KaSA
1.0.0
[Ensembles de données de suivi des instructions synthétiques de haute qualité générés par GPT4O sur?]
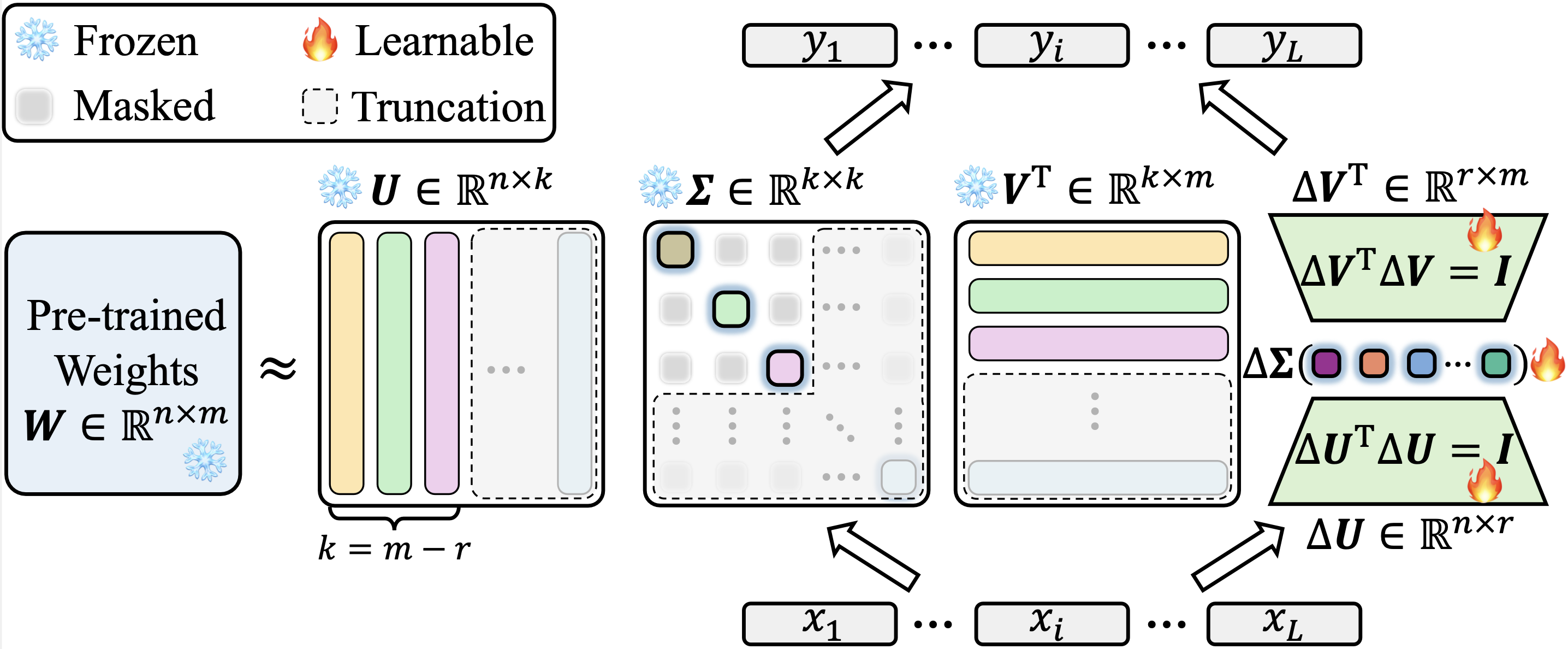
Nous mettons en œuvre notre Kasa sur Lora dans le référentiel PEFT du Face étreint officiel. Le code source de notre implémentation KASA peut être trouvé sur PEFT / SRC / PEFT / TUNERS / LORA / LAYER.PY. Il convient de noter que notre implémentation est anglophone en ce qui concerne la PEFT. Nous obtenons des résultats cohérents entre les dernières versions (0.13.1.Dev0) et plus anciennes (0,6.3.DEV0), évitant ainsi les gains dus aux différences de mise en œuvre.
Important
Si vous utilisez les données ou le code dans ce dépôt, veuillez envisager de citer l'article suivant:
@article { wang2024kasa ,
title = { KaSA: Knowledge-Aware Singular-Value Adaptation of Large Language Models } ,
author = { Wang, Fan and Jiang, Juyong and Park, Chansung and Kim, Sunghun and Tang, Jing } ,
journal = { arXiv preprint arXiv:2412.06071 } ,
year = { 2024 }
}conda create -n kasa python=3.10
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidia
# install peft with local folder
cd peft
pip install -e .
# note the version of packages
pip install datasets==2.21.0
pip install numpy==1.26.4
pip install scipy
pip install scikit-learn
pip install sentencepieceLe réglage fin des modèles communautaires HuggingFace pour la classification des séquences sur la référence General Language Comprendre l'évaluation (GLUE) implique de travailler avec 6 tâches différentes, notamment COLA, SST-2, MRPC, STS-B, QNLI et RTE. Les détails de l'ensemble de données se trouvent sur https://huggingface.co/datasets/nyu-mll/glue.
