كلام طبيعي2
v1.0
NaturalSpeech2 github. أعلنت Microsoft مؤخرًا أنها ستطلق نموذجًا كبيرًا جديدًا: NaturalSpeech2. بالمقارنة مع النماذج الكبيرة السابقة، فإن إعادة بناء الكلام NaturalSpeech2 "أكثر دقة"، ولن "تلتصق بالقراءة"، ويمكن أن توفر للمستخدمين تجربة وخدمة أفضل. .
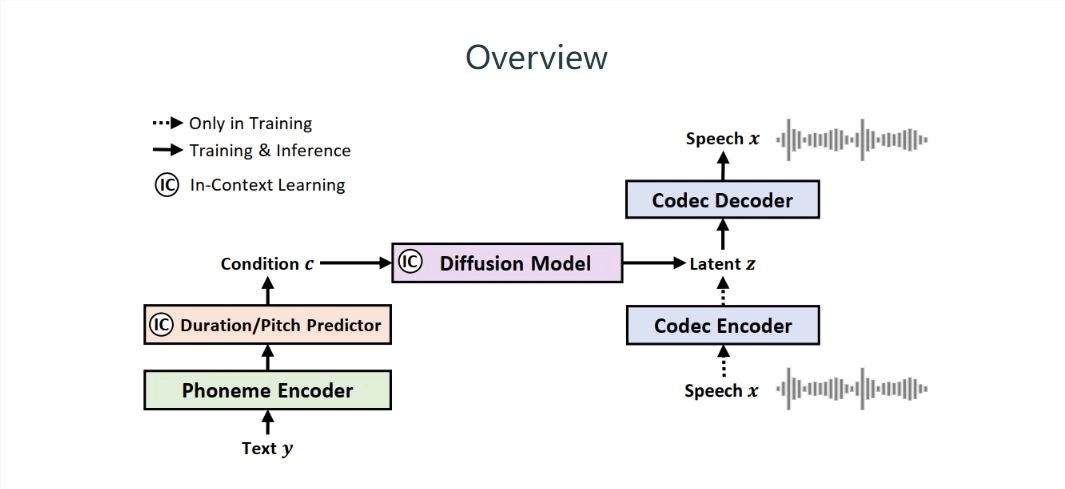
أطلقت Microsoft مؤخرًا نموذجًا للكلام يسمى NaturalSpeech2. يعتمد هذا النموذج على تصميم "الانتشار المحتمل" وله نتائج رائعة على مستوى تركيب الكلام بدون عينة. تدعي Microsoft أن النموذج يوفر حلاً للكلام/الغناء "من الدرجة التجارية". للمستخدمين تجربة تركيب الكلام عالية الجودة ومتنوعة.
أجرت Microsoft سلسلة من العروض التوضيحية لـ NaturalSpeech2، لإثبات قدرتها على توليد الكلام بهويات المتحدث المختلفة، والعروض، والأساليب (مثل الغناء) في مواقف العينة الصفرية.
يُذكر أنه، على عكس أنظمة تحويل الكلام إلى نص (TTS) التقليدية، يستخدم نظام NaturalSpeech2 من Microsoft "ناقلات مستمرة" بدلاً من "العلامات المنفصلة" لتمثيل الكلام، وبالتالي إنشاء مقاطع كلام أكثر اكتمالاً وعدم إنتاج "قراءة ثابتة" أي " "خالية من العاطفة". (التحدث كلمة بكلمة) "ظاهرة.
تظهر النتائج التجريبية أن الكلام الناتج عن NaturalSpeech2 في ظل ظروف العينة الصفرية يتوافق تقريبًا مع نغمة مطالبات الكلام والكلام الحقيقي، ولا يمكن تمييز الطبيعة (المقاسة بواسطة CMOS) في مجموعات اختبار LibriTTS وVCTK عن الكلام الحقيقي.
الورقة البحثية لهذا المشروع منشورة حاليًا على GitHub
1. نموذج كبير تم إطلاقه رسميًا بواسطة Microsoft
2. ستجلب العديد من التفاعلات الجديدة الغنية للاعبين.
3. حاليا قيد التطوير المكثف، يرجى ترقبوا.