PRolice
v0.0.1 -
ooooooooo. ooooooooo. oooo o8o
`888 `Y88. `888 `Y88. `888 `"'
888 .d88' 888 .d88' .ooooo. 888 oooo .ooooo. .ooooo.
888ooo88P' 888ooo88P' d88' `88b 888 `888 d88' `"Y8 d88' `88b
888 888`88b. 888 888 888 888 888 888ooo888
888 888 `88b. 888 888 888 888 888 .o8 888 .o
o888o o888o o888o `Y8bod8P' o888o o888o `Y8bod8P' `Y8bod8P'
------------ What you gonna do when they come for you -------------
Prolice (contraction de la police des relations publiques ) est un outil de gestion de l'ingénierie pour abandonner et mesurer les données de demande de traction des référentiels GitHub.
Criant à Sourcelevel et à leur excellent blog sur les mesures (dont la plupart sont implémentées par cette application):
De nombreux directeurs d'ingénierie font la promotion des demandes de traction dans le cadre du flux de travail de développement. C'est une pratique consolidée qui apporte de nombreux avantages. Il consiste à comparer les changements d'une branche avec la branche de base du référentiel (conventionnellement appelé maître).
Les demandes de traction fournissent des mesures utiles et exploitables. Cependant, suivre les mauvaises mesures provoque des distorsions et provoquer plus d'inconvénients que les avantages. Les managers peuvent utiliser des mesures de demande de traction pour comprendre la dynamique de l'équipe et agir de manière appropriée pour corriger les comportements avant que les choses ne se déplacent de la piste.
Prolice vise à collecter un échantillon de demandes de traction d'un référentiel cible et à les analyser, dans le but d'apporter des informations dans le flux de travail du projet collectif au fil du temps.
Criant à nouveau au blog de Sourcelevel (sérieusement, lisez-le si vous ne l'avez pas déjà fait):
Avant d'entrer dans les mesures, je veux faire un avertissement: n'utilisez pas ces chiffres pour comparer les individus .
Parfois, un bogue difficile à trouver nécessite une seule ligne de code pour être corrigé, et cette ligne unique a pris une semaine de travail. J'en ai été témoin plusieurs fois dans ma carrière.
J'ai également vu des directeurs d'ingénierie encourageant les développeurs à ouvrir les demandes de traction avec trop de changements qu'il n'était pas pratique de revoir. Ils renforcent généralement qu'en disant à tout le monde que ces développeurs sont productifs, qu'ils font le travail difficile lorsque les autres prennent les plus faciles.
La mesure des individus par le biais de demandes de traction peut même être injuste. Un développeur dédié au maintien d'une base de code héritée a tendance à être plus lent qu'un autre, qui fonctionne sur un projet Greenfield.
