Aperçu
Castroom est un moteur de recherche de podcast. Il a été principalement fait pour apprendre à faire un robot Web distribué à l'aide de Kubernetes. Il est capable de rassembler des centaines de milliers de podcasts en quelques heures et peut facilement être encore plus élargi avec une commande simple.
Structure du projet
Découverte
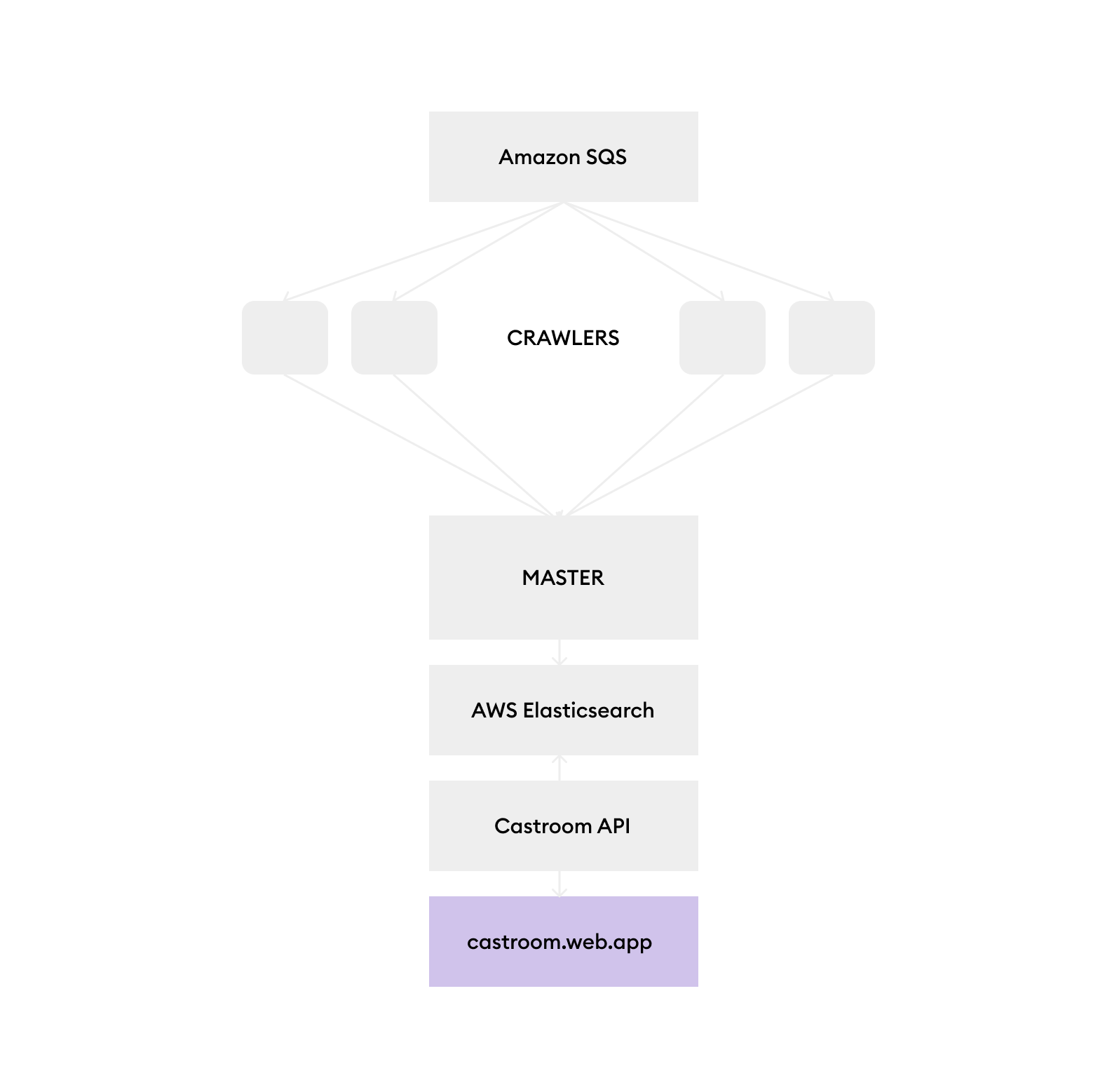
Maître
- Coordonne tous les travaux
