GODEL
1.0.0
(Actualización 23/10/2022) Hemos lanzado Godel V1.1, que está capacitado en diálogos de 551 m de múltiples vueltas desde el hilo de discusión de Reddit, y la instrucción de 5 m y los diálogos basados en el conocimiento. Ha mostrado resultados significativamente mejores en nuestro punto de referencia, especialmente en la configuración de disparo cero.
Consulte nuestras tarjetas modelo en el repositorio de Transformers Huggingface. Con varias líneas de código, debería ser bastante sencillo charlar con Godel. Aquí se muestra una demostración en vivo.
Modelo base: https://huggingface.co/microsoft/godel-v1_1-base-seq2seq
Modelo grande: https://huggingface.co/microsoft/godel-v1_1-large-seq2seq
Este repositorio muestra la creación de diálogo dirigido por objetivos con Godel, y contiene el conjunto de datos, el código fuente y el modelo previamente capacitado para el siguiente documento:
Godel: pre-entrenamiento a gran escala para el diálogo dirigido por objetivos
Baolin Peng, Michel Galley, Pengcheng HE, Chris Brockett, Lars Liden, Elnaz Nouri, Zhou Yu, Bill Dolan, Jianfeng Gao 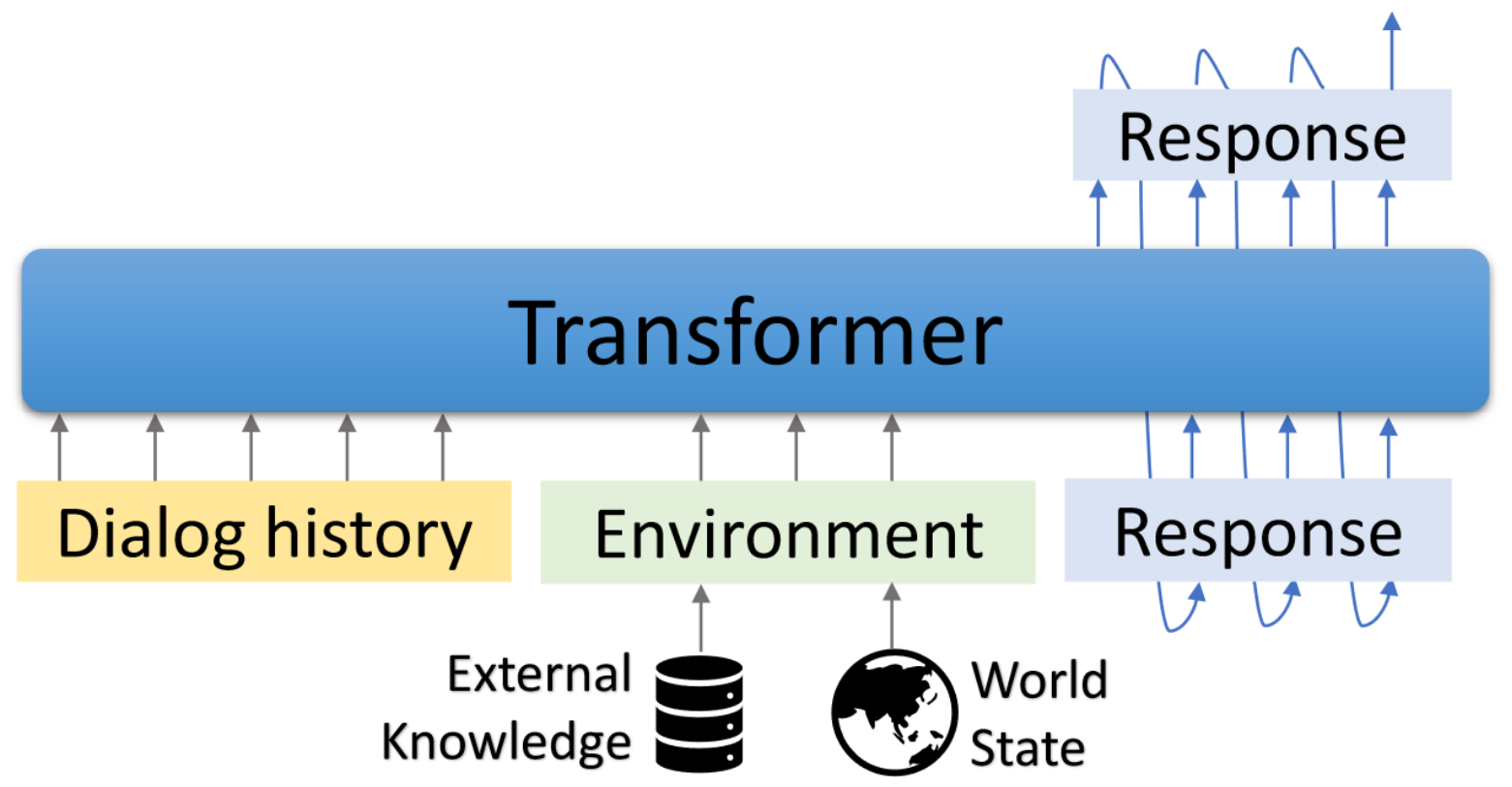
Godel es un modelo previamente capacitado a gran escala para diálogos dirigidos por objetivos. Se parametriza con un modelo de codificador codificador basado en transformador y capacitado para la generación de respuesta basada en texto externo, lo que permite un ajuste fino más efectivo en las tareas de diálogo que requieren acondicionar la respuesta de la información externa a la conversación actual (por ejemplo, un documento recuperado). El modelo previamente capacitado puede ajustarse de manera eficiente y adaptado para lograr una nueva tarea de diálogo con un puñado de diálogos específicos de tareas.
