ecco
v0.1.2: hotfix
ECCO est une bibliothèque Python pour explorer et expliquer les modèles de traitement du langage naturel à l'aide de visualisations interactives.
ECCO fournit plusieurs interfaces pour aider l'explication et l'intuition des modèles de langage basés sur les transformateurs. Lire: Interfaces pour expliquer les modèles de langue transformateur.
ECCO s'exécute à l'intérieur des cahiers Jupyter. Il est construit sur le pytorch et les transformateurs.
L'ECCO ne concerne pas la formation ou les modèles de réglage fin. Explorer et comprendre les modèles pré-formés existants. La bibliothèque est actuellement une version alpha d'un projet de recherche. Vous êtes invités à contribuer à l'améliorer!
Documentation: ecco.readthedocs.io
Vous pouvez installer ecco avec pip ou avec conda .
avec pip
pip install eccoavec conda
conda install -c conda-forge eccoVous pouvez exécuter tous ces exemples à partir de ce [cahier] | [Colab].
Utilisez un modèle grand langage (T5 dans ce cas) pour détecter le sentiment du texte. En plus du sentiment, voir les jetons dans lesquels le modèle a brisé le texte (ce qui peut aider à déboguer certains cas de bord).
L'attribution des fonctionnalités utilisant des gradients intégrés vous aide à explorer les décisions du modèle. Dans ce cas, le changement de "faiblesse" à "l'inclinaison" permet au modèle de basculer correctement la prédiction à positif .
GPT2 sait-il où est l'aéroport d'Heathrow? Oui. C'est le cas.
Visualisez les jetons de sortie candidats et leurs scores de probabilité.
Le modèle a choisi Londres en faisant le jeton de probabilité le plus élevé (le classant # 1) après la dernière couche du modèle. Dans quelle mesure chaque couche a-t-elle contribué à augmenter le classement de Londres ? Il s'agit d'une visualisation de l'objectif logit qui aide à explorer l'activité de différentes couches de modèle.
Un groupe de neurones de Bert a tendance à tirer en réponse aux virgules et à d'autres ponctuations. D'autres groupes de neurones ont tendance à tirer en réponse aux pronoms. Utilisez cette visualisation pour factoriser l'activité des neurones dans les couches FFNN individuelles ou dans tout le modèle.
Lisez le journal:
ECCO: une bibliothèque open source pour l'explication des démonstrations du système des modèles de langue transformateur pour la linguistique computationnelle (LCA), 2021
La référence de l'API et la page d'architecture expliquent les composants de l'ECCO et comment ils fonctionnent ensemble.
Tokens prévu: affichez la prédiction du modèle pour le jet de jetons suivant (avec des scores de probabilité). Voyez comment les prédictions ont évolué à travers les couches du modèle. [Notebook] [Colab]

Classement sur les couches: Une fois que le modèle choisit un jeton de sortie, regardez comment chaque couche a classé ce jeton. [Notebook] [Colab]
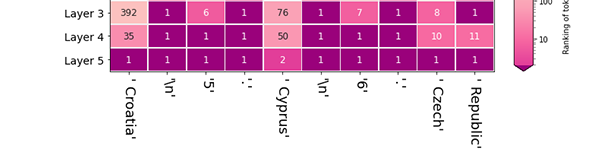
Prédictions de couche: Comparez le classement de plusieurs jetons en tant que candidats pour une certaine position dans la séquence. [Notebook] [Colab]
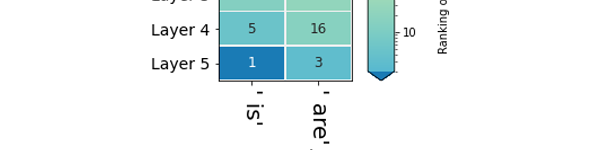
Attributions primaires: combien de jeton d'entrée a-t-il contribué à la production du jeton de sortie? [Notebook] [Colab]

Attributions primaires détaillées: Voir les valeurs d'attributions d'entrée plus précises à l'aide de la vue détaillée. [Notebook] [Colab]

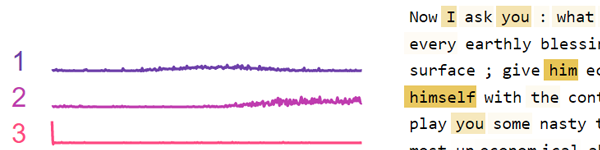
Analyse d'activation des neurones: examiner les modèles sous-jacents dans les activations des neurones en utilisant une factorisation de matrice non négative. [Notebook] [Colab]
Vous avez des problèmes?
Bibtex pour les citations:
@inproceedings { alammar-2021-ecco ,
title = " Ecco: An Open Source Library for the Explainability of Transformer Language Models " ,
author = " Alammar, J " ,
booktitle = " Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations " ,
year = " 2021 " ,
publisher = " Association for Computational Linguistics " ,
}

