Überblick
Castroom ist eine Podcast -Suchmaschine. Mit Kubernetes wurde hauptsächlich gelernt, wie man einen verteilten Webcrawler erstellt. Es ist in der Lage, innerhalb weniger Stunden Hunderttausende von Podcasts zu sammeln und kann mit einem einfachen Befehl leicht mehr vergrößert werden.
Projektstruktur
Entdeckung
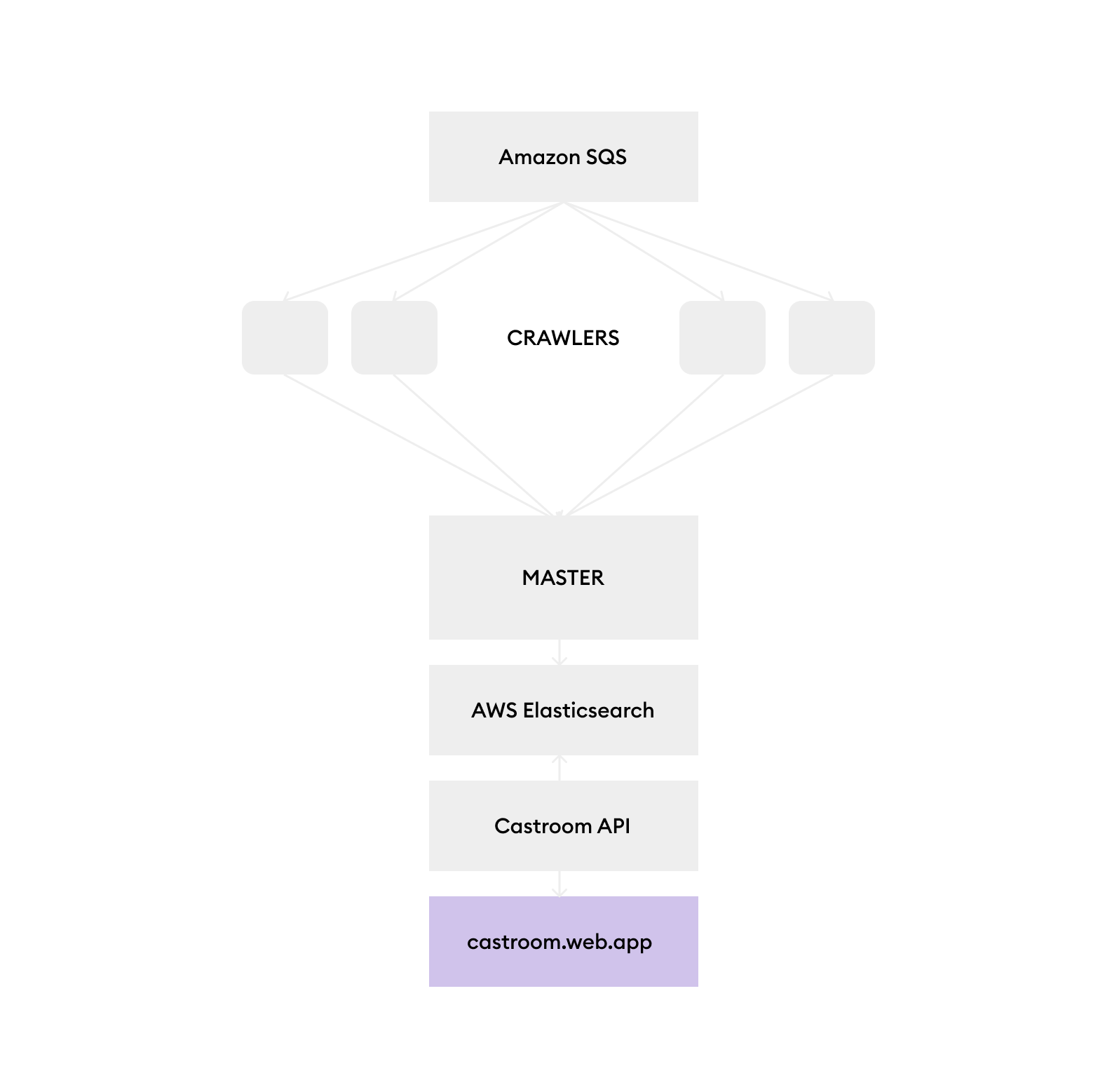
Master
- koordiniert alle
