fastVC
1.0.0
FastVC es una herramienta rápida y eficiente, no paralelo y de conversión de voz (VC) . VC implica la modificación de la voz de un altavoz de origen para que suene como el de un altavoz objetivo, sin cambiar el contenido lingüístico de la oración. Nuestra herramienta explota la tarea en cascada en cascada de un modelo de reconocimiento de voz automático (ASR) y un modelo de texto a discurso (TTS).
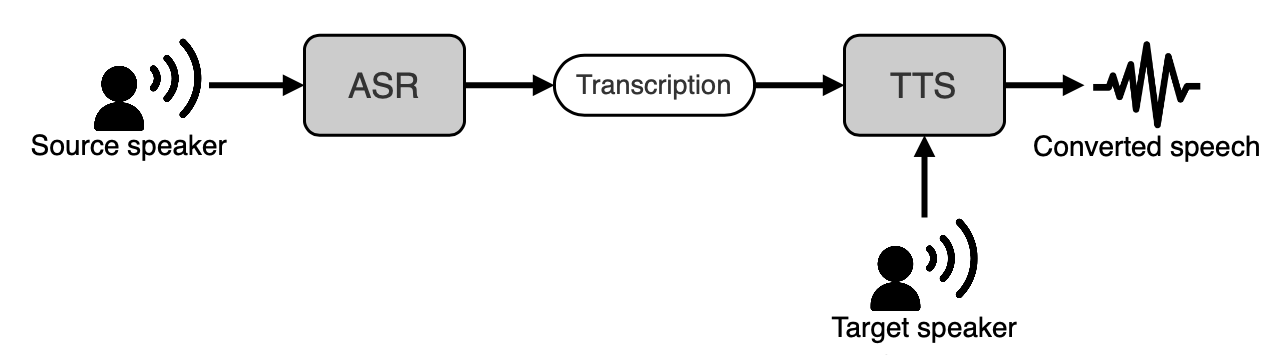
El ASR se basa en WAV2VEC 2.0 y se usa para transcribir el discurso de un orador de origen. El TTS se basa en SV2TTS y se utiliza para generar el discurso de salida a partir de una incrustación de altavoz objetivo.
Para obtener una explicación más detallada, consulte el documento de nuestro proyecto. Una página de demostración está disponible aquí.
El software se implementó utilizando python 3.9.4
git clone https://github.com/fmiotello/fastVC.git ) e ingrese el directorio ( cd fastVC )python -m venv env y source env/bin/activate (si usa macOS/Linux) o .envScriptsactivate (si usa Windows)python -m pip install --upgrade pippython -m pip install -r requirements.txt ./src/encoder/saved_models/pretrained.pt
./src/synthesizer/saved_models/pretrained/pretrained.pt
./src/vocoder/saved_models/pretrained/pretrained.pt
python src/main.py (use --help para mostrar las opciones disponibles). El audio de salida será ./src/audio/audio_out.wav .Se pueden encontrar más instrucciones aquí.
Esta aplicación se desarrolló como un proyecto en Politecnico di Milano (MSC en música e ingeniería acústica).
Luigi Atorresi
Federico miotello
Eugenio Poliuti


