Pidato Alami2
v1.0
naturalspeech2 github. Baru-baru ini, Microsoft mengumumkan bahwa mereka akan meluncurkan model besar baru: NaturalSpeech2. Dibandingkan dengan model besar sebelumnya, rekonstruksi ucapan NaturalSpeech2 "lebih akurat", tidak akan "membaca", dan dapat memberikan pengalaman dan Pelayanan yang lebih baik kepada pengguna. .
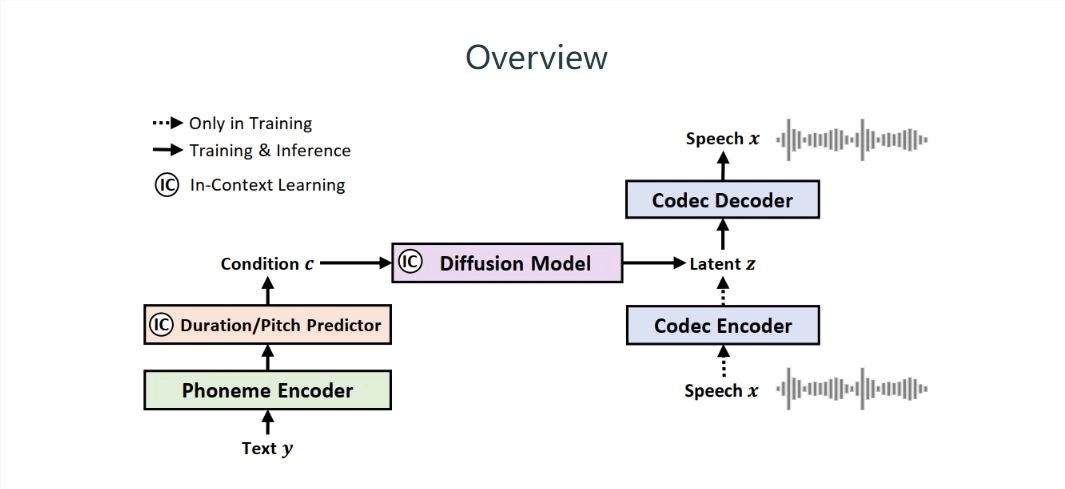
Microsoft baru-baru ini meluncurkan model ucapan yang disebut NaturalSpeech2. Model ini mengadopsi desain "difusi potensial" dan memiliki hasil yang luar biasa pada tingkat sintesis ucapan tanpa sampel. Microsoft mengklaim bahwa model tersebut memberikan solusi ucapan/nyanyian "tingkat komersial" yang dapat Memberikan pengguna pengalaman sintesis ucapan berkualitas tinggi dan beragam.
Microsoft melakukan serangkaian demonstrasi NaturalSpeech2, menunjukkan kemampuannya menghasilkan ucapan dengan identitas pembicara, prosodi, dan gaya yang berbeda (seperti bernyanyi) dalam situasi tanpa sampel.
Dilaporkan bahwa, tidak seperti sistem ucapan-ke-teks (TTS) tradisional, NaturalSpeech2 Microsoft menggunakan "vektor kontinu" dan bukan "penanda diskrit" untuk merepresentasikan ucapan, sehingga menghasilkan segmen ucapan yang lebih lengkap dan tidak menghasilkan "pembacaan tetap" yaitu " tanpa emosi". (Berbicara kata demi kata)" fenomena.
Hasil eksperimen menunjukkan bahwa ucapan yang dihasilkan oleh NaturalSpeech2 dalam kondisi sampel nol hampir konsisten dengan prosodi perintah ucapan dan ucapan nyata, dan kealamian (diukur dengan CMOS) pada set pengujian LibriTTS dan VCTK tidak dapat dibedakan dari ucapan sebenarnya.
Makalah untuk proyek ini saat ini diterbitkan di GitHub
1. Model besar resmi diluncurkan oleh Microsoft
2. Ini akan membawa banyak interaksi baru yang kaya bagi para pemain.
3. Saat ini sedang dalam pengembangan intensif, harap pantau terus.