lacc
1.0.0
Este es un proyecto mío de juguete, con el objetivo de hacer un compilador para C, escrito en C, que puede compilarse.
Clon y construcción desde la fuente, y el binario se colocará en bin/lacc .
git clone https://github.com/larmel/lacc.git
cd lacc
./configure
make
make install
La configuración predeterminada incluye algunos sondeos básicos del entorno para detectar qué máquina y libc estamos compilando. Las plataformas reconocidas actualmente incluyen Linux con GLIBC o MUSL, y OpenBSD.
Ciertos encabezados de biblioteca estándar, como stddef.h y stdarg.h , contienen definiciones inherentemente específicas del compilador, y se proporcionan específicamente para lacc bajo lib/. Si desea usar bin/lacc directamente sin instalar los encabezados, puede anular la ubicación configurando --libdir para señalar esta carpeta directamente.
El objetivo install copiará el binario y los encabezados a las ubicaciones habituales, o según lo configurado con --prefix o --bindir . También hay una opción para establecer DESTDIR . Ejecutar make uninstall para eliminar todos los archivos que se copiaron.
Consulte ./configure --help para las opciones para personalizar los parámetros de compilación e instalar.
La interfaz de la línea de comandos se mantiene similar a GCC y otros compiladores, utilizando principalmente un subconjunto de los mismos indicadores y opciones.
-E Output preprocessed.
-S Output GNU style textual x86_64 assembly.
-c Output x86_64 ELF object file.
-dot Output intermediate representation in dot format.
-o Specify output file name. If not speficied, default to input file
name with suffix changed to '.s', '.o' or '.dot' when compiling
with -S, -c or -dot, respectively. Otherwise use stdout.
-std= Specify C standard, valid options are c89, c99, and c11.
-I Add directory to search for included files.
-w Disable warnings.
-g Generate debug information (DWARF).
-O{0..3} Set optimization level.
-D X[=] Define macro, optionally with a value. For example -DNDEBUG, or
-D 'FOO(a)=a*2+1'.
-f[no-]PIC Generate position-independent code.
-v Print verbose diagnostic information. This will dump a lot of
internal state during compilation, and can be useful for debugging.
--help Print help text.
Los argumentos que no coinciden con ninguna opción se consideran archivos de entrada. Si no se especifica el modo de compilación, LACC actuará como un envoltorio para el enlazador del sistema /bin/ld . Se admiten algunas banderas de enlazadores comunes.
-Wl, Specify linker options, separated by commas.
-L Add linker include directory.
-l Add linker library.
-shared Passed to linker as is.
-rdynamic Pass -export-dynamic to linker.
Como una invocación de ejemplo, aquí está compilando Test/C89/Fact.c al código de objeto, y luego utilizando el enlazador del sistema para producir el ejecutable final.
bin/lacc -c test/c89/fact.c -o fact.o
bin/lacc fact.o -o fact
¡El programa es parte de la suite de prueba, calculando 5! usando recursión y saliendo con la respuesta. Ejecutando ./fact seguido de echo $? debe imprimir 120 .
El compilador está escrito en C89, contando alrededor de 19k líneas de código en total. No hay dependencias externas, excepto la liberación estándar C, y algunas llamadas del sistema se requieren para invocar el enlazador.
La implementación se organiza en cuatro partes principales; Preprocesador, analizador, optimizador y backend, cada uno en su propio directorio bajo SRC/. En general, cada módulo (un archivo .c generalmente emparejado con un archivo .h que define la interfaz pública) depende principalmente de los encabezados en su propio subárbol. Las declaraciones que se comparten a nivel global residen en incluir/lacc/. Aquí es donde encontrará las estructuras de datos principales e interfaces entre el preprocesamiento, el análisis y la generación de código.
El preprocesamiento incluye lectura de archivos, tokenización, expansión de macro y manejo de directivas. La interfaz al preprocesador es peek(0) , peekn(1) , consume(1) , try_consume(1) y next(0) , que mira una corriente de objetos struct token preprocesados. Estos se definen en incluir/lacc/token.h.
El procesamiento de la entrada se realiza completamente perezosamente, impulsado por el analizador que llama a estas funciones para consumir más entrada. Se mantiene un amortiguador de tokens preprocesados para Lookahead y se llena a pedido al mirar hacia adelante.
El código se modela como gráfico de flujo de control de bloques básicos, cada uno contiene una secuencia de declaraciones de código de tres direcciones. Cada definición de variable o función externa se representa mediante un objeto struct definition , definiendo un struct symbol único y un CFG que contiene el código. Las estructuras de datos que respaldan la representación intermedia se pueden encontrar en incluir/lacc/ir.h.
