ecco
v0.1.2: hotfix
ECCO ist eine Python -Bibliothek zum Erforschen und Erklären von Modellen für natürliche Sprachverarbeitungsmodelle mithilfe interaktiver Visualisierungen.
ECCO bietet mehrere Schnittstellen, um die Erklärung und Intuition von transformatorbasierten Sprachmodellen zu unterstützen. Lesen Sie: Schnittstellen zur Erklärung von Transformatorsprachmodellen.
ECCO läuft in Jupyter -Notizbüchern. Es ist auf Pytorch und Transformers aufgebaut.
ECCO befasst sich nicht mit Trainings- oder Feinabstimmungsmodellen. Nur vorhandene vorgeborene Modelle untersuchen und verstehen. Die Bibliothek ist derzeit eine Alpha -Veröffentlichung eines Forschungsprojekts. Sie können gerne dazu beitragen, es besser zu machen!
Dokumentation: ecco.readthedocs.io
Sie können ecco entweder mit pip oder mit conda installieren.
mit Pip
pip install eccomit Conda
conda install -c conda-forge eccoSie können all diese Beispiele aus diesem [Notizbuch] | ausführen [Colab].
Verwenden Sie ein großes Sprachmodell (in diesem Fall T5), um die Textstimmung zu erkennen. Zusätzlich zu dem Gefühl siehe die Tokens Das Modell hat den Text in die Debugie einiger Kantenfälle eingebrochen).
Die Merkmalszuordnung unter Verwendung integrierter Gradienten hilft Ihnen, Modellentscheidungen zu erforschen. In diesem Fall ermöglicht das Umschalten der "Schwäche" in die "Neigung" das Modell, die Vorhersage auf positives umzuschalten.
Weiß GPT2, wo der Flughafen Heathrow ist? Ja. Es tut.
Visualisieren Sie die Kandidatenausgangs -Token und deren Wahrscheinlichkeitswerte.
Das Modell wählte London, indem er nach der letzten Schicht im Modell das höchste Wahrscheinlichkeits -Token (Ranging It #1) erstellte. Wie viel hat jede Schicht dazu beigetragen, die Rangliste Londons zu erhöhen? Dies ist eine Logit -Objektivvisualisierungen, mit der die Aktivität verschiedener Modellschichten untersucht werden.
Eine Gruppe von Neuronen in Bert neigt dazu, als Reaktion auf Kommas und andere Interpunktion zu schießen. Andere Gruppen von Neuronen neigen dazu, als Reaktion auf Pronomen zu schießen. Verwenden Sie diese Visualisierung, um die Neuronenaktivität in einzelnen FFNN -Schichten oder im gesamten Modell zu faktorisieren.
Lesen Sie das Papier:
ECCO: Eine Open -Source -Bibliothek zur Erklärung der Transformatorsprachmodelle Association for Computational Linguistics (ACL) -Systemdemonstrationen, 2021
Die API -Referenz und die Seite der Architektur erklären die Komponenten von ECCOs und wie sie zusammenarbeiten.
Vorhersagte Token: Sehen Sie sich die Vorhersage des Modells für das nächste Token an (mit Wahrscheinlichkeitswerten). Sehen Sie, wie sich die Vorhersagen durch die Schichten des Modells entwickelt haben. [Notebook] [Colab]

Ranglisten über Ebenen: Nachdem das Modell einen Ausgangs -Token gewählt hat, schauen Sie zurück, wie jede Schicht dieses Token eingreift. [Notebook] [Colab]
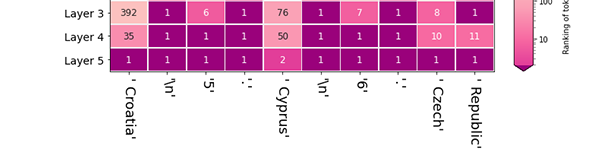
Schichtvorhersagen: Vergleichen Sie die Rankings mehrerer Token als Kandidaten für eine bestimmte Position in der Sequenz. [Notebook] [Colab]
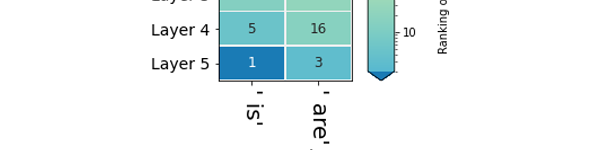
Hauptattributionen: Wie viel hat jeder Eingangs -Token zur Erzeugung des Ausgangs -Tokens beigetragen? [Notebook] [Colab]

Detaillierte primäre Zuschreibungen: Genauere Werte für Eingabe -Zuschreibungen finden Sie unter der detaillierten Ansicht. [Notebook] [Colab]

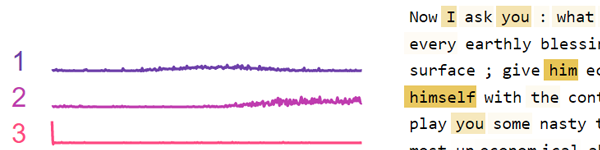
Neuronaktivierungsanalyse: Untersuchen Sie die zugrunde liegenden Muster in Neuronaktivierungen unter Verwendung einer nicht negativen Matrixfaktorisierung. [Notebook] [Colab]
Schwierigkeiten haben?
Bibtex für Zitate:
@inproceedings { alammar-2021-ecco ,
title = " Ecco: An Open Source Library for the Explainability of Transformer Language Models " ,
author = " Alammar, J " ,
booktitle = " Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations " ,
year = " 2021 " ,
publisher = " Association for Computational Linguistics " ,
}

