある場合は、お問い合わせください。
貢献は大歓迎です!未解決の問題を確認して、お気軽にプルリクエストを開いてください。詳細については、貢献ガイドラインをご覧ください。