Voici un exemple de la façon de commencer la base de Roberta à réglage fin avec la tâche COLA:
cd runs
bash robert_base_cola.sh
où le contenu de robert_base_cola.sh est délimité dans les éléments suivants:
#! /bin/bash
cd ../
mkdir -p logs/roberta-base
# variables
CUDA_DEVICE=2
MODEL_NAME_OR_PATH= " roberta-base "
DATASET= " cola "
TASK= " cola "
BATCH_SIZE=32
MAX_LENGTH=512
NUM_EPOCH=100
HEAD_LR=4e-4
MODULE_LR=4e-4
LORA_R=8
LORA_ALPHA=16
LORA_DROPOUT=0.0
BETA=0.0001
GEMMA=0.001
SEED=0
WEIGHT_DECAY=0.0
# run
LOG_FILE= " logs/ ${MODEL_NAME_OR_PATH} / ${MODEL_NAME_OR_PATH} _ ${TASK} _bs_ ${BATCH_SIZE} _maxlen_ ${MAX_LENGTH} _lora_r_ ${LORA_R} _lora_alpha_ ${LORA_ALPHA} _lora_dropout_ ${LORA_DROPOUT} _modulelr_ ${MODULE_LR} _headlr_ ${HEAD_LR} _beta_ ${BETA} _gemma_ ${GEMMA} _weight_decay_ ${WEIGHT_DECAY} _seed_ ${SEED} .log "
CUDA_VISIBLE_DEVICES= $CUDA_DEVICE python main.py
--model_name_or_path $MODEL_NAME_OR_PATH
--dataset $DATASET
--task $TASK
--max_length $MAX_LENGTH
--bs $BATCH_SIZE
--lora_r $LORA_R
--lora_alpha $LORA_ALPHA
--lora_dropout $LORA_DROPOUT
--num_epoch $NUM_EPOCH
--head_lr $HEAD_LR
--module_lr $MODULE_LR
--beta $BETA
--gemma $GEMMA
--weight_decay $WEIGHT_DECAY
--seed $SEED 2>&1 | tee $LOG_FILEPour charger un modèle PEFT pour l'inférence:
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizer
import torch
model = AutoPeftModelForCausalLM . from_pretrained ( "saves/kasa/checkpoint-52580" ). to ( "cuda" )
tokenizer = AutoTokenizer . from_pretrained ( "saves/kasa/checkpoint-52580" )
model . eval ()
template = "### Context : {} n ### Completion : "
prompt = template . format ( "name : Blue Spice | Type : coffee shop | area : city centre" )
inputs = tokenizer ( prompt , return_tensors = "pt" )
outputs = model . generate ( input_ids = inputs [ "input_ids" ]. to ( "cuda" ), max_new_tokens = 50 )
print ( tokenizer . batch_decode ( outputs , skip_special_tokens = True )[ 0 ])
> "Blue Spice is a coffee shop located in the city centre." Conseil
Les journaux en cours d'exécution et les résultats de toutes nos expériences sont enregistrés dans le chemin des journaux . Ce qui suit est un exemple.
epoch 0: { ' matthews_correlation ' : 0.0} , current_best_corr: 0.0 train_loss: 0.5064952373504639
epoch 1: { ' matthews_correlation ' : 0.4528085001256977} , current_best_corr: 0.4528085001256977 train_loss: 0.2968645691871643
epoch 2: { ' matthews_correlation ' : 0.5314083843246411} , current_best_corr: 0.5314083843246411 train_loss: 0.3451506495475769
...
epoch 96: { ' matthews_correlation ' : 0.6331219341866674} , current_best_corr: 0.6581805893879898 train_loss: 0.057534683495759964
epoch 97: { ' matthews_correlation ' : 0.6206837048829764} , current_best_corr: 0.6581805893879898 train_loss: 0.057706814259290695
epoch 98: { ' matthews_correlation ' : 0.6281691768918801} , current_best_corr: 0.6581805893879898 train_loss: 0.05744687840342522
epoch 99: { ' matthews_correlation ' : 0.6256673855627156} , current_best_corr: 0.6581805893879898 train_loss: 0.0582236722111702model_name_or_path: roberta-base
dataset: cola
task: cola
peft: kasa
num_epochs: 100
bs: 32
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
head_lr: 0.0004
module_lr: 0.0004
max_length: 512
weight_decay: 0.0
warmup_ratio: 0.06
seed: 0
beta: 0.0001
gemma: 0.001
...
0% | | 0/33 [00: 00< ? , ? it/s]
9% | ▉ | 3/33 [00: 00< 00:01, 27.53it/s]
21% | ██ | 7/33 [00: 00< 00:00, 30.12it/s]
30% | ███ | 10/33 [00: 00< 00:00, 28.58it/s]
39% | ███▉ | 13/33 [00: 00< 00:00, 27.65it/s]
48% | ████▊ | 16/33 [00: 00< 00:00, 27.95it/s]
58% | █████▊ | 19/33 [00: 00< 00:00, 25.45it/s]
67% | ██████▋ | 22/33 [00: 00< 00:00, 25.99it/s]
76% | ███████▌ | 25/33 [00: 00< 00:00, 24.67it/s]
88% | ████████▊ | 29/33 [00: 01< 00:00, 25.53it/s]
100% | ██████████ | 33/33 [00: 01< 00:00, 27.68it/s]
100% | ██████████ | 33/33 [00: 01< 00:00, 27.01it/s]
epoch 99: { ' matthews_correlation ' : 0.6256673855627156}, current_best_corr: 0.6581805893879898 train_loss: 0.0582236722111702

