E Commerce_ChatBot
1.0.0
Ce projet est un chatbot de commerce électronique construit à l'aide d'une approche de génération (RAG) (RAG) de récupération . RAG combine la puissance de la recherche d'informations et des modèles de langage génératif, permettant au chatbot de fournir des réponses précises et consacrées au contexte basées sur des informations liées au produit approfondies stockées dans une base de données vectorielle. Nous avons utilisé Langchain comme cadre pour gérer les composants du chatbot et orchestrer efficacement le flux de génération de récupération.
Le chatbot utilise LLAMA3.1-8b , un modèle grand langage connu pour sa capacité à comprendre le contexte nuancé et à générer des réponses cohérentes. Pour améliorer les performances de récupération, le projet exploite les intégres générés par le modèle de phrase de phrase / All-MPNET-Base-V2 de HuggingFace. Ces intérêts codent la signification sémantique, permettant au chatbot de récupérer rapidement les données de produit pertinentes en fonction des requêtes utilisateur. Les intérêts sont stockés et gérés dans Astradb , qui sert de base de données vectorielle haute performance.
Pour fournir des réponses cohérentes et consacrées au contexte, le chatbot utilise une approche de chiffon compatible l'histoire. En incorporant l'historique du chat dans chaque interaction, le modèle peut comprendre les références aux messages précédents et maintenir la continuité à travers plusieurs tours. Les fonctionnalités de gestion de l'historique de Langchain rendent ce processus sans couture en permettant à la gestion avec état de l'historique de chat pour chaque session d'utilisateur.
