sentiment_analysis_fine_grain
1.0.0
Con este repositorio, podrá capacitar a la clasificación de múltiples etiquetas con Bert,
Implemente Bert para la predicción en línea.
También puede encontrar el tutorial un breve de cómo usar Bert con chino: Bert Short Chinese Tutorial
Puede encontrar la introducción al sentimiento de grano fino de AI Challenger
Agregue algo aquí.
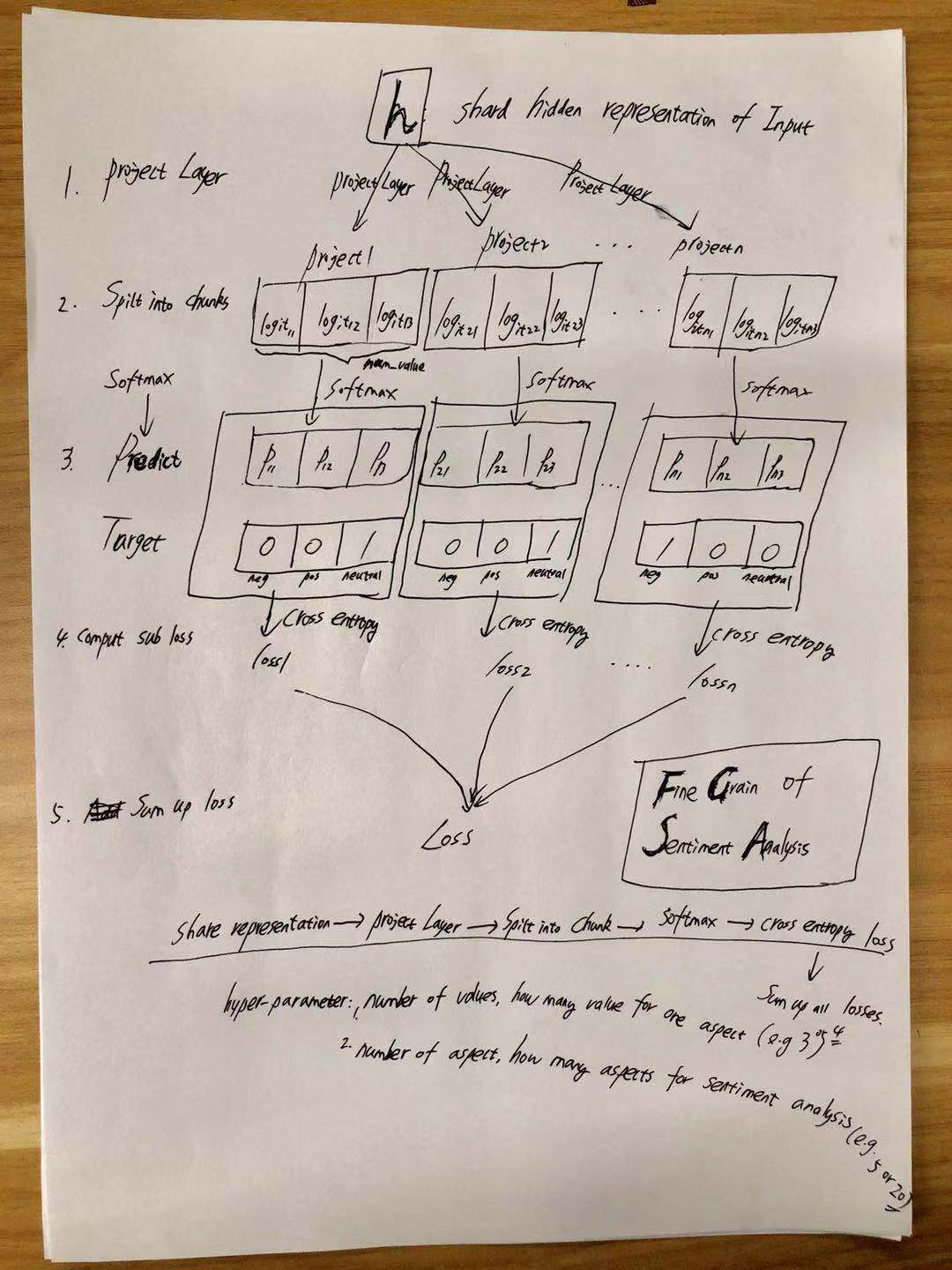
Para obtener más información, verifique el modelo/bert_cnn_fine_grain_model.py
| Modelo | Textcnn (sin pretratamiento) | TextCnn (Pretrain-Finetuning) | Bert (base_model_zh) | Bert (base_model_zh, pre-entrenado en corpus) |
|---|---|---|---|---|
| Puntaje F1 | 0.678 | 0.685 | Agrega un número aquí | Agrega un número aquí |
Aviso: el puntaje F1 se informa en el conjunto de validación

export BERT_BASE_DIR=BERT_BASE_DIR/chinese_L-12_H-768_A-12
export TEXT_DIR=TEXT_DIR
nohup python run_classifier_multi_labels_bert.py
--task_name=sentiment_analysis
--do_train=true
--do_eval=true
--data_dir=$TEXT_DIR
--vocab_file=$BERT_BASE_DIR/vocab.txt
--bert_config_file=$BERT_BASE_DIR/bert_config.json
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt
--max_seq_length=512
--train_batch_size=4
--learning_rate=2e-5
--num_train_epochs=3
--output_dir=./checkpoint_bert &
1. Primero, debe descargar el modelo previamente capacitado de Google y poner en una carpeta (egbert_base_dir)
chinese_L-12_H-768_A-12 from <a href='https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip'>bert</a>
2. Secondly, debe tener datos de capacitación (por ejemplo, Train.TSV) y datos de validación (por ejemplo, dev.tsv), y ponerlos bajo un
folder(e.g.TEXT_DIR ). you can also download data from here <a href='https://pan.baidu.com/s/1ZS4dAdOIAe3DaHiwCDrLKw'>data to train bert for AI challenger-Sentiment Analysis</a>.
