PRolice
v0.0.1 -
ooooooooo. ooooooooo. oooo o8o
`888 `Y88. `888 `Y88. `888 `"'
888 .d88' 888 .d88' .ooooo. 888 oooo .ooooo. .ooooo.
888ooo88P' 888ooo88P' d88' `88b 888 `888 d88' `"Y8 d88' `88b
888 888`88b. 888 888 888 888 888 888ooo888
888 888 `88b. 888 888 888 888 888 .o8 888 .o
o888o o888o o888o `Y8bod8P' o888o o888o `Y8bod8P' `Y8bod8P'
------------ What you gonna do when they come for you -------------
Prolice (contracción de la policía de PR ) es una herramienta de gestión de ingeniería para desechar y medir los datos de solicitud de extracción de los repositorios de GitHub.
Gritando a Sourcelevel y su excelente blog sobre métricas (la mayoría de los cuales son implementados por esta aplicación):
Muchos gerentes de ingeniería promueven solicitudes de extracción como parte del flujo de trabajo de desarrollo. Es una práctica consolidada que trae muchos beneficios. Consiste en comparar los cambios de una rama con la rama base del repositorio (convencionalmente llamado maestro).
Las solicitudes de extracción proporcionan métricas útiles y procesables. Sin embargo, seguir las métricas incorrectas causan distorsiones y traen más desventajas que los beneficios. Los gerentes pueden usar métricas de solicitudes de extracción para comprender la dinámica del equipo y actuar adecuadamente para corregir los comportamientos antes de que las cosas se salgan de la pista.
Prolice tiene como objetivo recopilar una muestra de solicitudes de extracción de un repositorio de objetivos y analizarlas, con el objetivo de aportar información sobre el flujo de trabajo del proyecto colectivo con el tiempo.
Nuevamente gritando a BlogPost de Sourcelevel (en serio, léelo si aún no lo ha hecho):
Antes de entrar en las métricas, quiero hacer un descargo de responsabilidad: no use estos números para comparar individuos .
A veces, un error difícil de encontrar requiere que se solucione una sola línea de código, y esa línea única tomó una semana de trabajo. Lo he sido testigo muchas veces en mi carrera.
También he sido testigo de gerentes de ingeniería alentar a los desarrolladores a abrir solicitudes de extracción con demasiados cambios que no era práctico revisar. Por lo general, reforzan eso diciéndole a todos estos desarrolladores son productivos, que están haciendo el trabajo duro cuando otros están tomando los más fáciles.
Medir a las personas a través de solicitudes de atracción puede incluso ser injusto. Un desarrollador dedicado a mantener una base de código heredado tiende a ser más lento que otro, que funciona en un proyecto de Greenfield.