L' ensemble de données utilisé dans ce projet comprend des revues de produits provenant de Flipkart , une plate-forme de commerce électronique. L'ensemble de données comprend des titres de produits, des notes et des avis détaillés, offrant une vue complète des commentaires des clients sur divers produits. L'objectif principal de cet ensemble de données est d'alimenter les capacités de récupération du chatbot, ce qui lui permet de référencer les sentiments, les fonctionnalités et les expériences des clients du monde réel. Chaque revue est stockée comme un objet de document dans Langchain , contenant la revue comme contenu et le nom du produit sous forme de métadonnées. L' ensemble de données est ingéré dans Astradb en tant que magasin vectoriel, permettant des recherches de similitude qui correspondent aux requêtes des utilisateurs avec des critiques pertinentes, améliorant les recommandations et les réponses du chatbot.
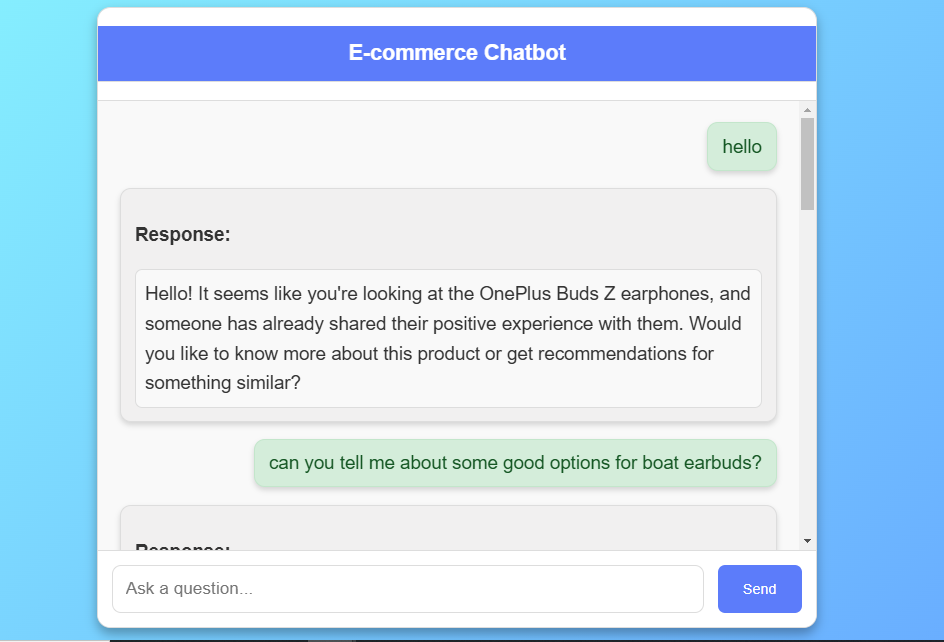
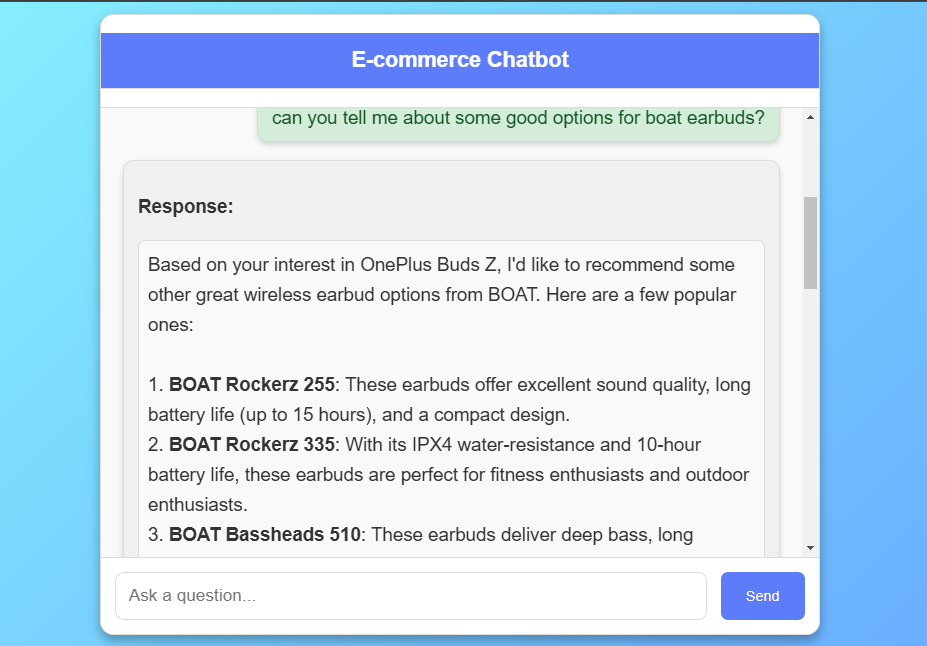
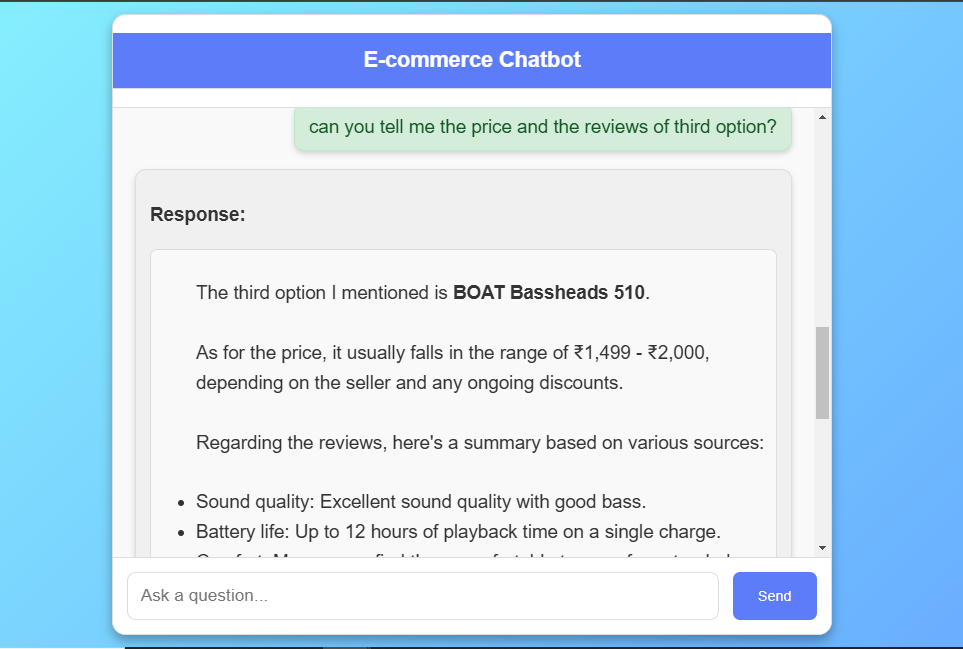
Le frontend est une interface Web réactive créée à l'aide de HTML , CSS et JavaScript , conçue pour fournir une expérience de chat intuitive. Les utilisateurs peuvent interagir avec le chatbot pour se renseigner sur les détails du produit et recevoir des recommandations personnalisées. L'interface est stylée avec CSS , avec un fond de gradient moderne et une boîte de chat structurée où les messages utilisateur et les réponses BOT sont affichés en temps réel.
