GODEL
1.0.0
(Update 23.10.2022) Wir haben Godel v1.1 veröffentlicht, das auf 551M Multi-Turn-Dialogen aus dem Reddit-Diskussionsthread sowie in 5m-Anweisungen und den dialogen geerdeten Wissensdialogen trainiert wird. In unserem Benchmark hat es signifikant bessere Ergebnisse gezeigt, insbesondere in der Null-Shot-Einstellung.
Bitte besuchen Sie unsere Modellkarten im Repository von Huggingface -Transformatoren. Mit mehreren Codezeilen sollte es ziemlich einfach sein, mit Godel zu plaudern. Hier wird eine lebende Demo gezeigt.
Basismodell: https://huggingface.co/microsoft/godel-v1_1-base-seq2seq
Großes Modell: https://huggingface.co/microsoft/godel-v1_1-large-seq2seq
Dieses Repository zeigt, dass das zielgerichtete Dialog mit Godel erstellt und den Datensatz, den Quellcode und das vorgebrachte Modell für das folgende Papier enthält:
Godel: Große Vorausbildung für den zielgerichteten Dialog
Baolin Peng, Michel Galley, Pengcheng HE, Chris Brockett, Lars Liden, Elnaz Nouri, Zhou Yu, Bill Dolan, Jianfeng Gao 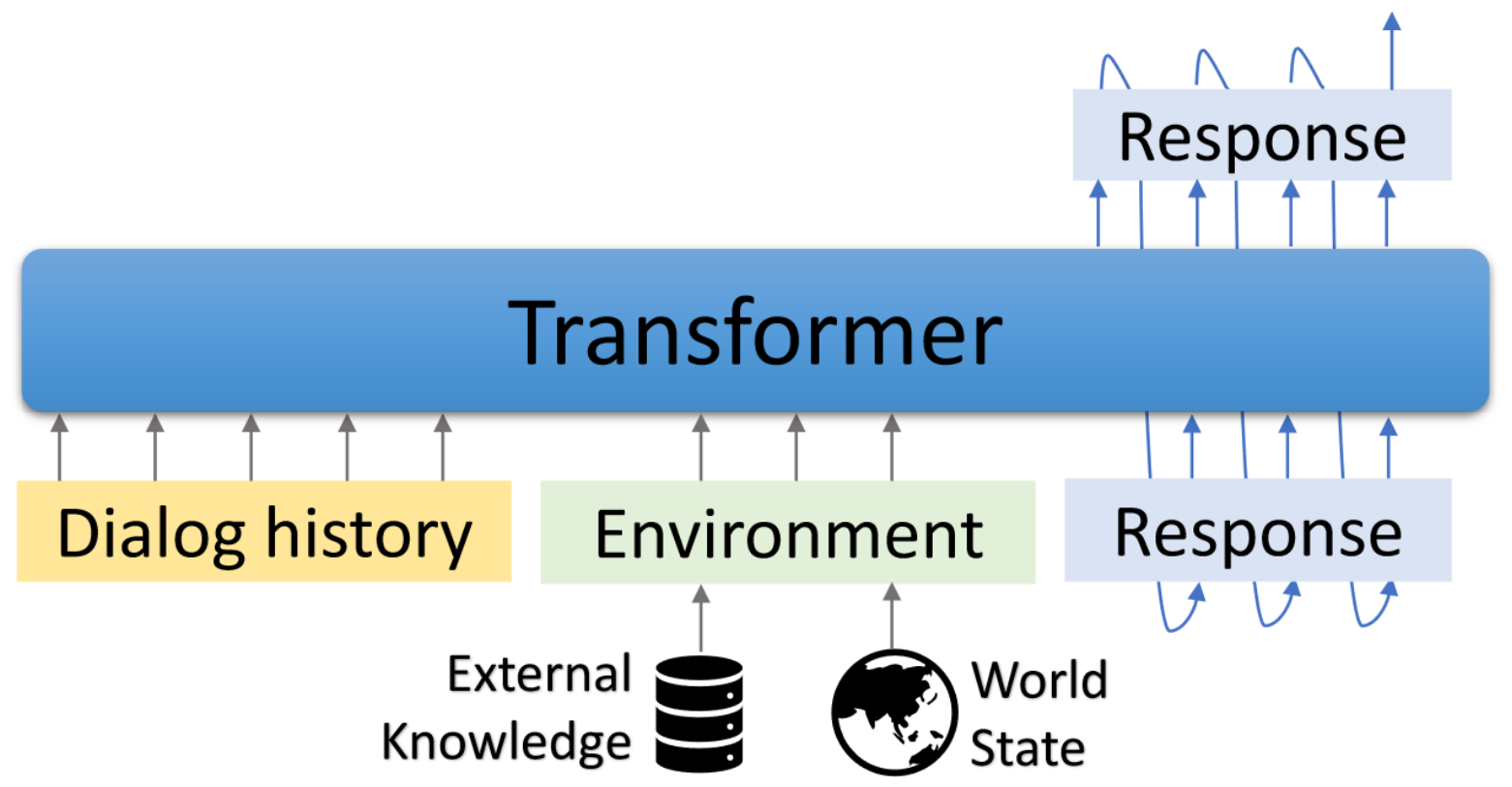
Godel ist ein großes vorgebildetes Modell für zielgerichtete Dialoge. Es ist mit einem transformator-basierten Encoder-Decoder-Modell parametrisiert und für die in externen Text gegründete Antwortgenerierung trainiert, wodurch eine effektivere Feinabstimmung