lacc
1.0.0
Il s'agit d'un de mes jouets, dans le but de faire un compilateur pour C, écrit en C, qui est capable de se compiler.
Clone et construire à partir de la source, et le binaire sera placé dans bin/lacc .
git clone https://github.com/larmel/lacc.git
cd lacc
./configure
make
make install
La configuration par défaut inclut un sondage de base de l'environnement pour détecter la machine et la LIBC pour lesquelles nous compilons. Les plates-formes reconnues incluent actuellement Linux avec GLIBC ou MUSL et OpenBSD.
Certains en-têtes de bibliothèque standard, tels que stddef.h et stdarg.h , contiennent des définitions qui sont intrinsèquement spécifiques au compilateur et sont fournies spécifiquement pour LACC sous lib /. Si vous souhaitez utiliser directement bin/lacc sans installer les en-têtes, vous pouvez remplacer l'emplacement en réglant --libdir pour pointer directement vers ce dossier.
La cible install copiera les en-têtes binaires et les en-têtes dans les emplacements habituels, ou comme configuré avec --prefix ou --bindir . Il existe également une option pour définir DESTDIR . Exécutez make uninstall pour supprimer tous les fichiers copiés.
Voir ./configure --help help pour les options pour personnaliser les paramètres de construction et d'installation.
L'interface de ligne de commande est maintenue similaire à GCC et à d'autres compilateurs, en utilisant principalement un sous-ensemble des mêmes drapeaux et options.
-E Output preprocessed.
-S Output GNU style textual x86_64 assembly.
-c Output x86_64 ELF object file.
-dot Output intermediate representation in dot format.
-o Specify output file name. If not speficied, default to input file
name with suffix changed to '.s', '.o' or '.dot' when compiling
with -S, -c or -dot, respectively. Otherwise use stdout.
-std= Specify C standard, valid options are c89, c99, and c11.
-I Add directory to search for included files.
-w Disable warnings.
-g Generate debug information (DWARF).
-O{0..3} Set optimization level.
-D X[=] Define macro, optionally with a value. For example -DNDEBUG, or
-D 'FOO(a)=a*2+1'.
-f[no-]PIC Generate position-independent code.
-v Print verbose diagnostic information. This will dump a lot of
internal state during compilation, and can be useful for debugging.
--help Print help text.
Les arguments qui ne correspondent à aucune option sont considérés comme des fichiers d'entrée. Si aucun mode de compilation n'est spécifié, LACC agira comme un wrapper pour le linker /bin/ld système. Certains drapeaux de linker communs sont pris en charge.
-Wl, Specify linker options, separated by commas.
-L Add linker include directory.
-l Add linker library.
-shared Passed to linker as is.
-rdynamic Pass -export-dynamic to linker.
À titre d'exemple d'invocation, ici compile le test / c89 / fact.c au code de l'objet, puis en utilisant le linker système pour produire l'exécutable final.
bin/lacc -c test/c89/fact.c -o fact.o
bin/lacc fact.o -o fact
Le programme fait partie de la suite de tests, calculant 5! Utilisation de la récursivité et sortant avec la réponse. Courir ./fact suivi d' echo $? devrait imprimer 120 .
Le compilateur est écrit en C89, comptant environ 19 000 lignes de code au total. Il n'y a pas de dépendances externes à l'exception de la libary standard C, et certains appels système requis pour invoquer le linker.
La mise en œuvre est organisée en quatre parties principales; Prérocesseur, analyseur, optimiseur et backend, chacun dans son propre répertoire sous SRC /. En général, chaque module (un fichier .c généralement associé à un fichier .h définissant l'interface publique) dépend principalement des en-têtes dans leur propre sous-arbre. Les déclarations partagées au niveau mondial résident dans include / lacc /. C'est là que vous trouverez les structures de données de base et les interfaces entre le prétraitement, l'analyse et la génération de code.
Le prétraitement comprend des fichiers de lecture, des tokenisation, une expansion de macro et une gestion de directive. L'interface avec le préprocesseur est peek(0) , peekn(1) , consume(1) , try_consume(1) et next(0) , qui examine un flux d'objets struct token prétraités. Ceux-ci sont définis dans include / lacc / token.h.
Le traitement des entrées est effectué complètement paresseusement, entraîné par l'analyseur, appelant ces fonctions pour consommer plus d'entrée. Un tampon de jetons prétraités est conservé pour la lookahead et rempli à la demande en jetant un coup d'œil.
Le code est modélisé en tant que graphique de flux de contrôle des blocs de base, chacun maintenant une séquence d'instructions de code à trois adresses. Chaque variable externe ou définition de fonction est représentée par un objet struct definition , définissant un seul struct symbol et un CFG tenant le code. Les structures de données soutenant la représentation intermédiaire peuvent être trouvées dans Inclut / lacc / ir.h.