C'est pourquoi la mesure des demandes de traction est délicate. Les directeurs d'ingénierie ne peuvent pas utiliser les données de demande Pull pour les individus. Si vous tirez des demandes, vous voulez que votre équipe collabore. Dans cette pratique, la collaboration est la valeur fondamentale. L'effort des développeurs ne peut pas être mesuré uniquement par le nombre de demandes de traction ouvertes ou fusionnées. Pire encore, l'effort ne représente pas sa taille.
Tout d'abord, vous devrez créer un jeton d'accès personnel. Il s'agit d'une exigence unique et ne devrait pas prendre plus de quelques minutes.
Le jeton devra avoir lu l'accès aux référentiels et aux demandes de traction afin que le prolice fonctionne. Quelque chose comme ça:
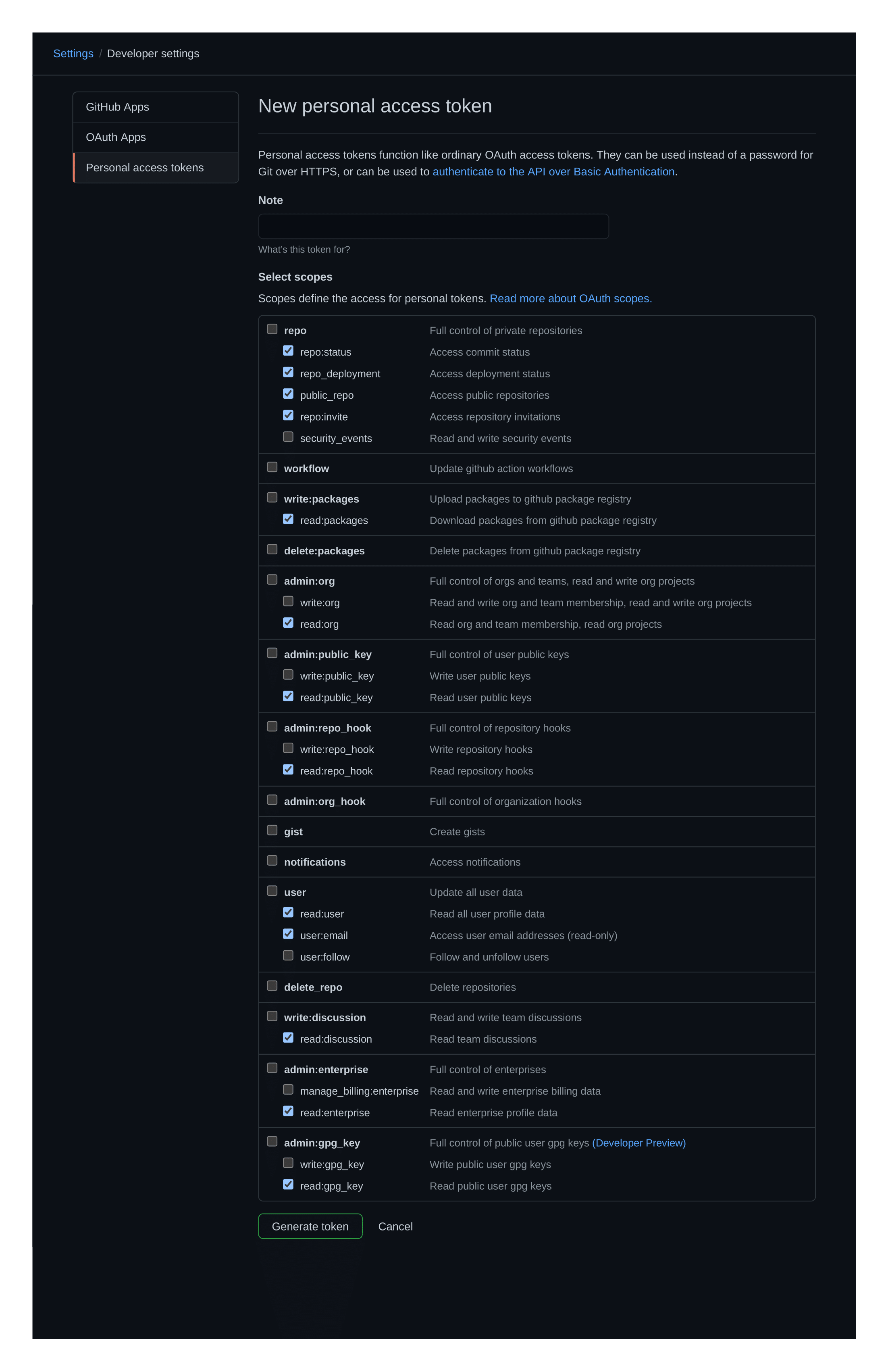
Avec votre jeton d'accès personnel disponible, et après avoir téléchargé un binaire à partir de la section des versions, invoquez le prolice dans votre terminal préféré de choix - actuellement Linux et MacOS (Darwin) sont pris en charge:
prolice --owner < owner > --repository < repository > --github-token < github-token >Par exemple, si nous voulions mesurer les métriques officielles du référentiel de Rust ( Remarque : Cela par défaut est un échantillon de 100 PR):
prolice --owner rust-lang --repository rust --github-token < github-token >Les mesures de relations publiques individuelles sont également prises en charge:
prolice --owner rust-lang --repository rust --pr-number 32000 --github-token < github-token > Prolice 's a quelques drapeaux et paramètres facultatifs qui peuvent être utilisés pour ajuster sa verbosité et sa taille d'échantillon:
prolice --helpUSAGE:
prolice [FLAGS] [OPTIONS] --owner < owner > --repository < repository > --sample-size < sample-size > --github-token < github-token >
FLAGS:
-h, --help Prints help information
-m, --include-merge-prs Marks merge-PRs as valid targets for analysis (by default these are
excluded). Valid only for whole Repository analysis ; for individual
PR analysis this flag is ignored
-l, --print-legends Prints the metrics ' legends before sending the operation results to
stdout.
-s, --silent-mode Marks the operation as silent, which turns off all logging and
printing to stdout, with the sole exception of the analysis results.
This makes it useful for piping just the results, without the added
' noise ' . (NOTE: piping is automatically detected, which activates
silent-mode without having to explicitly add the flag to the command)
-V, --version Prints version information
OPTIONS:
-G, --github-token <github-token>
Sets the personal access token under which to perform the PR analysis
-L, --log-level <log-level>
Overrides the logging verbosity for the whole application [default: INFO] [possible
values: INFO, DEBUG, TRACE, WARN, ERROR, OFF]
-O, --owner <owner> The owner of the repository under scrutiny
-P, --pr-number <pr-number>
A specific pull-request to be selected as target for the analysis.