crawler - maintient un cache local (en utilisant le niveaudb) pour empêcher la même URL d'être rampée plusieurs fois
- reçoit des données des nœuds
crawler et pousse vers la file d'attente - Les nœuds
crawler envoient toutes les données à ce nœud après avoir rampé un site Web - Envoyez les données à Elasticsearch à la fin
- Géré par Google Kubernetes Engine
Nabiller
- Crawls iTunes Podcast Pages et envoie des données par lots au nœud
master pour la mise en cache - passe par un proxy pour contourner certaines restrictions
- Géré par Google Kubernetes Engine
API
- Fournit des points de terminaison pour interroger les informations sur les produits de podcast Elasticsearch et récupérer
- hébergé sur Heroku
Web
- Frontend pour le moteur de recherche
- géré par l'hébergement de Firebase
Technologies utilisées
- Docker
- Moteur Google Kubernetes
- Service de file d'attente simple Amazon
- Service Amazon Elasticsearch
- Heroku
- Hébergement de base
- Réagir
- Node.js
- Niveaudb
- Médecin de données
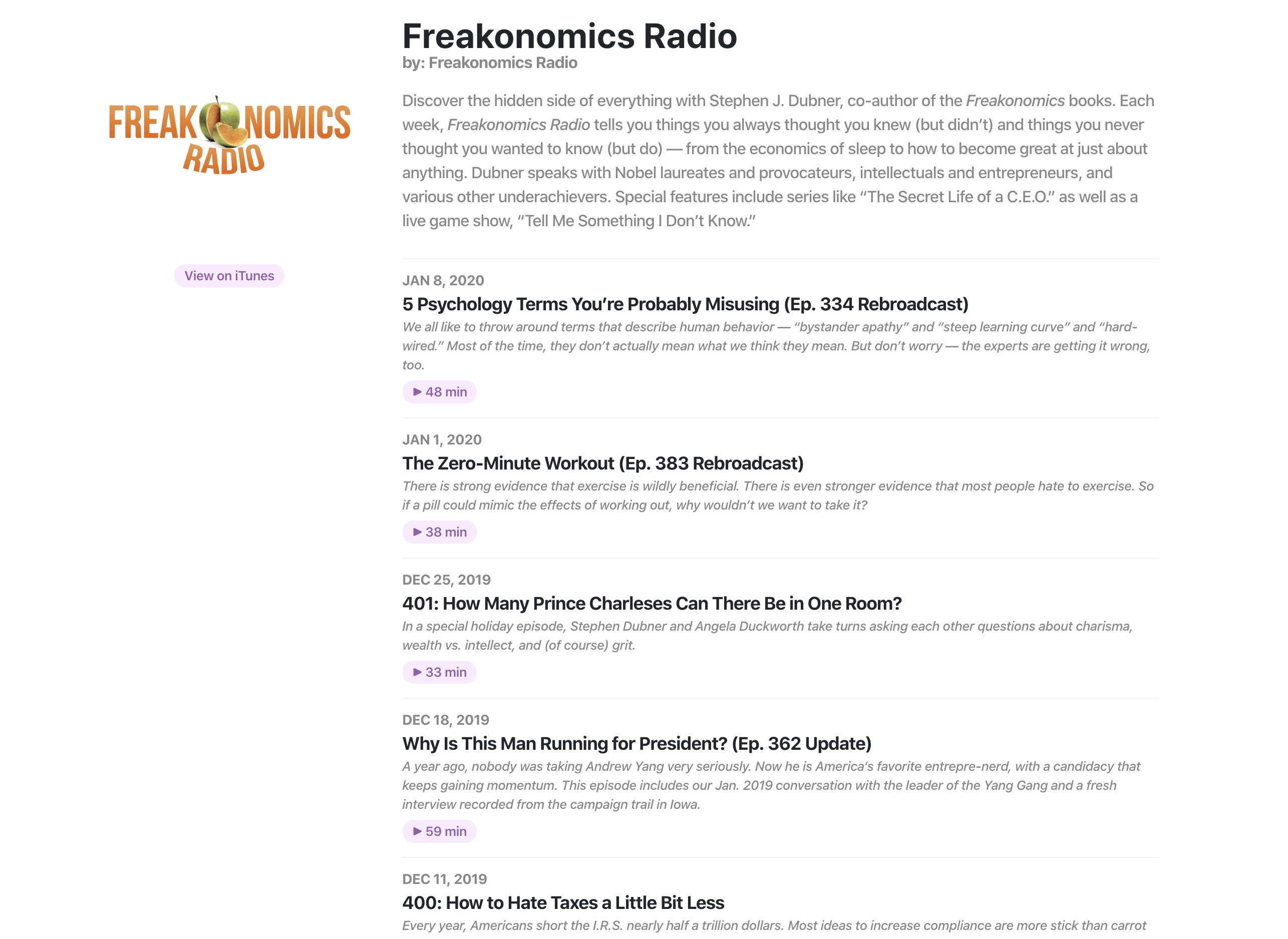
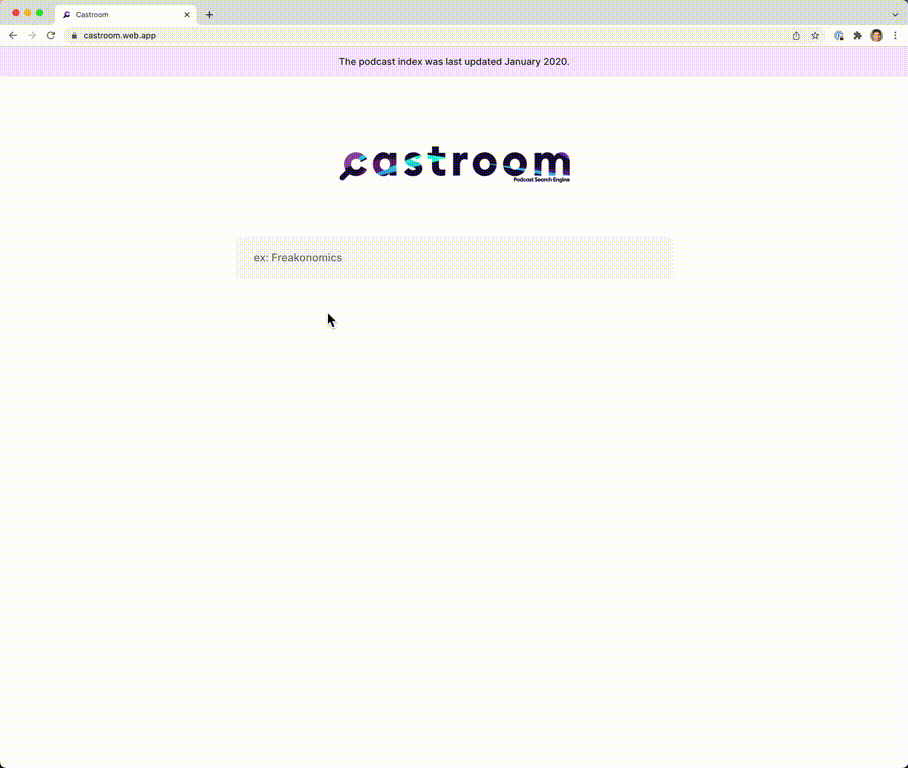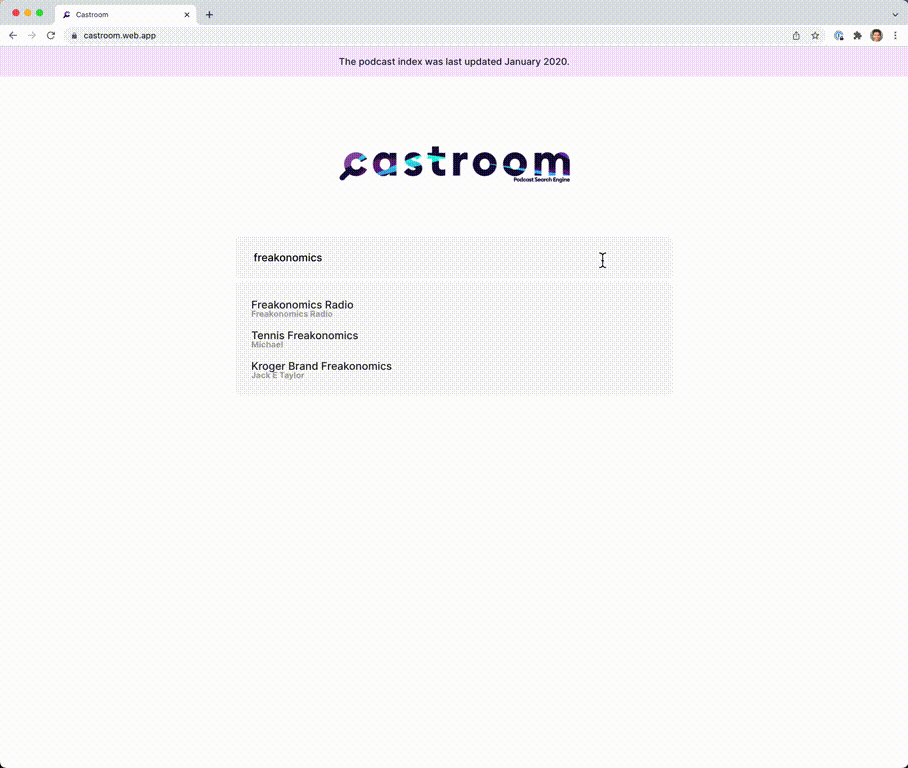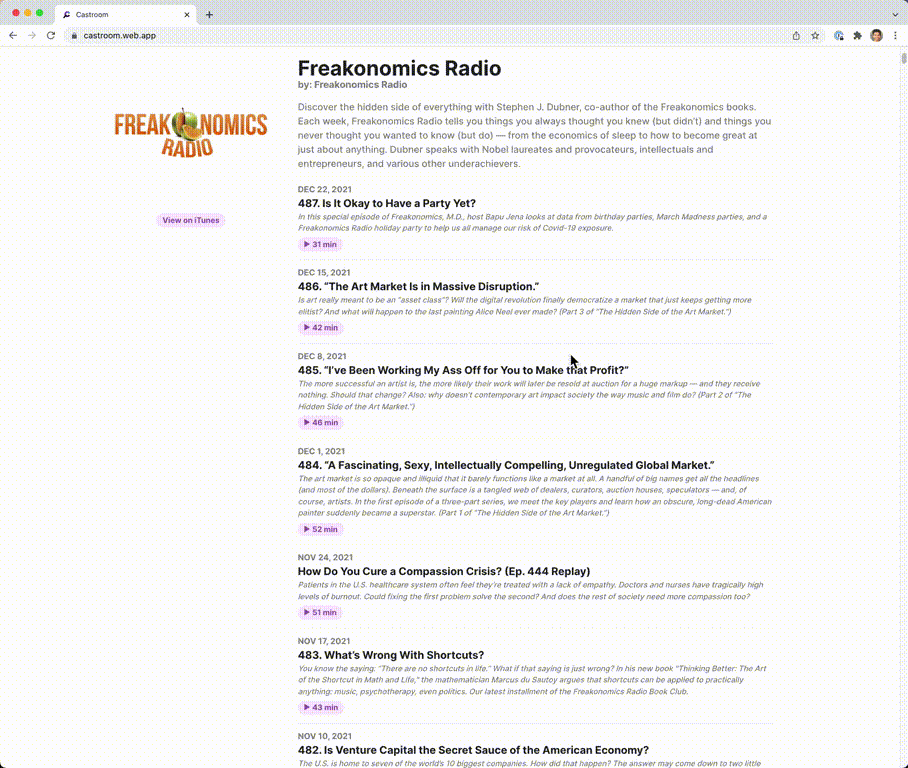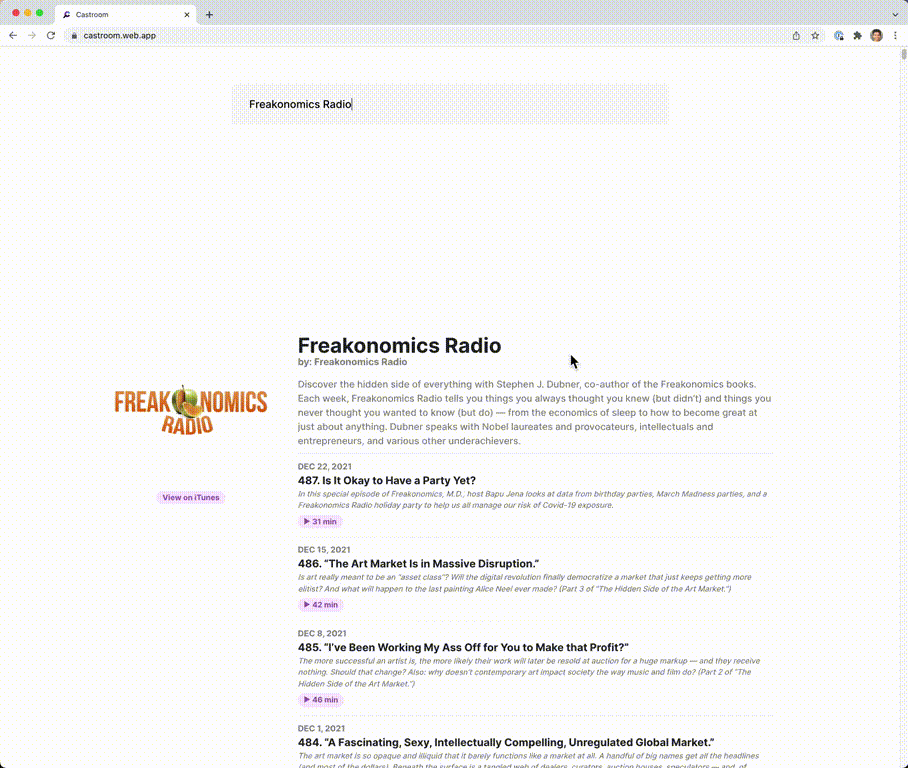
Captures d'écran