Es por eso que medir las solicitudes de extracción es complicado. Los gerentes de ingeniería no pueden usar los datos de solicitud de extracción para las personas. Si extrae solicitudes, entonces desea que su equipo colabore. En esta práctica, la colaboración es el valor central. El esfuerzo de los desarrolladores no se puede medir solo por cuántas solicitudes de extracción están abiertas o fusionadas. Aún lo peor, el esfuerzo no representa su tamaño.
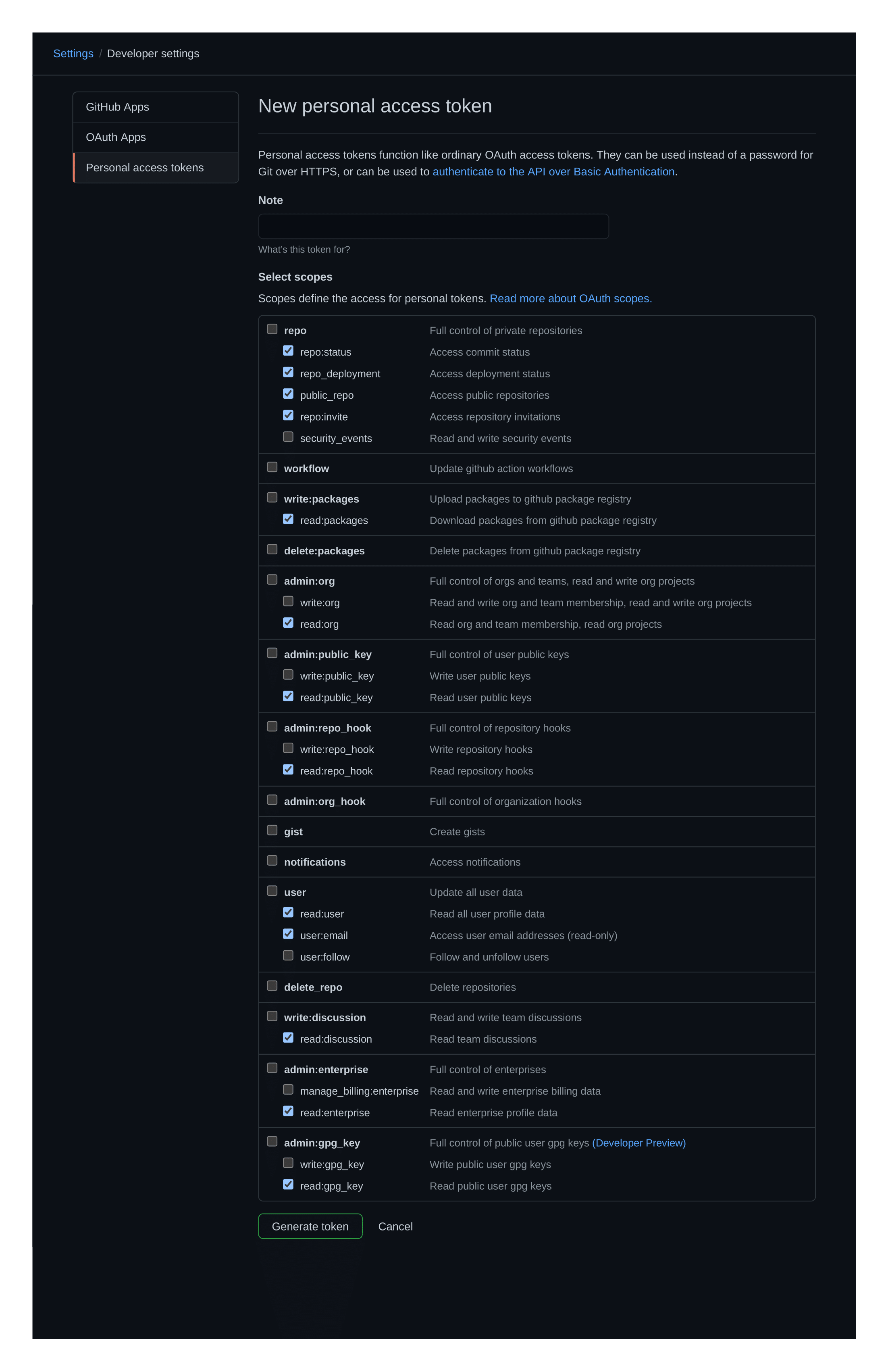
Lo primero es lo primero, tendrá que crear un token de acceso personal. Este es un requisito único y no debería tomar más de un par de minutos.
El token necesitará tener acceso de lectura a repositorios y solicitudes de extracción para que el prolice funcione. Algo como esto:
Con su token de acceso personal disponible, y habiendo descargado un binario de la sección de versiones, Invoke Prolice dentro de su terminal favorito de elección, actualmente se admiten Linux y MacOS (Darwin):
prolice --owner < owner > --repository < repository > --github-token < github-token >Por ejemplo, si queríamos medir las métricas del repositorio oficial de Rust ( nota : este valor predeterminado a una muestra de 100 PR):
prolice --owner rust-lang --repository rust --github-token < github-token >Las métricas de relaciones públicas individuales también son compatibles:
prolice --owner rust-lang --repository rust --pr-number 32000 --github-token < github-token > PROLICE 's tiene un par de banderas y parámetros opcionales que se pueden usar para ajustar su verbosidad y tamaño de la muestra:
prolice --helpUSAGE:
prolice [FLAGS] [OPTIONS] --owner < owner > --repository < repository > --sample-size < sample-size > --github-token < github-token >
FLAGS:
-h, --help Prints help information
-m, --include-merge-prs Marks merge-PRs as valid targets for analysis (by default these are
excluded). Valid only for whole Repository analysis ; for individual
PR analysis this flag is ignored
-l, --print-legends Prints the metrics ' legends before sending the operation results to
stdout.
-s, --silent-mode Marks the operation as silent, which turns off all logging and
printing to stdout, with the sole exception of the analysis results.
This makes it useful for piping just the results, without the added
' noise ' . (NOTE: piping is automatically detected, which activates
silent-mode without having to explicitly add the flag to the command)
-V, --version Prints version information
OPTIONS:
-G, --github-token <github-token>
Sets the personal access token under which to perform the PR analysis
-L, --log-level <log-level>
Overrides the logging verbosity for the whole application [default: INFO] [possible
values: INFO, DEBUG, TRACE, WARN, ERROR, OFF]
-O, --owner <owner> The owner of the repository under scrutiny
-P, --pr-number <pr-number>
A specific pull-request to be selected as target for the analysis.