Visualizar la representación intermedia es un objetivo de salida separado. Si se especifica la opción -dot, se produce un archivo de texto formateado de puntos como salida.
bin/lacc -dot -I include src/backend/compile.c -o compile.dot
dot -Tps compile.dot -o compile.ps
A continuación se muestra un ejemplo de una función que se encuentra en SRC/Backend/Compile.c, que muestra una porción del gráfico completo. La salida completa se puede generar como un archivo PostScript ejecutando los comandos mostrados.
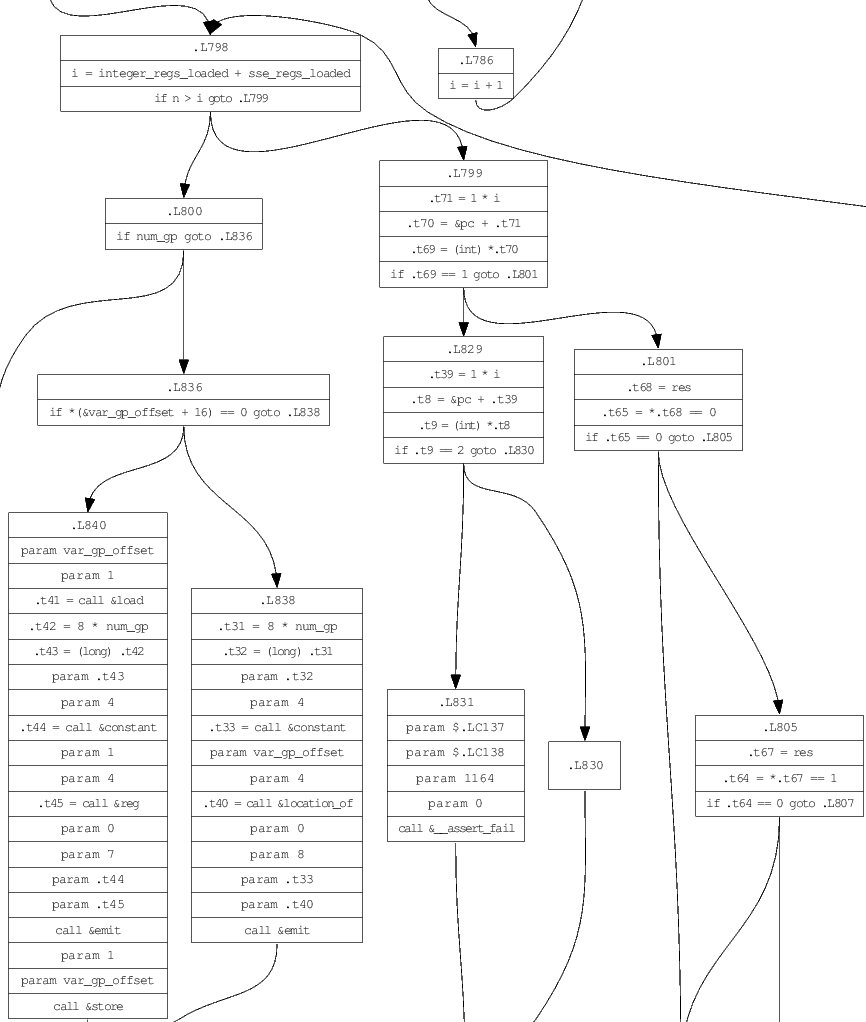
Cada bloque básico en el gráfico tiene una lista de declaraciones, más comúnmente IR_ASSIGN , que asigna una expresión ( struct expression ) a una variable ( struct var ). Las expresiones también contienen operandos variables, que pueden codificar ubicaciones de memoria, direcciones y punteros desferenciados a un alto nivel.
DIRECT se refieren a la memoria en *(&symbol + offset) , donde el símbolo es una variable o temporal en una ubicación específica en la memoria (por ejemplo, pila).ADDRESS representan exactamente la dirección de un operando DIRECT , a saber (&symbol + offset) .DEREF se refieren a la memoria señalada por un símbolo (que debe ser de tipo de puntero). La expresión es *(symbol + offset) , que requiere dos operaciones de carga para mapear al ensamblaje. Solo las variables DEREF y DIRECT pueden ser objetivo para la asignación, o valor L.IMMEDIATE contienen un número constante o cadena. La evaluación de operandos inmediatos hace un plegamiento constante automáticamente.El analizador es descenso recursivo codificado a mano, con piezas principales divididas en src/parser/declaración.c, src/parser/inicializer.c, src/parser/expresion.c, y src/parser/stattle.c. El gráfico de flujo de control de función actual, y el bloqueo básico activo actual en ese gráfico, se pasan como argumentos a cada producción. El gráfico se construye gradualmente a medida que se agregan nuevas instrucciones de código de tres direcciones al bloque de corriente.