Este repositorio se basa en transformadores de Hugginface. Algunos scripts de evaluación y conjunto de datos están adaptados del modelado DSTC7-End-End-Conversation, Dialogpt, UnifiedQA, MS Marco, Multiwoz, conjunto de datos guiado por esquema, etc.
Los scripts incluidos se pueden usar para reproducir los resultados reportados en el documento. Página web de proyectos y demostraciones: https://aka.ms/godel
Requiere la interfaz interactiva requries node.js y npm . Consulte aquí para la instalación.
Utilice los siguientes comandos para crear el entorno, clonar el repositorio e instalar los paquetes requeridos.
conda create -n godel-env python=3.8
conda activate godel-env
conda install nodejs
git clone https://github.com/microsoft/GODEL.git
cd GODEL
pip install -r requirements.txt
export PYTHONPATH="`pwd`"
Obtenga y descompone el modelo previamente en función del cual continuar finetune sus propios datos.
wget https://bapengstorage.blob.core.windows.net/fileshare/godel_base.tar.gz
tar -zxvf godel_base.tar.gzFormato de datos
{
"Context" : " Please remind me of calling to Jessie at 2PM. " ,
"Knowledge" : " reminder_contact_name is Jessie, reminder_time is 2PM " ,
"Response" : " Sure, set the reminder: call to Jesse at 2PM "
},Usamos el formato JSON para representar un ejemplo de entrenamiento. Como se muestra en el ejemplo anterior, contiene los siguientes campos:
Sintonia FINA
DATA_NAME={path_of_data}
OUTPUT_DIR={path_of_fine-tuned_model}
MODEL_PATH={path_of_pre-trained_model}
EXP_NAME={experiment_name}
python train.py --model_name_or_path ${MODEL_PATH}
--dataset_name ${DATA_NAME}
--output_dir ${OUTPUT_DIR}
--per_device_train_batch_size=16
--per_device_eval_batch_size=16
--max_target_length 512
--max_length 512
--num_train_epochs 50
--save_steps 10000
--num_beams 5
--exp_name ${EXP_NAME} --preprocessing_num_workers 24Generación
DATA_NAME = { path_of_data }
OUTPUT_DIR = { path_to_save_predictions }
MODEL_PATH = { path_of_fine - tuned_model }
python generate . py - - model_name_or_path ${ MODEL_PATH }
- - dataset_name ${ DATA_NAME }
- - output_dir ${ OUTPUT_DIR }
- - per_device_eval_batch_size = 16
- - max_target_length 128
- - max_length 512
- - preprocessing_num_workers 24
- - num_beams 5 Interacción
Proporcionamos una interfaz de demostración para chatear con modelos Finetuned. El servidor de backend se basa en Flask y la interfaz se basa en Vue , Bootstrap-Vue y BasicVuechat .
Inicie el servidor de backend:
# Please create the backend server refering to e.g., dstc9_server.py
python EXAMPLE_server.py # start the sever and expose 8080 Comience a servir la página de Frontend:
cd GODEL/html
npm install
npm run serve Abra Localhost: 8080 En su navegador web, verá la siguiente página. Tenga en cuenta que el puerto de backend debe ser consistente con el puerto utilizado en HTML/Composents/Chat.vue.
Aquí se muestra una demostración en vivo.
Hemos lanzado Godel V1.1, que está capacitado en diálogos de 551 millones de múltiples giros del hilo de discusión de Reddit y de instrucción de 5 m y diálogos de conocimiento. Más modelos se lanzarán más adelante.
Hemos lanzado tres modelos ajustados que se pueden ajustar aún más en el conjunto de datos personalizado por los usuarios de baja recursos. Los parámetros totales en estos modelos varían de 117 m a 2.7b.
| Modelo | Tarjetas de modelo Huggingface |
|---|---|
| Base | Microsoft/Godel-V1_1-Base-SEQ2SEQ |
| Grande | Microsoft/Godel-V1_1-Large-seq2seq |
22/02/2023: ya no se admiten modelos de Godel previos a la base con nuestra base de código, pero los modelos Godel permanecen disponibles. Vea aquí para más detalles.