-R, --repository <repository> The repository under scrutiny
-S, --sample-size <sample-size>
The amount of PRs that will be fetched as sample for the analysis (unless a specific PR
number is selected as individual target) [default: 100]Los resultados de PROLice se pueden canalizar a un archivo. La aplicación detecta automáticamente la tubería (o cualquier ausencia de un TTY), que apagará todos los registros y mensajes, incluso si el usuario no proporcionó estos indicadores como parte del comando. Esto es útil para obtener resultados en bruto que pueden alimentarse en otro proceso.
Por ejemplo:
prolice --owner rust-lang --repository rust --github-token < github-token > >> results.json producirá un archivo results.json con los siguientes contenidos (al momento de escribir este readMe):
{
"score" : [
{
"AmountOfParticipants" : 4
},
{
"AmountOfReviewers" : 1
},
{
"Attachments" : 1
},
{
"AuthorCommentaryToChangesRatio" : 31.138690476190472
},
{
"PullRequestsDiscussionSize" : 4065
},
{
"PullRequestFlowRatio" : 1.9121686296350902
},
{
"PullRequestLeadTime" : 1
},
{
"PullRequestSize" : 255
},
{
"TestToCodeRatio" : 0.42988095238095236
},
{
"TimeToMerge" : 4
}
]
} Lo que cada métrica "significa" (también conocido como por qué es valioso medir) puede imprimirse como parte de los resultados del análisis al pasar la bandera --print-legends . Aún así, eso puede contaminar el terminal con verbosidad excesiva; Entonces, como referencia, estos son el significado de cada métrica:
AmountOfParticipantsLa cantidad de personas que no son autores que participan en una discusión de relaciones públicas. Una mayor participación puede enriquecer la discusión y producir un código de mayor calidad.
AmountOfReviewersLa cantidad de personas que no están autorizadas que han tomado una posición sobre el resultado de un PR, ya sea aprobando o solicitando cambios. Esto mide la cantidad de participantes que deciden efectivamente sobre el destino de un PR.
AttachmentsLos archivos adjuntos pueden ser cualquier cosa que varíe desde capturas de pantalla agregadas hasta archivos PDF integrados. Particularmente útil para aquellos PR que tienen un componente visual asociado.
AuthorCommentaryToChangesRatioEl buen código debe explicarse por sí mismo; Pero un buen PR también puede incluir comentarios adicionales sobre lo que pretende lograr, cómo lo hace y/o por qué lo hace de la manera elegida.
Un comentario delgado puede ser un PR ambiguo, cambiando la carga de la comprensión al revisor y consumiendo tiempo extra de él. Por otro lado, demasiados comentarios pueden contaminar un PR con ruido innecesario, con el mismo efecto.
PullRequestsDiscussionSizeSimilar a la relación de comentarios a cambios del autor, mide la cantidad total de comentarios en un PR, pero independientemente de de quién provienen. Por el contrario de las publicaciones en las redes sociales, demasiado compromiso en las solicitudes de extracción conduce a la ineficiencia. La medición del número de comentarios y reacciones para cada solicitud de extracción da una idea de cómo colabora el equipo. La colaboración es excelente, y su respaldo es algo que se puede desear. Sin embargo, después de un cierto nivel, las discusiones ralentizan el desarrollo.
Las discusiones que se vuelven demasiado grandes pueden ser indicativas de algo mal: tal vez el equipo no está alineado, o tal vez los requisitos de software no son lo suficientemente precisos. En cualquier caso, la desalineación en las discusiones no es colaboración; Son una pérdida de tiempo. En el escenario opuesto, tener casi cero compromiso significa que la revisión del código no es parte de los hábitos del equipo.
En resumen, esta métrica debe alcanzar un "número ideal" basado en el tamaño y la distribución del equipo. No puede ser demasiado, y tampoco puede ser muy poco.
PullRequestFlowRatioLa relación de flujo de solicitud de extracción es la suma de las solicitudes de extracción abiertas en un día dividido por la suma de las solicitudes de extracción cerradas en ese mismo día. Esta métrica muestra si el equipo trabaja en una proporción saludable. Fusionar solicitudes de extracción e implementar a la producción es algo bueno, ya que agrega valor al usuario final. Sin embargo, cuando el equipo cierra más solicitudes de extracción de las que se abre, pronto la cola de solicitud de extracción de hambre, lo que significa que puede haber una pausa en la entrega. Idealmente, es mejor asegurarse de que el equipo fusione las solicitudes de extracción en una proporción tan cerca como se abren; Cuanto más cerca de 1: 1, mejor.
PullRequestLeadTimeLa métrica de tiempo de entrega da una idea de cuántas veces (generalmente en días) las solicitudes de atracción se necesitan para ser fusionadas o cerradas. Para encontrar este número, se necesita la fecha y la hora para cada solicitud de extracción cuando se abren y luego se fusionan. La fórmula es fácil: un promedio simple para la diferencia de fechas. Calcular esta métrica en todos los repositorios en una organización puede dar a un equipo una idea más clara de su dinámica.