bei Dialogaufgaben ermöglicht wird, für die die Antwort auf Informationen, die extern in der aktuellen Konversation sind (z. B. ein abgerufenes Dokument), konditioniert werden müssen. Das vorgebreitete Modell kann effizient fein abgestimmt und angepasst werden, um eine neue Dialogaufgabe mit einer Handvoll aufgabenspezifischer Dialoge zu erfüllen.
Dieses Repository basiert auf Hugginface -Transformatoren. Einige Evaluierungsskripte und Datensatz sind von DSTC7-End-zu-End-Konvertierungsmodelling, Dialogpt, Unifiedqa, MS Marco, Multiwoz, Schema-gesteuerter Datensatz usw. angepasst.
Die enthaltenen Skripte können verwendet werden, um die im Papier angegebenen Ergebnisse zu reproduzieren. Projekt- und Demo -Webseite: https://aka.ms/godel
Benötigt die interaktive Schnittstelle, die Node.js und NPM reaktions. Weitere Informationen zur Installation finden Sie hier.
Bitte verwenden Sie die folgenden Befehle, um die Umgebung zu erstellen, das Repo zu klonen und die erforderlichen Pakete zu installieren.
conda create -n godel-env python=3.8
conda activate godel-env
conda install nodejs
git clone https://github.com/microsoft/GODEL.git
cd GODEL
pip install -r requirements.txt
export PYTHONPATH="`pwd`"
Abrufen und entpacken Sie das vorgezogene Modell, basierend darauf, um Ihre eigenen Daten weiter zu beenden.