La visualisation de la représentation intermédiaire est une cible de sortie distincte. Si l'option -DOT est spécifiée, un fichier texte formaté DOT est produit sous forme de sortie.
bin/lacc -dot -I include src/backend/compile.c -o compile.dot
dot -Tps compile.dot -o compile.ps
Vous trouverez ci-dessous un exemple d'une fonction trouvée dans SRC / Backend / Compile.c, montrant une tranche du graphique complet. La sortie complète peut être générée en tant que fichier PostScript en exécutant les commandes affichées.
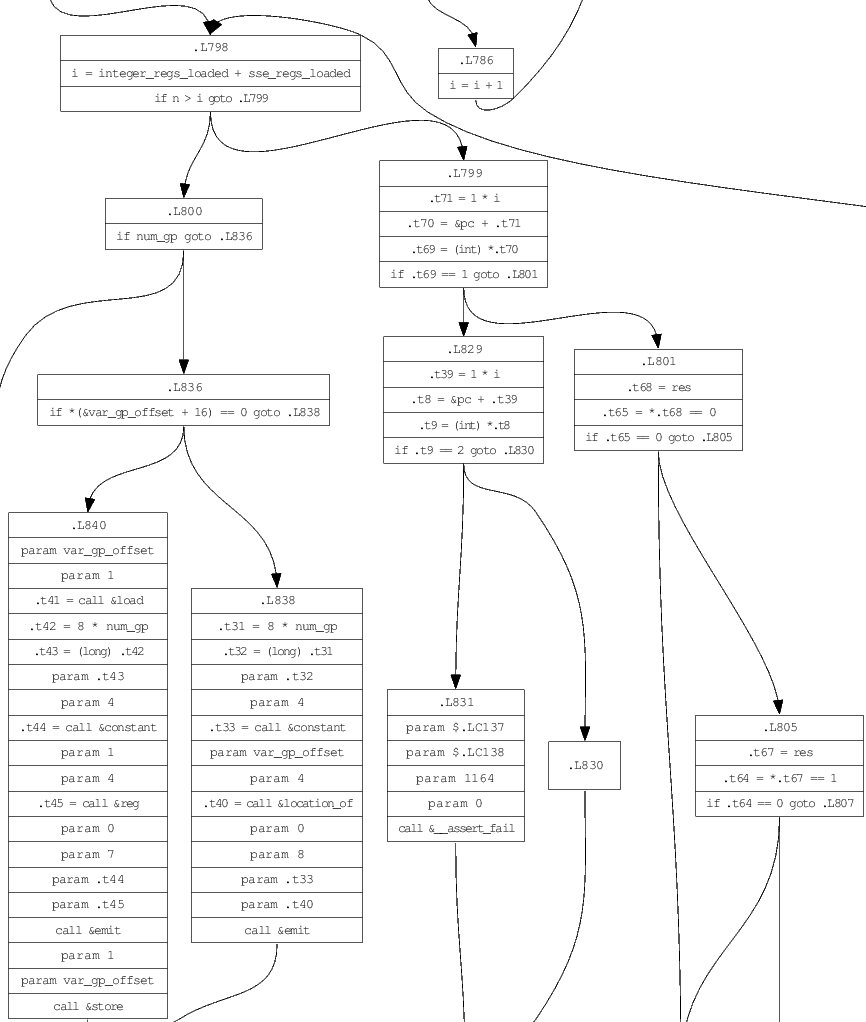
Chaque bloc de base du graphique a une liste d'instructions, le plus souvent IR_ASSIGN , qui attribue une expression ( struct expression ) à une variable ( struct var ). Les expressions contiennent également des opérandes variables, qui peuvent coder les emplacements de mémoire, les adresses et les pointeurs déréférencés à un niveau élevé.
DIRECT se réfèrent à la mémoire à *(&symbol + offset) , où le symbole est une variable ou temporaire à un emplacement spécifique en mémoire (par exemple pile).ADDRESS représentent exactement l'adresse d'un opérande DIRECT , à savoir (&symbol + offset) .DEREF se réfèrent à la mémoire indiquée par un symbole (qui doit être de type de pointeur). L'expression est *(symbol + offset) , qui nécessite deux opérations de charge pour mapper pour assembler. Seules les variables DEREF et DIRECT peuvent être cibles pour l'attribution ou la valeur L.IMMEDIATE contiennent un nombre constant ou une chaîne. L'évaluation des opérandes immédiats effectuait automatiquement le pliage constant.L'analyseur est une descente récursive codée à la main, avec des pièces principales divisées en src / parser / déclaration.c, src / parser / initializer.c, src / parser / expression.c et src / parser / instruction.c. Le graphique de flux de fonction de fonction actuel et le bloc de base actif actuel dans ce graphique sont passés comme arguments à chaque production. Le graphique est progressivement construit comme de nouvelles instructions de code à trois adhésions sont ajoutées au bloc actuel.