-R, --repository <repository> The repository under scrutiny
-S, --sample-size <sample-size>
The amount of PRs that will be fetched as sample for the analysis (unless a specific PR
number is selected as individual target) [default: 100]Les résultats de Prolice peuvent être tués dans un fichier. La tuyauterie (ou toute absence de TTY) est automatiquement détectée par l'application, ce qui désactivera tous les journaux et messages, même si l'utilisateur n'a pas fourni ces indicateurs dans le cadre de la commande. Ceci est utile pour obtenir des résultats bruts qui peuvent être introduits dans un autre processus.
Par exemple:
prolice --owner rust-lang --repository rust --github-token < github-token > >> results.json produira un fichier results.json avec le contenu suivant (au moment de la rédaction de ce lecture):
{
"score" : [
{
"AmountOfParticipants" : 4
},
{
"AmountOfReviewers" : 1
},
{
"Attachments" : 1
},
{
"AuthorCommentaryToChangesRatio" : 31.138690476190472
},
{
"PullRequestsDiscussionSize" : 4065
},
{
"PullRequestFlowRatio" : 1.9121686296350902
},
{
"PullRequestLeadTime" : 1
},
{
"PullRequestSize" : 255
},
{
"TestToCodeRatio" : 0.42988095238095236
},
{
"TimeToMerge" : 4
}
]
} Ce que chaque métrique «signifie» (alias pourquoi il est utile de mesurer) peut être imprimé dans le cadre des résultats de l'analyse en passant le drapeau --print-legends . Pourtant, cela peut polluer le terminal avec une verbosité excessive; Donc, pour référence, ce sont la signification de chaque métrique:
AmountOfParticipantsLe nombre de personnes non autorisées participant à une discussion de RP. Une plus grande participation peut enrichir la discussion et produire du code de meilleure qualité.
AmountOfReviewersLe montant des personnes non autorisées qui ont pris position sur les résultats d'un RP, soit en approuvant, soit en demandant des modifications. Cela mesure le nombre de participants qui décident efficacement du sort d'un RP.
AttachmentsLes pièces jointes peuvent être quelque chose allant des captures d'écran ajoutées aux fichiers PDF intégrés. Particulièrement utile pour les PR qui ont un composant visuel associé.
AuthorCommentaryToChangesRatioUn bon code devrait être explicite; Mais un bon RP peut également inclure des commentaires supplémentaires sur ce qu'il vise à réaliser, comment il le fait et / ou pourquoi il le fait à la manière choisie.
Un commentaire mince peut faire un RP ambigu, déplacer le fardeau de la compréhension de l'examinateur et consommer du temps supplémentaire. D'un autre côté, trop de commentaires peuvent polluer un RP avec un bruit inutile, au même effet.
PullRequestsDiscussionSizeSemblable au rapport des commentaires / changements de l'auteur, il mesure la quantité totale de commentaires dans un RP, mais indépendamment de qui ils viennent. Au contraire des publications sur les réseaux sociaux, trop d'engagement dans les demandes de traction entraîne une inefficacité. La mesure du nombre de commentaires et de réactions pour chaque demande de traction donne une idée de la façon dont l'équipe collabore. La collaboration est excellente et son approbation est quelque chose à désirer. Cependant, après un certain niveau, les discussions ralentissent le développement.
Les discussions qui deviennent trop grandes peuvent être révélatrices de quelque chose qui ne va pas: peut-être que l'équipe n'est pas alignée, ou peut-être que les exigences logicielles ne sont pas assez précises. En tout cas, le désalignement dans les discussions n'est pas une collaboration; Ils sont une perte de temps. Dans le scénario opposé, avoir presque zéro engagement signifie que l'examen du code ne fait pas partie des habitudes de l'équipe.
En résumé, cette métrique doit atteindre un «numéro idéal» en fonction de la taille et de la distribution de l'équipe. Ça ne peut pas être trop, et ça ne peut pas être trop peu non plus.
PullRequestFlowRatioLe rapport de flux de demande de traction est la somme des demandes de traction ouvertes en une journée divisée par la somme des demandes de traction fermées le même jour. Cette métrique montre si l'équipe travaille dans une proportion saine. La fusion des demandes de traction et le déploiement en production est une bonne chose, car elle ajoute de la valeur à l'utilisateur final. Cependant, lorsque l'équipe ferme plus de demandes de traction que l'ouverture, la file d'attente de la demande de traction affirme bientôt qu'il peut y avoir un hiatus dans la livraison. Idéalement, il est préférable de s'assurer que l'équipe fusionne les demandes de traction dans un ratio aussi près qu'ils s'ouvrent; Plus près de 1: 1, mieux c'est.
PullRequestLeadTimeLa métrique à temps de livraison donne une idée du nombre de fois (généralement en jours) que les demandes de traction mettent pour être fusionnée ou fermée. Pour trouver ce numéro, la date et l'heure pour chaque demande de traction lors de l'ouverture, puis la fusion, est nécessaire. La formule est facile: une moyenne simple pour la différence de dates. Le calcul de cette métrique dans tous les référentiels d'une organisation peut donner à une équipe une idée plus claire de sa dynamique.