Godel está ajustado y evaluado en cuatro tareas. Proporcionamos scripts para crear datos de capacitación y prueba en nuestro formato. Consulte Create_Downstream_DataSet.sh para descargar los datos originales y ejecutar el siguiente CMD.
cd scripts
./create_downstream_dataset.shGROUNDED_CHECKPOINT={path_to_saved_checkpoint}
OUTPUT_DIR={path_to_save_predictions}
TASK=wow
accelerate launch --config_file configs/G16_config.yaml train.py
--model_name_or_path ${GROUNDED_CHECKPOINT}
--dataset_name ./datasets_loader/ ${TASK} _dataset.py
--output_dir ${OUTPUT_DIR}
--per_device_train_batch_size=16
--per_device_eval_batch_size=16
--max_target_length 256
--max_length 512
--num_train_epochs 10
--preprocessing_num_workers 24
--num_beams 5
--exp_name ${TASK}
--learning_rate 5e-5
--save_every_checkpoint
--save_steps 50000 En este tutorial, construirá un modelo de diálogo fundamentado basado en Godel para la tarea DSTC9. La información detallada se puede encontrar aquí.
Primero, descargue los datos y conviértalo en formato Godel.
cd examples/dstc9
./create_data.shFinetune con el modelo de Godel previamente capacitado
cd GODEL
GODEL_MODEL={path_to_pre-trained_model}
python train.py
--model_name_or_path ${GODEL_MODEL}
--dataset_name ../examples/dstc9/dstc9_dataset.py
--output_dir ../examples/dstc9/ckpt
--per_device_train_batch_size=16
--per_device_eval_batch_size=16
--max_target_length 128
--max_length 512
--num_train_epochs 50
--save_steps 10000
--num_beams 5
--exp_name wow-test
--preprocessing_num_workers 24
--save_every_checkpoint Interactuar con el modelo entrenado anteriormente
cd examples/dstc9
# replace model path in dstc9_server with a trained ckpt in line 49
python dstc9_server.py
cd GODEL/html
npm install
npm run serveEste repositorio tiene como objetivo facilitar la investigación en un cambio de paradigma de los bots de tareas de construcción a escala. Este kit de herramientas contiene solo parte de la maquinaria de modelado necesaria para producir un archivo de peso modelo en un diálogo en ejecución. Por sí solo, este modelo proporciona solo información sobre los pesos de varios tramos de texto; Para que un investigador lo use realmente, necesitará traer sus propios datos de conversación internos para futuros pre-entrenamiento y decodificar la generación de respuesta del sistema previado por eltrenado/Finetuned. Microsoft no es responsable de ninguna generación de la utilización de terceros del sistema previo a la aparición.
Si usa este código y datos en su investigación, cite nuestro documento ARXIV:
@misc{peng2022godel,
author = {Peng, Baolin and Galley, Michel and He, Pengcheng and Brockett, Chris and Liden, Lars and Nouri, Elnaz and Yu, Zhou and Dolan, Bill and Gao, Jianfeng},
title = {GODEL: Large-Scale Pre-training for Goal-Directed Dialog},
howpublished = {arXiv},
year = {2022},
month = {June},
url = {https://www.microsoft.com/en-us/research/publication/godel-large-scale-pre-training-for-goal-directed-dialog/},
}
Este proyecto da la bienvenida a las contribuciones y sugerencias. La mayoría de las contribuciones requieren que acepte un Acuerdo de Licencia de Contributor (CLA) que declare que tiene derecho y realmente hacernos los derechos para utilizar su contribución. Para más detalles, visite https://cla.opensource.microsoft.com.
Cuando envíe una solicitud de extracción, un BOT CLA determinará automáticamente si necesita proporcionar un CLA y decorar el PR adecuadamente (por ejemplo, verificación de estado, comentario). Simplemente siga las instrucciones proporcionadas por el bot. Solo necesitará hacer esto una vez en todos los reposos usando nuestro CLA.
Este proyecto ha adoptado el Código de Conducta Open Open Microsoft. Para obtener más información, consulte el Código de Conducta Preguntas frecuentes o comuníquese con [email protected] con cualquier pregunta o comentario adicional.
Este proyecto puede contener marcas comerciales o logotipos para proyectos, productos o servicios. El uso autorizado de marcas o logotipos de Microsoft está sujeto y debe seguir las pautas de marca y marca de Microsoft. El uso de marcas registradas de Microsoft o logotipos en versiones modificadas de este proyecto no debe causar confusión o implicar el patrocinio de Microsoft. Cualquier uso de marcas comerciales o logotipos de terceros está sujeto a las políticas de esas partes de terceros.