Compte tenu de la grande taille du modèle, la génération de réponses avec LLAMA 3.1-8b peut parfois dépasser la limite de délai d'expiration du serveur par défaut d'une minute . Pour gérer cela, nous avons implémenté Redis en tant que courtier de messages et céleri pour la gestion des tâches d'arrière-plan. Lorsqu'un utilisateur soumet une requête, le chatbot déclenche une tâche de céleri qui traite la réponse de manière asynchrone , permettant au frontend de sonder périodiquement pour l'état de réponse. Cette méthode empêche efficacement les erreurs de délai d'expiration du serveur tout en garantissant que les utilisateurs reçoivent des réponses sans interruptions.
Le chatbot est déployé sur AWS EC2 , fournissant un environnement évolutif et robuste pour exécuter le modèle, gérer les interactions utilisateur et gérer les récupérations à partir de la base de données.
L'ensemble de données de ce projet est tiré de Kaggle. Voici le lien de l'ensemble de données. L'ensemble de données utilisé dans ce projet contient 450 avis de produits sur différentes marques d'écouteurs, Erabuds et autres collectés auprès de Flipkart, y compris les caractéristiques clés suivantes:
Nom de l'ensemble de données: flipkart_dataset Nombre de colonnes: 5 Nombre d'enregistrements: 450
Le code est écrit dans Python 3.10.15. Si vous n'avez pas installé Python, vous pouvez le trouver ici. Si vous utilisez une version inférieure de Python, vous pouvez mettre à niveau à l'aide du package PIP, en vous assurant de la dernière version de PIP.
git clone https://github.com/jatin-12-2002/E-Commerce_ChatBot cd E-Commerce_ChatBotconda create -p env python=3.10 -y source activate ./envpip install -r requirements.txtASTRA_DB_API_ENDPOINT= " "
ASTRA_DB_APPLICATION_TOKEN= " "
ASTRA_DB_KEYSPACE= " "
HF_TOKEN= " "curl -fsSL https://ollama.com/install.sh | shollama serveollama pull llama3.1:8bsudo apt-get updatesudo apt-get install redis-serversudo service redis-server startredis-cli pingcelery -A app.celery worker --loglevel=infogunicorn -w 2 -b 0.0.0.0:8000 app:apphttp://localhost:8000/
Use t2.large or greater size instances only as it is a GenerativeAI using LLMs project.sudo apt-get updatesudo apt update -ysudo apt install git nginx -ysudo apt install git curl unzip tar make sudo vim wget -ygit clone https://github.com/jatin-12-2002/E-Commerce_ChatBot cd E-Commerce_ChatBottouch .envvi .envASTRA_DB_API_ENDPOINT= " "
ASTRA_DB_APPLICATION_TOKEN= " "
ASTRA_DB_KEYSPACE= " "
HF_TOKEN= " "cat .envsudo apt install python3-pippip3 install -r requirements.txtOU
pip3 install -r requirements.txt --break-system-packagesgunicorn -w 2 -b 0.0.0.0:8000 app:appsudo nano /etc/nginx/sites-available/defaultserver {
listen 80 ;
server_name your-ec2-public-ip ;
location / {
proxy_pass http://127.0.0.1:8000 ;
proxy_set_header Host $host ;
proxy_set_header X-Real-IP $remote_addr ;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for ;
proxy_set_header X-Forwarded-Proto $scheme ;
}
}sudo systemctl restart nginxsudo nano /etc/systemd/system/gunicorn.service[Unit]
Description=Gunicorn instance to serve my project
After=network.target
[Service]
User=ubuntu
Group=www-data
WorkingDirectory=/home/ubuntu/E-Commerce_ChatBot_Project
ExecStart=/usr/bin/gunicorn --workers 4 --bind 127.0.0.1:8000 app:app
[Install]
WantedBy=multi-user.targetsudo systemctl start gunicornsudo systemctl enable gunicorngunicorn -w 2 -b 0.0.0.0:8000 app:appPublic_Address:8080Ce chatbot de commerce électronique offre une expérience d'achat interactive intelligente grâce à une approche de chiffon qui combine la récupération et la génération, offrant des recommandations de produits pertinentes basées sur des avis sur les clients.
Le modèle grand langage de LLAMA 3.1 et les incorporations d'étreinte permettent de permettre des réponses nuancées, améliorant l'engagement des utilisateurs avec des conversations de rendez-vous contextuellement.
Une gestion efficace de la réponse avec Redis et le céleri répond aux exigences d'une application très performante, garantissant des expériences utilisateur stables et réactives même avec de grands LLM .
Un déploiement AWS EC2 entièrement évolutif permet une intégration transparente dans les plates-formes de commerce électronique, offrant une infrastructure robuste pour des environnements à fort trafic.
Ce projet présente une application puissante de modèles de gros langues , repoussant les limites des capacités de chatbot dans le domaine du commerce électronique.