PullRequestSizeUne grande quantité de changements par PR impose une pression sur le critique, qui voit son attention aux détails, plus le plus gros a Changelog. Ironiquement, les développeurs ont tendance à fusionner les demandes de traction plus longues plus rapidement que les plus courtes, car il est plus difficile d'effectuer des critiques approfondies quand il y a trop de choses. Indépendamment de la façon dont les avis sont approfondis, les grands RP conduisent au temps de fusionner et que la qualité baisse.
TestToCodeRatioEn règle générale, au moins la moitié d'un RP devrait être composé de tests chaque fois que possible.
TimeToMergeEn général, les demandes de traction sont ouvertes avec certains travaux en cours, ce qui signifie que la mesure du délai de livraison des demandes de traction ne raconte pas toute l'histoire. Le temps de fusionner est le temps qu'il faut pour que le premier engagement d'une succursale atteigne la branche cible. Dans la pratique, les mathématiques sont simples: c'est l'horodatage du plus ancien engagement d'une branche moins l'horodatage du commit de fusion.
Le délai de fusion est généralement utile lorsqu'il est comparé au délai de livraison de la demande de traction. Prenez l'exemple suivant:
- Tirez le délai de livraison = 3 jours
- Il est temps de fusionner = 15 jours
Dans le scénario ci-dessus, une demande de traction a pris un délai moyen de 3 jours pour être fusionnée (ce qui est assez bon); Mais le temps de fusion était de 15 jours. Ce qui signifie que les développeurs ont travaillé en moyenne 12 jours (15 à 3) avant d'ouvrir une demande de traction.
Remarque: Cette métrique est rendue quelque peu obsolète si les développeurs travaillent sur les succursales WIP avant d'écraser toutes les modifications en un seul engagement qui est ensuite utilisé comme base pour le PR (cela prendrait le temps de fusionner efficacement égal au délai de trait de la demande de traction). Cependant, la métrique reste incroyablement utile pour fusionner les PR (par exemple, la fusion de développement en maître): ledit PRS aurait un délai de livraison de demande de traction très courte (ils n'obtiennent pas de révisions approfondies), mais mesurer contre la date du premier engagement (le temps de fusion) indiquera combien de temps il s'agit de fonctionnalités.
cargo Le prolice est écrit en rouille. La compilation de l'application d'utilisation dans la plate-forme hôte est aussi simple que l'utilisation cargo build simples:
cargo build --releasecargo-make (linux vers macOS)Permet d'abord cette section avec une petite préface de ce blog génial:
Je déteste la compilation croisée
Il existe des millions de façons de ruiner le système d'exploitation sur lequel vous travaillez et la compilation croisée en fait partie. Il commence normalement par l'idée innocente de faire fonctionner cette chaîne de construction, vous avez besoin d'un petit programme pour fonctionner sur un Linksys WRT 1900 ACS (OpenWRT et ARMV7).
Cire autour de vous trouvez plusieurs extraits différents sur Reddit ou un problème dans un projet GitHub où une personne aléatoire a publié quelques lignes de bash qui ressemblent à ce peu d'informations manquantes dont vous aviez besoin.
Rouler le bash peut alors provoquer l'une des choses suivantes:
- Créer une chaîne de construction de travail (très peu probable)
- Créer une chaîne de construction qui échoue après 80% de votre construction
- Ajouter un mineur Bitcoin local tout en faisant semblant de créer une chaîne de construction de travail
Ayant ressenti ces douleurs à un niveau personnel, la compilation croisée a été mise à disposition à un niveau relativement sans douleur par les cibles définies à l'intérieur de la cargaison de cargaison cargo-makefile.toml .
Bien sûr, si la compilation uniquement pour la machine hôte, s'en tenir à cargo build simples est toujours le premier choix. Mais en supposant que l'objectif était de compiler de Linux à MacOS (Darwin) à partir de zéro, en plus de la chaîne d'outils de rouille normale dont vous auriez besoin pour installer cargo-make comme ceci:
cargo install --force cargo-makeEnsuite, les étapes de compilation sont complètement prises en charge pour vous en invoquant:
cargo make --makefile cargo-makefile.toml release-darwinCela créerait et placerait, une fois le processus terminé, le binaire comprimé à:
<your_dir>/target/release/out/prolice_x86_64-apple-darwin.zip
Tenez compte du fait que Linux-to-Darwin, linux-to-darwin, nécessite Docker, vous pouvez donc encore vous épargner plusieurs MB en vous en colliant pour construire des binaires pour votre machine hôte en invoquant simplement une vieille cargo build ordinaire.