El siguiente ejemplo muestra la regla de análisis para bitwise o expresiones, que agrega una nueva operación IR_OP_OR al bloque actual. La lógica en eval_expr asegurará que el value de los operandos y block->expr sean válidos, terminando en caso de un error.
static struct block *inclusive_or_expression(
struct definition *def,
struct block *block)
{
struct var value;
block = exclusive_or_expression(def, block);
while (try_consume('|')) {
value = eval(def, block, block->expr);
block = exclusive_or_expression(def, block);
block->expr = eval_or(def, block, value, eval(def, block, block->expr));
}
return block;
}
El último resultado de la evaluación siempre se almacena en block->expr . La ramificación se realiza instanciando nuevos bloques básicos y manteniendo punteros. Cada bloque básico tiene un puntero de rama verdadero y falso a otros bloques, que es cómo se modelan las ramas y los gotos. Tenga en cuenta que en ningún momento hay alguna estructura de árbol de sintaxis que se esté construyendo. Existe solo implícitamente en la recursión.
La principal motivación para construir un gráfico de flujo de control es poder hacer análisis y optimización de flujo de datos. Las capacidades actuales aquí todavía son limitadas, pero se puede extender fácilmente con análisis de análisis y optimización adicionales y más avanzados.
El análisis de la vida se usa para resolver, en cada declaración, que los símbolos se pueden leer más tarde. El algoritmo de flujo de datos se implementa utilizando máscaras de bits para representar símbolos, numerándolos 1-63. Como consecuencia, la optimización solo funciona en funciones con menos de 64 variables. El algoritmo también tiene que ser muy conservador, ya que no hay análisis de alias de puntero (todavía).
Utilizando la información de la vida, un pase de transformación que hace la eliminación de la tienda muerta puede eliminar los nodos IR_ASSIGN que probablemente no hacen nada, reduciendo el tamaño del código generado.
Hay tres objetivos de backend: código de ensamblaje textual, archivos de objetos ELF y DOT para la representación intermedia. Cada objeto struct definition producido del analizador se pasa al módulo src/backend/compile.c. Aquí hacemos una asignación de la representación del gráfico de flujo de control intermedio a un IR de nivel inferior, reduciendo el código a algo que representa directamente las instrucciones x86_64. La definición de esto se puede encontrar en SRC/Backend/X86_64/Encoding.h.
Dependiendo de los punteros de la función configurados en el inicio del programa, las instrucciones se envían al backend de ELF o al ensamblaje de texto. Por lo tanto, el conjunto de texto de código a salida es muy simple, más o menos solo una asignación entre las instrucciones IR de bajo nivel y su código de ensamblaje de sintaxis GNU. Ver src/backend/x86_64/ensamble.c.
La salida del punto es una tubería separada que no necesita generar IR de bajo nivel. El módulo de compilación simplemente reenviará el CFG a SRC/Backend/GraphViz/Dot.c.
Las pruebas se realizan comparando la salida de tiempo de ejecución de los programas compilados con LACC y el compilador del sistema (CC). Se puede encontrar una colección de pequeños programas independientes utilizados para la validación en la prueba/ directorio. Las pruebas se ejecutan utilizando check.sh, que validará las salidas de preprocesamiento, ensamblaje y ELF.
$ test/check.sh bin/lacc test/c89/fact.c
[-E: Ok!] [-S: Ok!] [-c: Ok!] [-c -O1: Ok!] :: test/c89/fact.c
Una prueba completa del compilador se realiza revisando todos los casos de prueba en una versión autohospedada de LACC.
make -C test
Esto primero usará el bin/lacc ya construido para producir bin/bootstrap/lacc , que a su vez se usa para construir bin/selfhost/lacc . Entre las etapas de arranque y autohost, los archivos de objetos intermedios se comparan para la igualdad. Si todo funciona correctamente, estas etapas deberían producir binarios idénticos. El compilador es "bueno" cuando todas las pruebas pasan en el binario de sí mismo. Esto siempre debe ser verde, en cada compromiso.
