Silero TTS Service
1.0.0
He creado este proyecto para proporcionar a mi hogar inteligente una síntesis normal del habla. Además, para proporcionar a Rhasspy una síntesis normal del habla. Las soluciones hechas ya listas no me quedaban y se decidió inventar su bicicleta. Los modelos Silero fueron tomados como base.
Me inspiré en el proyecto Silero-Ha-Http-TTS de Gromina. Estaba húmedo y decidí hacer todo en mente, con configuraciones y contenedores preparados.
Sigue el comando:
docker run -p 9898:9898 -m 1g -e NUMBER_OF_THREADS=4 -e LANGUAGE=ru -e SAMPLE_RATE=48000 --name tts_silero -d navatusein/silero-tts-service
Cree un archivo docker-compose.yml y transfiera el contenido:
version : ' 3 '
services :
silero-tts-service :
image : " navatusein/silero-tts-service "
container_name : " silero-tts-service "
deploy :
resources :
limits :
memory : 1G
ports :
- " 9898:9898 "
restart : unless-stopped
environment :
NUMBER_OF_THREADS : 4
LANGUAGE : ru
SAMPLE_RATE : 48000Sigue el comando:
docker-compose up
Todas las configuraciones del servidor se transmiten como parámetros de entorno Docker al contenedor al comenzar.
El número de núcleos para el número de procesamiento del NUMBER_OF_THREADS :
NUMBER_OF_THREADS : 4 El número de flujos de 1 al número de núcleos de procesador del servidor.
Por defecto: 4
Lenguaje Síntesis LANGUAGE :
LANGUAGE : ru Por defecto: ru
Idiomas apoyados con votos disponibles para ellos:
| Idioma | Código de idioma | Voces compatibles |
|---|---|---|
| ruso | ru | aidar baya kseniya xenia eugene random |
| ucranio | uk | mykyta random |
Frecuencia de muestreo SAMPLE_RATE :
SAMPLE_RATE : 48000 Valores posibles: 48000 , 24000 , 8000
Por defecto: 48000
Parámetros de utilidad SOX SOX_PARAM :
SOX_PARAM : " reverb 50 50 10 " # Добавляет эхо на речьPor defecto: vacío
El archivo de salida pasa a través de la utilidad SOX. Ella puede transmitir los parámetros para imponer efectos en el discurso: elevar el timbre, agregar un eco, encender el impulso de bajo.
Enlace a la documentación de la utilidad de los Sox: https://linux.die.net/man/1/sox
Corrección del fraude del final de la frase HA_FIX :
HA_FIX : True Puede tomar valores: True False
Por defecto: False
Corrige un error en el que el asistente de origen no está de acuerdo en el final de la frase. Agrega un segundo de silencio al final del discurso.
En el archivo configuration.yaml , agregue un registro:
tts :
- platform : marytts
host : localhost # Адрес сервера
port : 9898
codec : WAVE_FILE
voice : xenia # Имя голоса который хотите использовать.
language : ru # Не используется. Настройки языка указываются в настройках сервера. /process .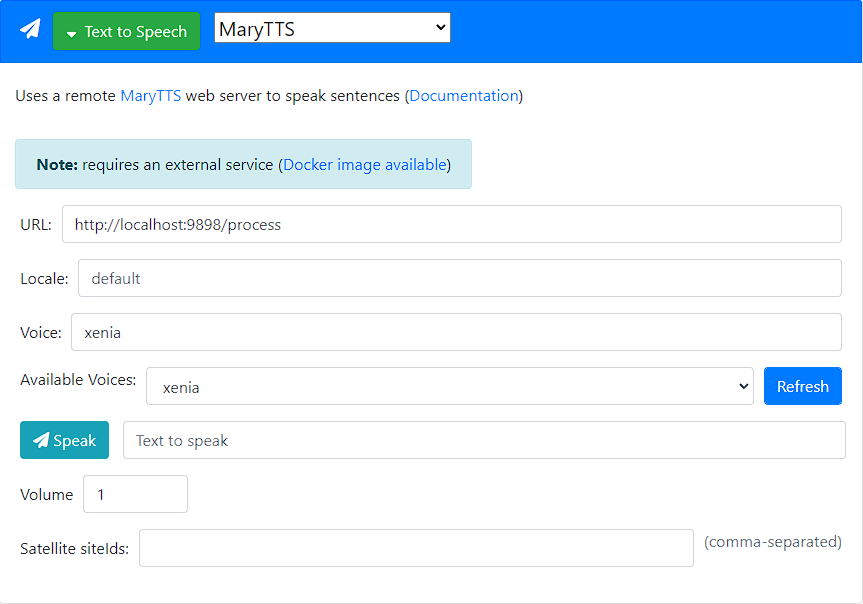
El servicio puede traducir los números en texto.