it contains processed data you can run for both fine-tuning on sentiment analysis and pre-train with Bert.
it is generated by following this notebook step by step:
preprocess_char.ipynb
you can generate data by yourself as long as data format is compatible with
processor SentimentAnalysisFineGrainProcessor(alias as sentiment_analysis);
data format: label1,label2,label3t here is sentence or sentencest
it only contains two columns, the first one is target(one or multi-labels), the second one is input strings.
no need to tokenized.
sample:"0_1,1_-2,2_-2,3_-2,4_1,5_-2,6_-2,7_-2,8_1,9_1,10_-2,11_-2,12_-2,13_-2,14_-2,15_1,16_-2,17_-2,18_0,19_-2 浦东五莲路站,老饭店福瑞轩属于上海的本帮菜,交通方便,最近又重新装修,来拨草了,饭店活动满188元送50元钱,环境干净,简单。朋友提前一天来预订包房也没有订到,只有大堂,五点半到店基本上每个台子都客满了,都是附近居民,每道冷菜量都比以前小,味道还可以,热菜烤茄子,炒河虾仁,脆皮鸭,照牌鸡,小牛排,手撕腊味花菜等每道菜都很入味好吃,会员价划算,服务员人手太少,服务态度好,要能团购更好。可以用支付宝方便"
check sample data in ./BERT_BASE_DIR folder
for more detail, check create_model and SentimentAnalysisFineGrainProcessor from run_classifier.py
Genere datos sin procesar: [Agregue algo aquí]
Asegúrese de que cada línea es una oración. Entre cada documento hay una línea en blanco.
Puede encontrar datos generados del archivo zip.
use write_pre_train_doc() from preprocess_char.ipynb
Genere datos para la etapa previa al entrenamiento utilizando:
export BERT_BASE_DIR=./BERT_BASE_DIR/chinese_L-12_H-768_A-12
nohup python create_pretraining_data.py
--input_file=./PRE_TRAIN_DIR/bert_*_pretrain.txt
--output_file=./PRE_TRAIN_DIR/tf_examples.tfrecord
--vocab_file=$BERT_BASE_DIR/vocab.txt
--do_lower_case=True
--max_seq_length=512
--max_predictions_per_seq=60
--masked_lm_prob=0.15
--random_seed=12345
--dupe_factor=5 nohup_pre.out &
Modelo previo al entrenamiento con datos generados:
python run_pretraining.py
sintonia FINA
python run_classifier.py
Descargue el archivo de caché del análisis de sentimientos (los tokens están en nivel de palabra)
Entrena el modelo:
Python Train_CNN_Fine_Grain.py
cache file of TextCNN model was generate by following steps from preprocess_word.ipynb.
it contains everything you need to run TextCNN.
it include: processed train/validation/test set; vocabulary of word; a dict map label to index.
take train_valid_test_vocab_cache.pik and put it under folder of preprocess_word/
raw data are also included in this zip file.
Textcnn de pre-entrenamiento con modelo de lenguaje enmascarado
Python Train_cnn_lm.py
ajuste fino para textcnn
Python Train_CNN_Fine_Grain.py
with session and feed style you can easily deploy BERT.
Predicción en línea con Bert, consulte más desde aquí
Representaciones de codificadores bidireccionales de Transformers para la comprensión del lenguaje
Google-Research/Bert
Pengshuang/Ai-Comp
AI Challenger 2018
Redes neuronales convolucionales para la clasificación de oraciones