L'exemple suivant montre la règle d'analyse pour les expressions bit en bit, ce qui ajoute une nouvelle opération IR_OP_OR au bloc actuel. La logique dans eval_expr garantira que la value des opérandes et block->expr sont valides, se terminant en cas d'erreur.
static struct block *inclusive_or_expression(
struct definition *def,
struct block *block)
{
struct var value;
block = exclusive_or_expression(def, block);
while (try_consume('|')) {
value = eval(def, block, block->expr);
block = exclusive_or_expression(def, block);
block->expr = eval_or(def, block, value, eval(def, block, block->expr));
}
return block;
}
Le dernier résultat d'évaluation est toujours stocké dans block->expr . La ramification se fait en instanciant de nouveaux blocs de base et en maintenant des pointeurs. Chaque bloc de base a un pointeur de branche vrai et faux vers d'autres blocs, c'est ainsi que les branches et les gotos sont modélisés. Notez qu'à aucun moment, il n'y a aucune structure d'arbre de syntaxe en cours de construction. Il n'existe que implicitement dans la récursivité.
La principale motivation pour construire un graphique de flux de contrôle est de pouvoir effectuer une analyse et une optimisation du flux de données. Les capacités actuelles ici sont encore limitées, mais elles peuvent facilement être étendues avec des passes d'analyse et d'optimisation supplémentaires et plus avancées.
Une analyse de la vivacité est utilisée pour comprendre, à chaque déclaration, que les symboles peuvent être lus plus tard. L'algorithme de flux de données est implémenté à l'aide de masques de bits pour représenter des symboles, en les numérotant 1-63. En conséquence, l'optimisation ne fonctionne que sur les fonctions avec moins de 64 variables. L'algorithme doit également être très conservateur, car il n'y a pas encore d'analyse d'alias de pointeur.
En utilisant les informations de la vivacité, un laissez-passer de transformation faisant l'élimination des magasins morts peut supprimer les nœuds IR_ASSIGN qui ne font que ne font rien, réduisant la taille du code généré.
Il y a trois cibles backend: le code d'assemblage textuel, les fichiers d'objets ELF et DOT pour la représentation intermédiaire. Chaque objet struct definition rendu à partir de l'analyseur est transmis au module SRC / Backend / Compile.c. Ici, nous faisons un mappage à partir de la représentation du graphique de flux de contrôle intermédiaire jusqu'à un niveau inférieur IR, réduisant le code à quelque chose qui représente directement les instructions x86_64. La définition de ceci peut être trouvée dans SRC / Backend / x86_64 / Encoding.h.
Selon les pointeurs de fonction configurés sur le démarrage du programme, les instructions sont envoyées au backend ELF ou à l'assemblage de texte. L'assemblage de texte du code à la sortie est donc très simple, plus ou moins juste un mappage entre les instructions IR à bas niveau et leur code d'assemblage de syntaxe GNU. Voir src / backend / x86_64 / asseble.c.
La sortie du point est un pipeline distinct qui n'a pas besoin de générer IR de faible niveau. Le module de compilation transmettra simplement le CFG vers SRC / Backend / Graphviz / Dot.c.
Le test est effectué en comparant la sortie d'exécution des programmes compilés avec LACC et le System Compiler (CC). Une collection de petits programmes autonomes utilisés pour la validation peut être trouvé dans le test / répertoire. Les tests sont exécutés à l'aide de Check.sh, qui validera le prétraitement, l'assemblage et les sorties ELF.
$ test/check.sh bin/lacc test/c89/fact.c
[-E: Ok!] [-S: Ok!] [-c: Ok!] [-c -O1: Ok!] :: test/c89/fact.c
Un test complet du compilateur est effectué en passant par tous les cas de test sur une version auto-hébergée de LACC.
make -C test
Cela utilisera d'abord le bin/lacc déjà construit pour produire bin/bootstrap/lacc , qui à son tour est utilisé pour construire bin/selfhost/lacc . Entre les étapes bootstrap et auto-host, les fichiers d'objets intermédiaires sont comparés pour l'égalité. Si tout fonctionne correctement, ces étapes devraient produire des binaires identiques. Le compilateur est «bon» lorsque tous les tests passent le binaire auto-hôte. Cela devrait toujours être vert, sur chaque engagement.