PullRequestSizeUna gran cantidad de cambios por PR impone una tensión en el revisor, quien ve que su atención al detalle disminuyó cuanto más grande se vuelve un cambio de cambio. Irónicamente, los desarrolladores tienden a fusionar las solicitudes más largas más rápidas que las más cortas, ya que es más difícil realizar críticas exhaustivas cuando hay demasiadas cosas sucediendo. Independientemente de cuán exhaustivas sean las revisiones, los grandes PR conducen al tiempo para fusionarse y la calidad bajando.
TestToCodeRatioComo regla general, al menos la mitad de un PR debe estar compuesto por pruebas siempre que sea posible.
TimeToMergeEn general, las solicitudes de extracción están abiertas con algún trabajo en progreso, lo que significa que medir el tiempo de entrega de solicitudes de extracción no cuenta toda la historia. El tiempo para fusionar es cuánto tiempo tarda en el primer compromiso de una rama para llegar a la rama objetivo. En la práctica, las matemáticas son simples: es la marca de tiempo del compromiso más antiguo de una rama menos la marca de tiempo de la fusión.
El tiempo para fusionarse suele ser útil mientras se compara con el tiempo de entrega de la solicitud de extracción. Tome el siguiente ejemplo:
- Tiempo de entrega de solicitud de retiro = 3 días
- Tiempo de fusionar = 15 días
En el escenario anterior, una solicitud de extracción tardó un tiempo promedio de 3 días en fusionarse (lo cual es bastante bueno); Pero el tiempo para fusionarse fue de 15 días. Lo que significa que los desarrolladores trabajaron un promedio de 12 días (15 - 3) antes de abrir una solicitud de extracción.
NOTA: Esta métrica se vuelve algo obsoleta si los desarrolladores trabajan en ramas WIP antes de aplastar todos los cambios en un solo confirmación que luego se usa como base para el PR (esto haría el tiempo de fusionarse efectivamente igual al tiempo de entrega de solicitud de solicitud). Sin embargo, la métrica sigue siendo increíblemente útil para fusiones de PRS (por ejemplo, fusionar convertirse en maestro): dijo que los PRS tendrían un tiempo de entrega de solicitud muy corto (no obtienen una revisión exhaustiva), pero la medición de la fecha de la primera comisión (hora de fusionar) dirá cuánto tiempo tarda en acumularse en un hito lo suficientemente digna de merecer una de las 'ramas' grandes '.
cargo Prolice está escrito en óxido. Compilar la aplicación de uso en la plataforma de host es tan fácil como usar cargo build simple:
cargo build --releasecargo-make (Linux a macOS)Comencemos primero esta sección con un pequeño prefacio de esta increíble publicación de blog:
Odio la compilación cruzada
Hay millones de formas de arruinar el sistema operativo en el que está trabajando y la compilación cruzada es una de ellas. Normalmente comienza con la idea inocente de obtener esa cadena de construcción que necesita para que un pequeño programa se ejecute en un Linksys WRT 1900 ACS (OpenWRT y ARMV7).
Cavando a su alrededor, encuentre varios fragmentos diferentes en Reddit o algún problema en un proyecto de GitHub donde una persona al azar publicó algunas líneas de Bash que parecen solo esa información que necesitaba.
Ejecutar la fiesta puede causar una de las siguientes cosas:
- Crea una cadena de construcción de trabajo (muy poco probable)
- Cree una cadena de compilación que falle después del 80% de su construcción
- Agregue un minero bitcoin local mientras finge crear una cadena de construcción de trabajo
Habiendo sentido estos dolores a nivel personal, la compilación cruzada se ha puesto a disposición en un nivel relativamente libre de dolor por los objetivos definidos dentro de la carga cargo-makefile.toml de carga de este proyecto.
Por supuesto, si se compila solo para la máquina host, quedarse con cargo build simple siempre es la primera opción. Pero suponiendo que el objetivo era compilar de Linux a MacOS (Darwin) desde cero, además de la cadena de herramientas de óxido normal, necesitaría instalar cargo-make como esta:
cargo install --force cargo-makePosteriormente, los pasos de compilación se cuidan por completo invocando:
cargo make --makefile cargo-makefile.toml release-darwinEsto crearía y colocaría, después de que se termine el proceso, el binario comprimido en:
<your_dir>/target/release/out/prolice_x86_64-apple-darwin.zip
Sin embargo, tenga en cuenta que Linux-to-Darwin de compilación cruzada requiere Docker, por lo que una vez más puede ahorrarse varios MB en binarios de construcción para su máquina anfitriona simplemente invocando cargo build antigua.


