fastVC
1.0.0
FastVC is a fast and efficient, non-parallel and any-to-any voice conversion (VC) tool. VC involves the modification of the voice of a source speaker to make it sound like that of a target speaker, without changing the linguistic content of the sentence. Our tool exploits the task by cascading an Automatic Speech Recognition (ASR) model and a Text To Speech (TTS) model.
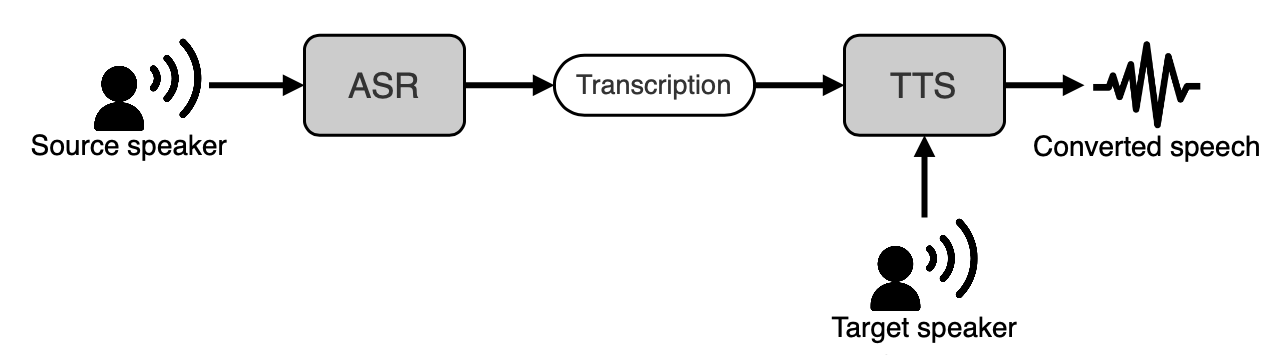
The ASR is based on Wav2vec 2.0 and is used to transcribe the speech from a source speaker. The TTS is based on SV2TTS and is used to generate the output speech from a target speaker embedding.
For a more detailed explanation check out the paper of our project. A demo page is available here.
The software was implemented using python 3.9.4
git clone https://github.com/fmiotello/fastVC.git) and enter the directory (cd fastVC)python -m venv env and source env/bin/activate (if using macOS/Linux) or .envScriptsactivate (if using Windows)python -m pip install --upgrade pippython -m pip install -r requirements.txt./src/encoder/saved_models/pretrained.pt
./src/synthesizer/saved_models/pretrained/pretrained.pt
./src/vocoder/saved_models/pretrained/pretrained.pt
python src/main.py (use --help for displaying available options). The output audio will be ./src/audio/audio_out.wav.More instructions can be found here.
This application was developed as a project at Politecnico di Milano (MSc in Music and Acoustic Engineering).
Luigi Attorresi
Federico Miotello
Eugenio Poliuti