wget https://bapengstorage.blob.core.windows.net/fileshare/godel_base.tar.gz
tar -zxvf godel_base.tar.gzDatenformat
{
"Context" : " Please remind me of calling to Jessie at 2PM. " ,
"Knowledge" : " reminder_contact_name is Jessie, reminder_time is 2PM " ,
"Response" : " Sure, set the reminder: call to Jesse at 2PM "
},Wir verwenden JSON -Format, um ein Trainingsbeispiel darzustellen. Wie im obigen Beispiel gezeigt, enthält es die folgenden Felder:
Feinabstimmung
DATA_NAME={path_of_data}
OUTPUT_DIR={path_of_fine-tuned_model}
MODEL_PATH={path_of_pre-trained_model}
EXP_NAME={experiment_name}
python train.py --model_name_or_path ${MODEL_PATH}
--dataset_name ${DATA_NAME}
--output_dir ${OUTPUT_DIR}
--per_device_train_batch_size=16
--per_device_eval_batch_size=16
--max_target_length 512
--max_length 512
--num_train_epochs 50
--save_steps 10000
--num_beams 5
--exp_name ${EXP_NAME} --preprocessing_num_workers 24Generation
DATA_NAME = { path_of_data }
OUTPUT_DIR = { path_to_save_predictions }
MODEL_PATH = { path_of_fine - tuned_model }
python generate . py - - model_name_or_path ${ MODEL_PATH }
- - dataset_name ${ DATA_NAME }
- - output_dir ${ OUTPUT_DIR }
- - per_device_eval_batch_size = 16
- - max_target_length 128
- - max_length 512
- - preprocessing_num_workers 24
- - num_beams 5 Interaktion
Wir bieten eine Demo -Schnittstelle, um mit feindlichen Modellen zu chatten. Der Backend-Server basiert auf Flask und die Schnittstelle basiert auf Vue , Bootstrap-vue und BasicVuechat .
Starten Sie den Backend Server:
# Please create the backend server refering to e.g., dstc9_server.py
python EXAMPLE_server.py # start the sever and expose 8080 Beginnen Sie mit dem Servieren von Frontend -Seite:
cd GODEL/html
npm install
npm run serve Öffnen Sie Localhost: 8080 In Ihrem Webbrowser sehen Sie die folgende Seite. Beachten Sie, dass der Backend -Port mit dem Port in HTML/Compoents/chat.vue übereinstimmt.
Hier wird eine lebende Demo gezeigt.
Wir haben Godel v1.1 veröffentlicht, das auf 551 m-Multiturn-Dialogen aus Reddit-Diskussionsthread und 5m Anweisungen und wissensgelegenen Dialogen geschult ist. Weitere Modelle werden später veröffentlicht.
Wir haben drei fein abgestimmte Modelle veröffentlicht, die im benutzerdefinierten Datensatz mit niedrigressourcenem Benutzer weiter abgestimmt werden können. Die Gesamtparameter in diesen Modellen reichen von 117 m bis 2,7B.
| Modell | Modellkarten umarmen |
|---|---|
| Base | Microsoft/Godel-V1_1-Base-seq2seq |
| Groß | Microsoft/Godel-V1_1-Large-seq2seq |
22.05.2023: Die Vorab -Godel -Modelle mit unserer Codebasis werden nicht mehr unterstützt, aber Godel -Modelle bleiben verfügbar. Weitere Informationen finden Sie hier.
Godel ist fein abgestimmt und bei vier Aufgaben bewertet. Wir stellen Skripte zur Verfügung, um Schulungs- und Testen von Daten in unserem Format zu erstellen. Weitere Informationen finden Sie unter create_downstream_dataset.sh, um die Originaldaten herunterzuladen und die folgenden CMD auszuführen.
cd scripts
./create_downstream_dataset.shGROUNDED_CHECKPOINT={path_to_saved_checkpoint}
OUTPUT_DIR={path_to_save_predictions}
TASK=wow
accelerate launch --config_file configs/G16_config.yaml train.py
--model_name_or_path ${GROUNDED_CHECKPOINT}
--dataset_name ./datasets_loader/ ${TASK} _dataset.py
--output_dir ${OUTPUT_DIR}
--per_device_train_batch_size=16
--per_device_eval_batch_size=16
--max_target_length 256
--max_length 512
--num_train_epochs 10
--preprocessing_num_workers 24
--num_beams 5
--exp_name ${TASK}
--learning_rate 5e-5
--save_every_checkpoint
--save_steps 50000 In diesem Tutorial erstellen Sie ein geerdetes Dialogmodell, das auf Godel für die DSTC9 -Aufgabe basiert. Detaillierte Informationen finden Sie hier.