Il est difficile de trouver une bonne suite de test couvrant tous les cas possibles. Pour éliminer les bogues, nous pouvons utiliser CSmith pour générer des programmes aléatoires adaptés à la validation.
./csmith.sh
Le script csmith.sh exécute CSmith pour générer une séquence infinie de programmes aléatoires jusqu'à ce que quelque chose échoue le harnais de test. Il exécutera généralement des milliers de tests sans échec.

Les programmes générés par CSmith contiennent un ensemble de variables globales et des fonctions faisant des mutations sur ces derniers. À la fin, une somme de contrôle de l'état complet de toutes les variables est sortie. Cette somme de contrôle peut ensuite être comparée à différents compilateurs pour trouver des écarts ou des bogues. Voir doc / random.c pour un exemple de programme généré par CSmith, qui est également compilé correctement par LACC.
Lorsqu'un bug est trouvé, nous pouvons utiliser Creduce pour faire un repro minimal. Cela finira alors comme un nouveau cas de test dans la suite de test normale.
Certains efforts ont été consacrés à la fabrication du compilateur lui-même rapidement (bien que le code généré soit encore très non optimisé). En servant à la fois de référence de performance et de test d'exactitude, nous utilisons le moteur de base de données SQLite. Le code source est distribué comme un seul ~ 7 Mo (7184634 octets) un grand fichier C couvrant plus de 200 k lignes (y compris les commentaires et les espaces blancs), ce qui est parfait pour tester le compilateur.
Les expériences suivantes ont été exécutées sur un ordinateur portable avec un CPU i5-7300U, compilant la version 3.20.1 de SQLite3. Les mesures sont faites de la compilation au code d'objet (-C).
Il faut moins de 200 ms pour compiler le fichier avec LACC, mais plutôt que le temps, nous examinons un échantillonnage plus précis des cycles et des instructions CPU exécutés. Les données de compteur de performances matérielles sont collectées avec perf stat et les allocations de mémoire avec valgrind --trace-children=yes . Dans Valgrind, nous ne comptons que les contributions du compilateur lui-même (exécutable cc1 ) lors de l'exécution de GCC.
Les nombres pour LACC proviennent d'une version optimisée produite par make CC='clang -O3 -DNDEBUG' bin/lacc . Chaque compilateur est invoqué avec des arguments -c sqlite/sqlite3.c -o foo.o
| Compilateur | Cycles | Instructions | Allocations | Octets alloués | Taille des résultats |
|---|---|---|---|---|---|
| LACC | 412 334 334 | 619 466 003 | 49 020 | 24 244,107 | 1 590 482 |
| TCC (0.9.27) | 245 142 166 | 397 514 762 | 2 909 | 23 020 917 | 1 409 716 |
| GCC (9.3.0) | 9 958 514 599 | 14 524 274 665 | 1 546 790 | 1 111 331 606 | 1 098 408 |
| Clang (10.0.0) | 4 351 456 211 | 5 466 808 426 | 1 434 072 | 476 529 342 | 1 116 992 |
Il reste encore du travail à faire pour se rapprocher du TCC, ce qui est probablement l'un des compilateurs C les plus rapides disponibles. Pourtant, nous sommes à distance raisonnable des performances du TCC, et un ordre de grandeur mieux que GCC et Clang.
À partir du tableau ci-dessus, nous pouvons voir que la taille du fichier d'objet SQLite généré par LACC est plus grande que celles générées par d'autres compilateurs, ce qui suggère que nous étions un code moins optimal.
Pour comparer la qualité relative du code générée à partir de LACC et GCC, nous pouvons examiner le nombre d'instructions dynamiques exécutées par le binaire auto-hôte par rapport à un binaire construit par GCC. Nous exécutons le même test que ci-dessus, en compilant SQLite vers le code d'objet. Les cibles du test sont la construction par défaut du compilateur ( bin/lacc ) produite par GCC, et le binaire auto-host ( bin/selfhost/lacc ) produit par LACC. Ces deux cibles sont produites sans aucune optimisation activée et sans définir NDEBUG .
| Compilateur | Cycles | Instructions |
|---|---|---|
| LACC | 946,315,653 | 1 481 608 726 |
| LACC (Self-Host) | 1 417 112 690 | 2 046 996 115 |
Le binaire auto-hébergé est plus lent à compiler SQLite que le compilateur construit par GCC, montrant que le LACC génère en effet du code plutôt inefficace. L'amélioration du backend avec une meilleure sélection d'instructions est une priorité, donc ces chiffres devraient, espérons-le, se rapprocher à l'avenir.
Ce sont des ressources utiles pour construire un compilateur C ciblant x86_64.