Ejemplo:
Текст с цифрой 1.
Normalización Ejemplo 1
El servicio puede inclinar los sustantivos después de los números.
Para hacer esto, la palabra que debe persuadir después del número, tome <d>слово</d> .
Ejemplo:
У меня было 15 <d>яблоко</d>.
Rlowing Ejemplo 1
Si necesita persuadir algunas palabras, cada una debe tomarse en la etiqueta <d>слово</d> por separado.
Мне осталось работать 15 <d>рабочий</d> <d>день</d>.
Lange Ejemplo 2
El servicio puede pronunciar la traducción.
Ejemplo:
Lorem ipsum dolor sit amet.
Traducción Ejemplo 1
Usando SSML, puede controlar las pausas y el discurso sintetizado proxy.
<p>
Когда я просыпаюсь, <prosody rate="x-slow">я говорю довольно медленно</prosody>.
Потом я начинаю говорить своим обычным голосом,
<prosody pitch="x-high"> а могу говорить тоном выше </prosody>,
или <prosody pitch="x-low">наоборот, ниже</prosody>.
Потом, если повезет – <prosody rate="fast">я могу говорить и довольно быстро.</prosody>
А еще я умею делать паузы любой длины, например две секунды <break time="2000ms"/>.
<p>
Также я умею делать паузы между параграфами.
</p>
<p>
<s>И также я умею делать паузы между предложениями</s>
<s>Вот например как сейчас</s>
</p>
</p>
SSML Ejemplo 1
GET /clear_cache : limpia el caché de los mensajes ya sintetizados.GET /settings : devuelve la configuración del servidor actual.GET /voices : devuelve una lista de votos disponibles para el idioma seleccionado.GET /process?VOICE=[Выбраный голос]&INPUT_TEXT=[Текст для обработки] - Devuelve un archivo de audio de discurso sintetizado.POST /process en el cuerpo de VOICE=[Выбраный голос] , INPUT_TEXT=[Текст для обработки] - Devuelve un archivo de audio de discurso sintetizado. Editar client.conf
nano /etc/pulse/client.conf
Agregue lo siguiente:
default-server = unix:/usr/share/hassio/audio/external/pulse.sock
autospawn = no
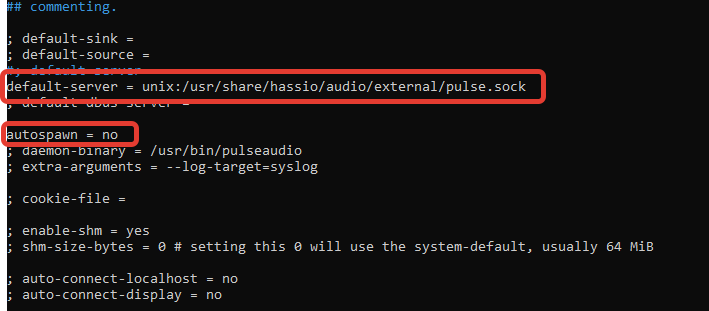
Reinicie PulseAudio.
pulseaudio -k && pulseaudio --start
Ponemos una versión adicional de la versión actual: 2.1.1 y solo ponemos esta versión. Mopidy 2.2.0 no se pone, está roto. Lea más sobre la versión rota de Mopidy 2.2.0 Leer aquí.
Agregar a Configuration.yaml
media_player :
- platform : mpd
name : " MPD Mopidy "
host : localhost
port : 6600Reiniciamos el asistente de casa por completo para reiniciar a Debian.