crawler -Jobs - Unterhält ein lokaler Cache (mit LevelDB), um zu verhindern, dass dieselbe URL mehrmals gekroppt wird
- Empfängt Daten von den
crawler -Knoten und drückt in die Warteschlange - Die
crawler -Knoten senden alle Daten nach dem Krabbeln einer Website an diesen Knoten an diesen Knoten - Senden Sie die Daten nach Abschluss an Elasticsearch
- von Google Kubernetes Engine verwaltet
Crawler
- Crawls iTunes Podcast -Seiten und sendet Charge Daten zum
master zum Zwischenspeichern - geht durch einen Stellvertreter, um bestimmte Beschränkungen zu umgehen
- von Google Kubernetes Engine verwaltet
API
- Bietet Endpunkte für die Abfrage von Elasticsearch und Abrufen von Podcast -Feed -Informationen
- Gastgeber auf Heroku
Netz
- Frontend für die Suchmaschine
- verwaltet von Firebase Hosting
Technologien verwendet
- Docker
- Google Kubernetes Engine
- Amazon einfacher Warteschlangenservice
- Amazon Elasticsearch Service
- Heroku
- Firebase Hosting
- Reagieren
- Node.js
- Leveldb
- Datadog
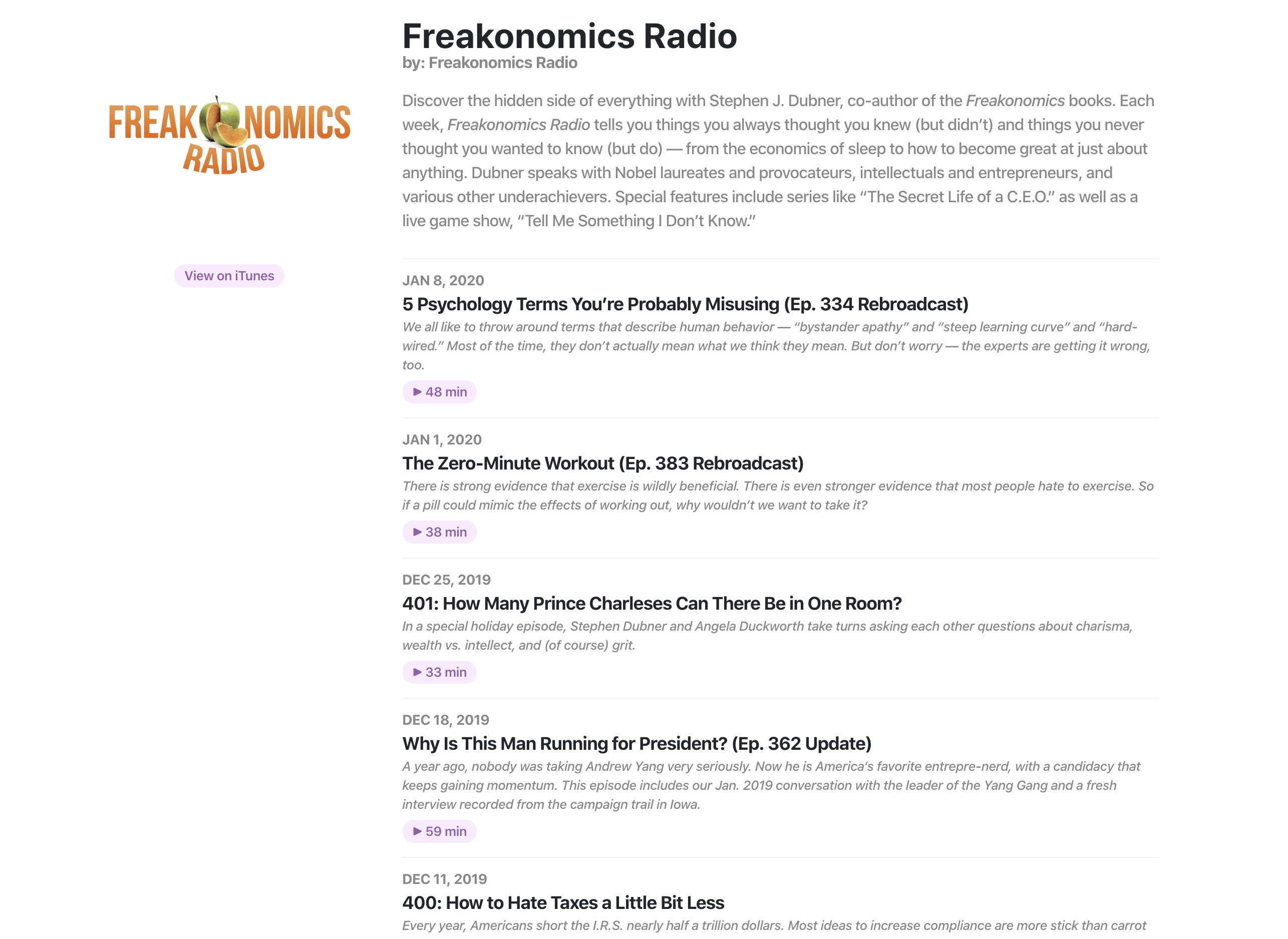
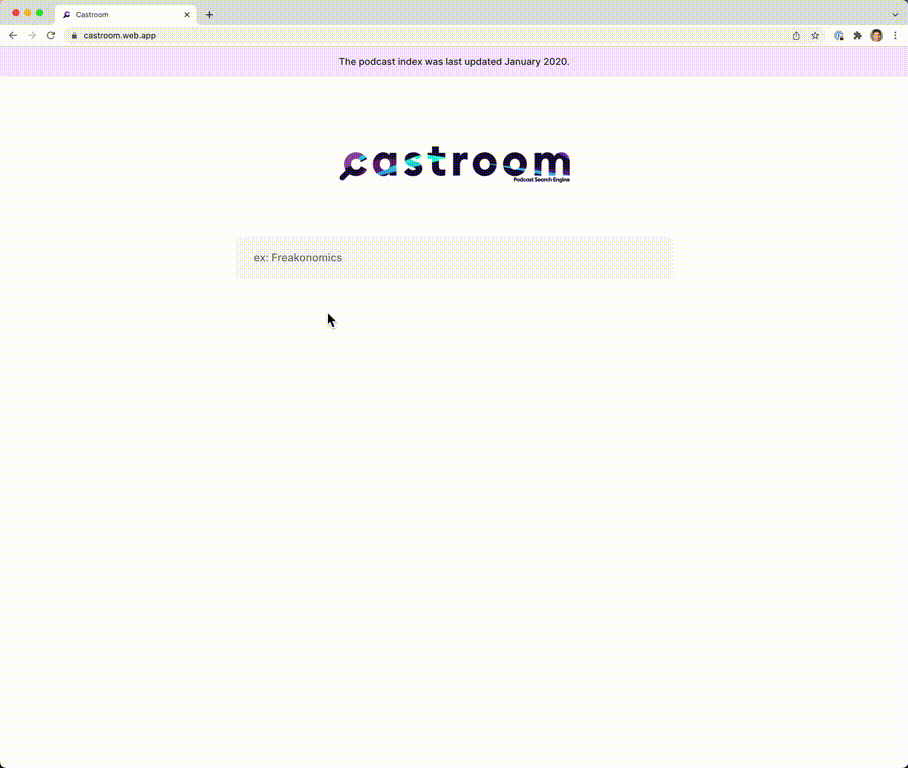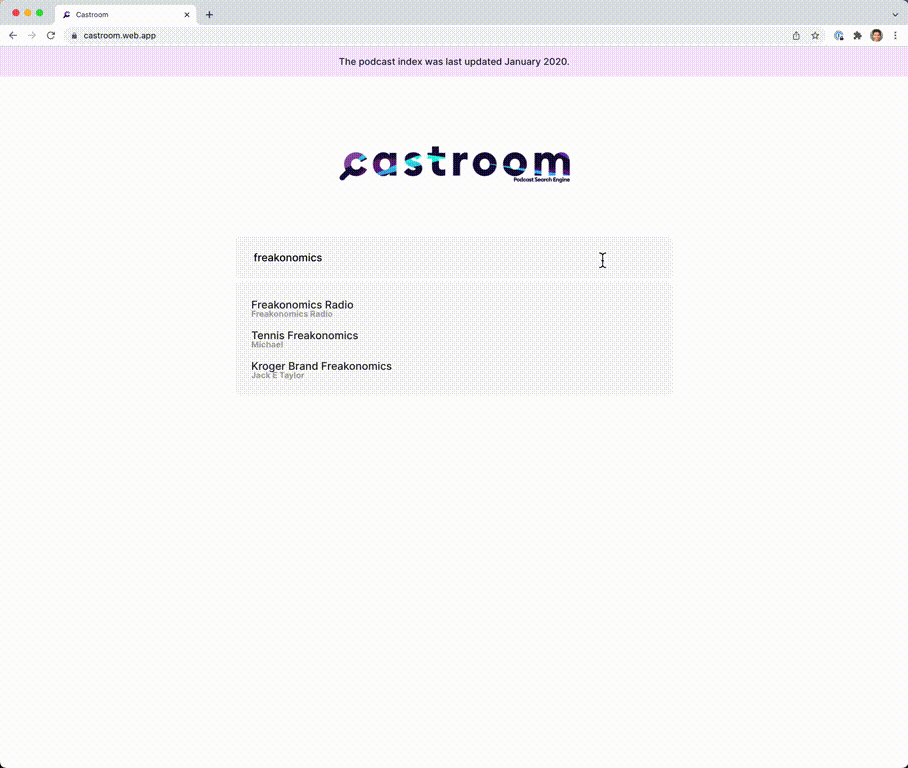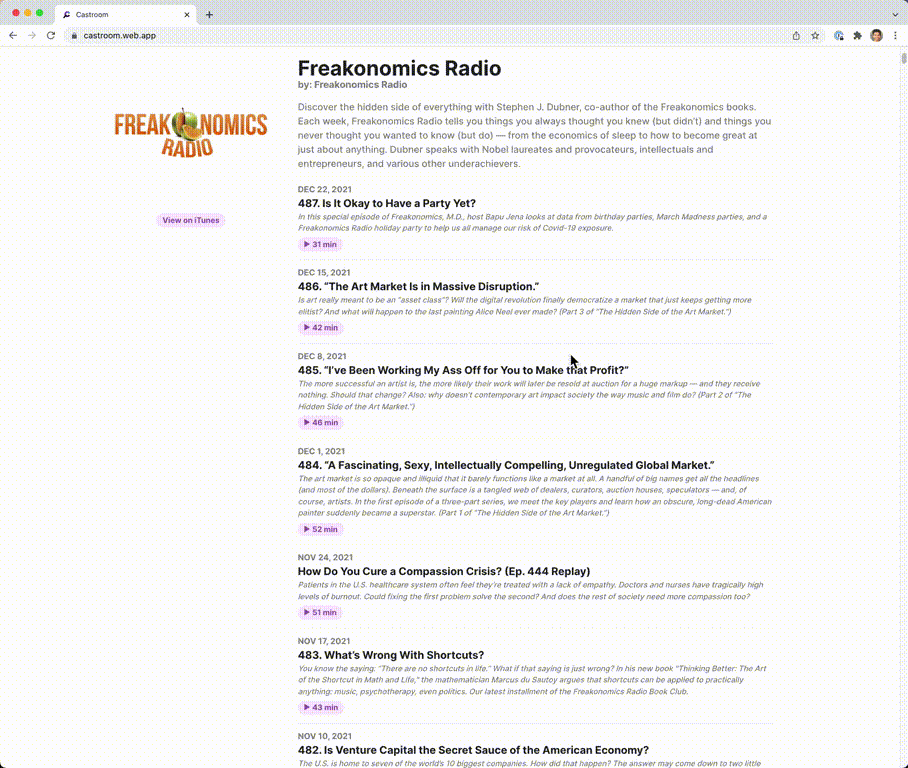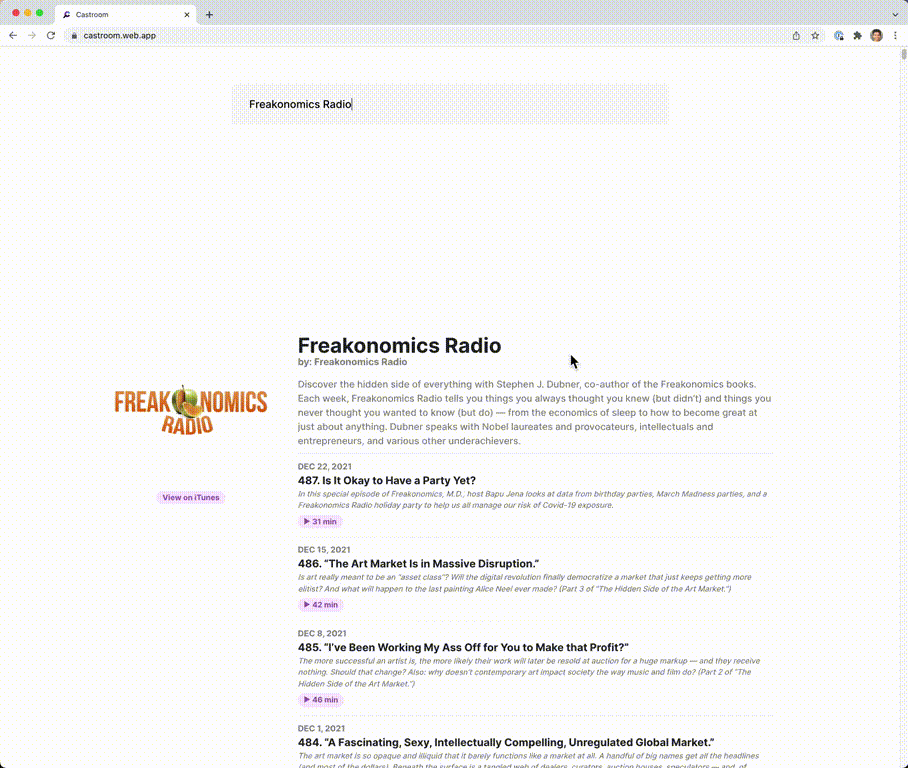
Screenshots