Es difícil crear una buena suite de prueba que cubra todos los casos posibles. Para eliminar los errores, podemos usar csmith para generar programas aleatorios que sean adecuados para la validación.
./csmith.sh
El script csmith.sh ejecuta csmith para generar una secuencia infinita de programas aleatorios hasta que algo falla el arnés de prueba. Por lo general, ejecutará miles de pruebas sin falla.

Los programas generados por CSmith contienen un conjunto de variables globales y funciones que hacen mutaciones en ellas. Al final, se emite una suma de verificación del estado completo de todas las variables. Esta suma de verificación se puede comparar con diferentes compiladores para encontrar disceptancias o errores. Consulte Doc/Random.c para un programa de ejemplo generado por CSmith, que también se compila correctamente por LACC.
Cuando se encuentra un error, podemos usar creduce para hacer una repro mínima. Esto terminará como un nuevo caso de prueba en la suite de prueba normal.
Se ha hecho un esfuerzo para hacer que el compilador mismo sea rápido (aunque el código generado aún no está optimizado). Sirviendo como un punto de referencia de rendimiento y una prueba de corrección, utilizamos el motor de la base de datos SQLite. El código fuente se distribuye como un archivo C grande de un solo ~ 7 Mb (7184634 bytes) que abarca más de 200 líneas (incluidos comentarios y espacios en blanco), que es perfecto para probar el compilador del compilador.
Los siguientes experimentos se ejecutaron en una computadora portátil con una CPU i5-7300U, compilando la versión 3.20.1 de SQLITE3. Las mediciones se realizan desde la compilación al código de objeto (-c).
Se necesitan menos de 200 ms para compilar el archivo con LACC, pero en lugar del tiempo, observamos un muestreo más preciso de los ciclos e instrucciones de CPU ejecutados. Los datos del contador de rendimiento de hardware se recopilan con perf stat y asignaciones de memoria con valgrind --trace-children=yes . En Valgrind, solo contamos contribuciones del compilador mismo (ejecutable cc1 ) mientras ejecutan GCC.
Los números para LACC provienen de una construcción optimizada producida por make CC='clang -O3 -DNDEBUG' bin/lacc . Cada compilador se invoca con argumentos -c sqlite/sqlite3.c -o foo.o
| Compilador | Ciclos | Instrucciones | Asignaciones | Bytes asignados | Tamaño de resultado |
|---|---|---|---|---|---|
| lacc | 412,334,334 | 619,466,003 | 49,020 | 24,244,107 | 1.590,482 |
| TCC (0.9.27) | 245,142,166 | 397,514,762 | 2,909 | 23,020,917 | 1.409.716 |
| GCC (9.3.0) | 9,958,514,599 | 14,524,274,665 | 1.546.790 | 1,111,331,606 | 1.098,408 |
| Clang (10.0.0) | 4,351,456,211 | 5,466,808,426 | 1.434.072 | 476,529,342 | 1,116,992 |
Todavía hay trabajo por hacer para acercarse a TCC, que es probablemente uno de los compiladores C más rápidos disponibles. Aún así, estamos a una distancia razonable del rendimiento de TCC, y un orden de magnitud mejor que GCC y Clang.
De la tabla anterior, podemos ver que el tamaño del archivo de objeto SQLite generado por LACC es mayor que el generado por otros compiladores, lo que sugiere que obtenemos un código menos óptimo.
Para comparar la calidad relativa del código generado a partir de LACC y GCC, podemos ver el número de instrucciones dinámicas ejecutadas por el binario de autohost versus un binario construido por GCC. Ejecutamos la misma prueba que anteriormente, compilando SQLITE al código de objeto. Los objetivos para la prueba son la construcción de compilador predeterminada ( bin/lacc ) producida por GCC, y el binario de autohost ( bin/selfhost/lacc ) producido por LACC. Ambos objetivos se producen sin ninguna optimización habilitada y sin definir NDEBUG .
| Compilador | Ciclos | Instrucciones |
|---|---|---|
| lacc | 946,315,653 | 1.481,608,726 |
| lacc (autohost) | 1.417,112,690 | 2,046,996,115 |
El binario autohostado es más lento para compilar SQLite que el compilador construido por GCC, lo que demuestra que LACC realmente genera un código bastante ineficiente. Mejorar el backend con una mejor selección de instrucciones es una prioridad, por lo que estos números deberían acercarse en el futuro.
Estos son algunos recursos útiles para construir un compilador C dirigido a X86_64.