Conecte la columna Bluetooth a Debian, KB, J a través de GUI o a través de la consola utilizando el comando Bluetoothctl
Encienda Bluetooth:
power on
Iniciar dispositivos de escaneo:
scan on
Cuando vimos nuestro dispositivo, nos apareamos con el dispositivo:
pair [mac адрес девайса]
Nos conectamos al dispositivo:
connect [mac адрес девайса]
Agregue el dispositivo a confianza:
trust [mac адрес девайса]
Además, cómo los dispositivos Bluetooth agregaron dos complementos de Asistente de Raspy y Mopidy, debe especificar la fuente del sonido del dispositivo Bluetooth:
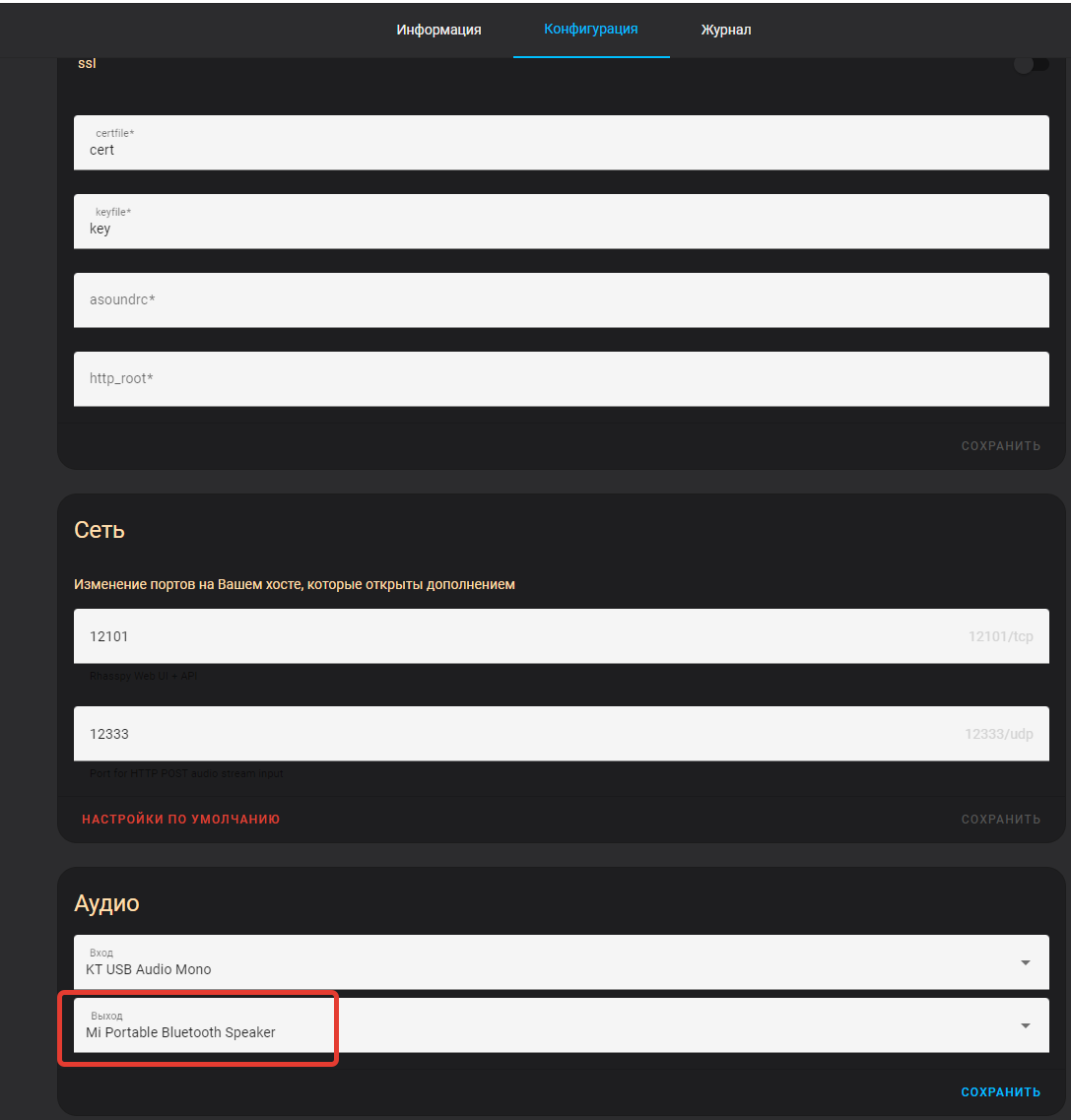