Laden Sie zunächst die Daten herunter und konvertieren Sie sie in das Godel -Format.
cd examples/dstc9
./create_data.shFinetune mit dem vorgebildeten Godel-Modell
cd GODEL
GODEL_MODEL={path_to_pre-trained_model}
python train.py
--model_name_or_path ${GODEL_MODEL}
--dataset_name ../examples/dstc9/dstc9_dataset.py
--output_dir ../examples/dstc9/ckpt
--per_device_train_batch_size=16
--per_device_eval_batch_size=16
--max_target_length 128
--max_length 512
--num_train_epochs 50
--save_steps 10000
--num_beams 5
--exp_name wow-test
--preprocessing_num_workers 24
--save_every_checkpoint Interagieren Sie mit dem obigen trainierten Modell
cd examples/dstc9
# replace model path in dstc9_server with a trained ckpt in line 49
python dstc9_server.py
cd GODEL/html
npm install
npm run serveDieses Repository zielt darauf ab, die Forschung in einer Paradigmenverschiebung der Bots der Bauaufgaben im Maßstab zu erleichtern. Dieses Toolkit enthält nur einen Teil der Modellierungsmaschinerie, die erforderlich sind, um tatsächlich eine Modellgewichtsdatei in einem ausgeführten Dialog zu erstellen. Dieses Modell enthält nur Informationen über die Gewichte verschiedener Textspannen. Damit ein Forscher es tatsächlich nutzt, müssen sie eigene Gesprächsdaten für zukünftige Voraussetzungen mitbringen und die Reaktionsgenerierung aus dem vorgefertigten/bestrichenen System dekodieren. Microsoft ist für keine Generation aus der Nutzung des vorbereiteten Systems der Drittanbieter verantwortlich.
Wenn Sie diesen Code und diese Daten in Ihrer Forschung verwenden, zitieren Sie bitte unser Arxiv -Papier:
@misc{peng2022godel,
author = {Peng, Baolin and Galley, Michel and He, Pengcheng and Brockett, Chris and Liden, Lars and Nouri, Elnaz and Yu, Zhou and Dolan, Bill and Gao, Jianfeng},
title = {GODEL: Large-Scale Pre-training for Goal-Directed Dialog},
howpublished = {arXiv},
year = {2022},
month = {June},
url = {https://www.microsoft.com/en-us/research/publication/godel-large-scale-pre-training-for-goal-directed-dialog/},
}
Dieses Projekt begrüßt Beiträge und Vorschläge. In den meisten Beiträgen müssen Sie einer Mitarbeiters Lizenzvereinbarung (CLA) zustimmen, in der Sie erklären, dass Sie das Recht haben und uns tatsächlich tun, um uns die Rechte zu gewähren, Ihren Beitrag zu verwenden. Weitere Informationen finden Sie unter https://cla.opensource.microsoft.com.
Wenn Sie eine Pull -Anfrage einreichen, bestimmt ein CLA -Bot automatisch, ob Sie einen CLA angeben und die PR angemessen dekorieren müssen (z. B. Statusprüfung, Kommentar). Befolgen Sie einfach die vom Bot bereitgestellten Anweisungen. Sie müssen dies nur einmal über alle Repos mit unserem CLA tun.
Dieses Projekt hat den Microsoft Open Source -Verhaltenscode übernommen. Weitere Informationen finden Sie im FAQ oder wenden Sie sich an [email protected] mit zusätzlichen Fragen oder Kommentaren.
Dieses Projekt kann Marken oder Logos für Projekte, Produkte oder Dienstleistungen enthalten. Die autorisierte Verwendung von Microsoft -Marken oder Logos unterliegt den Marken- und Markenrichtlinien von Microsoft und muss folgen. Die Verwendung von Microsoft -Marken oder Logos in geänderten Versionen dieses Projekts darf keine Verwirrung verursachen oder Microsoft -Sponsoring implizieren. Jede Verwendung von Marken oder Logos von Drittanbietern unterliegt den Richtlinien dieses Drittanbieters.