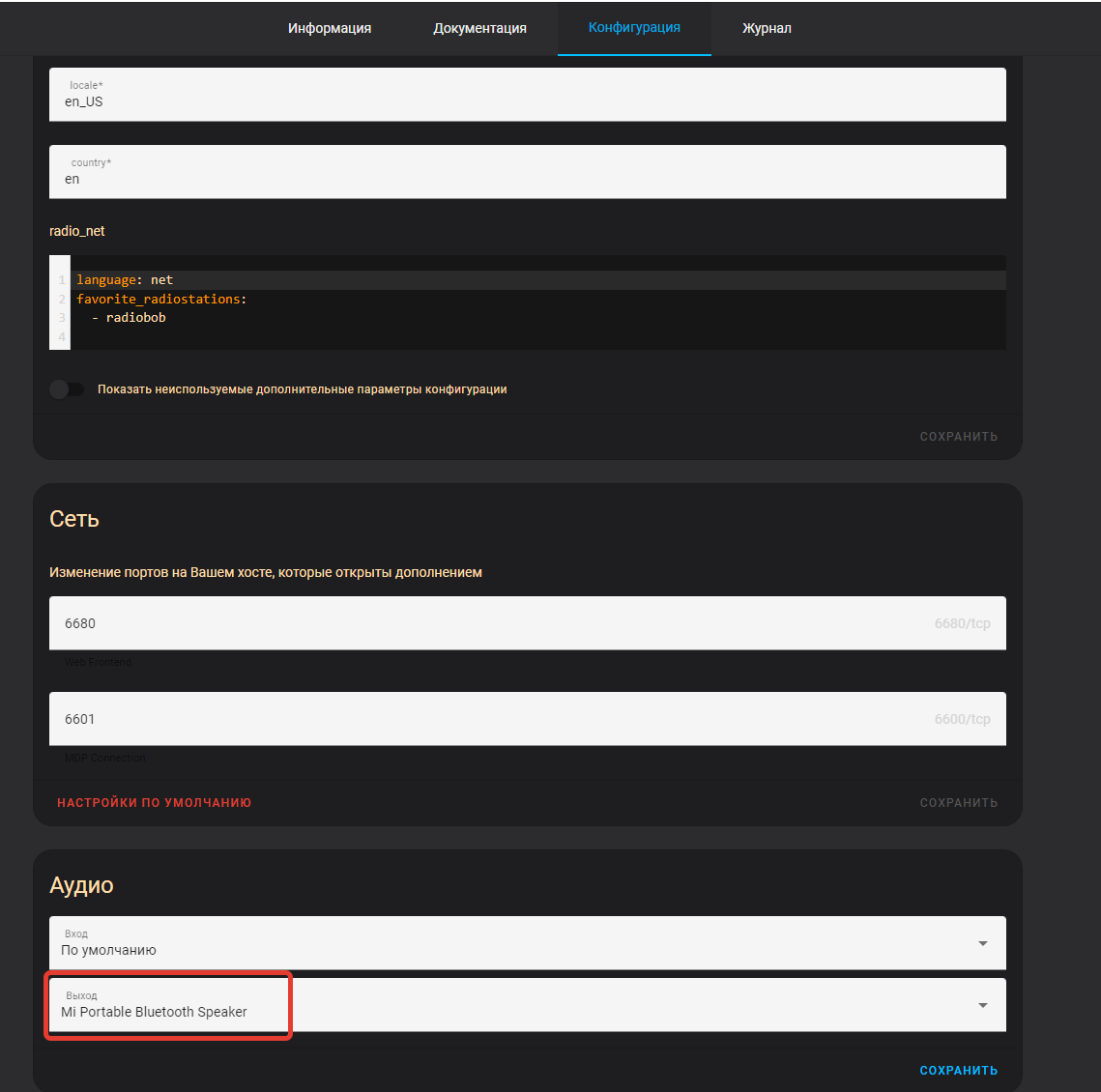
Revisamos el rendimiento:
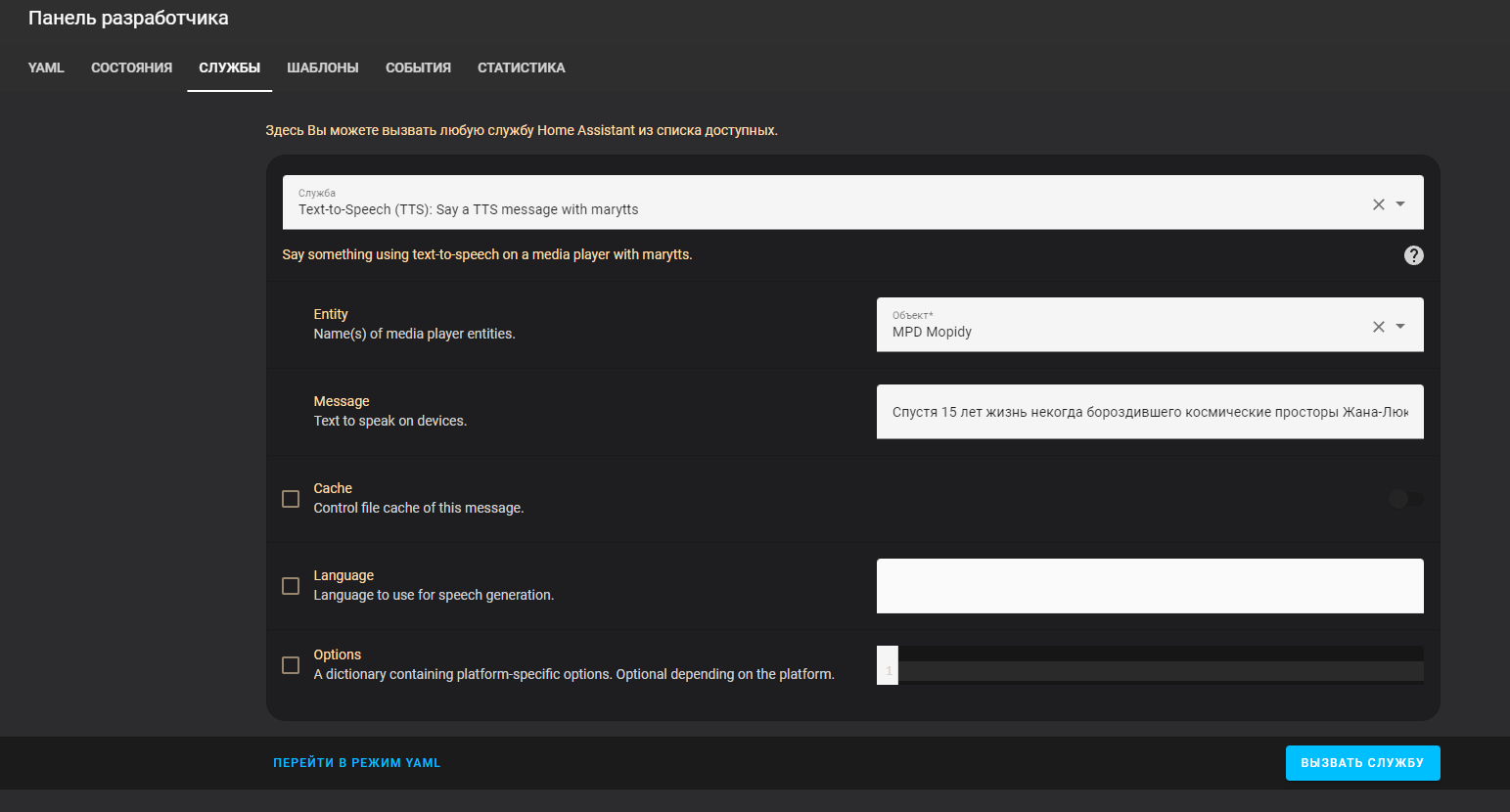
Código:
service : tts.marytts_say
data :
entity_id : media_player.mpd_mopidy
message : >-
Спустя 15 лет жизнь некогда бороздившего космические просторы Жана-Люка
Пикара

