YOLOv5 Lite
v5-Lite-v1.5
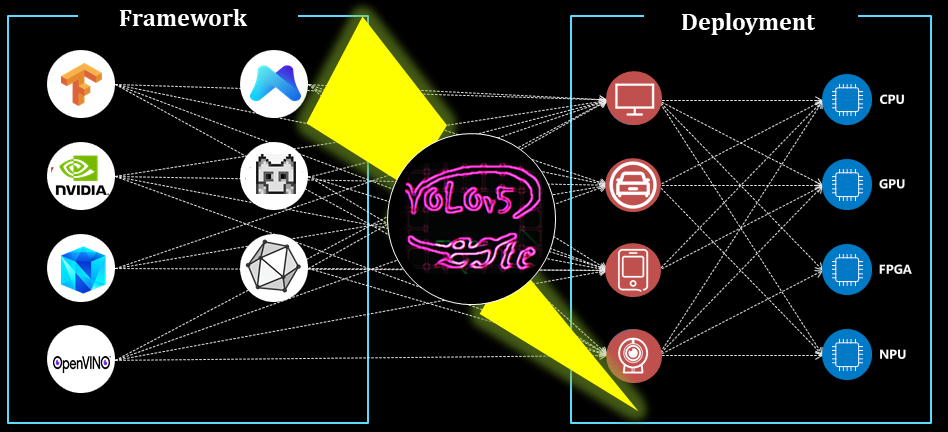
Perform a series of ablation experiments on yolov5 to make it lighter (smaller Flops, lower memory, and fewer parameters) and faster (add shuffle channel, yolov5 head for channel reduce. It can infer at least 10+ FPS On the Raspberry Pi 4B when input the frame with 320×320) and is easier to deploy (removing the Focus layer and four slice operations, reducing the model quantization accuracy to an rango aceptable).

| IDENTIFICACIÓN | Modelo | Input_size | Chocolas | Parámetros | Tamaño (m) | [email protected] | [email protected]: 0.95 |
|---|---|---|---|---|---|---|---|
| 001 | yolo más rápido | 320 × 320 | 0.25 g | 0.35m | 1.4 | 24.4 | - |
| 002 | Yolov5-lite e our | 320 × 320 | 0.73g | 0.78m | 1.7 | 35.1 | - |
| 003 | Nanodet-m | 320 × 320 | 0.72g | 0.95m | 1.8 | - | 20.6 |
| 004 | Yolo-Fastest-XL | 320 × 320 | 0.72g | 0,92 m | 3.5 | 34.3 | - |
| 005 | Yolox nano | 416 × 416 | 1.08g | 0.91m | 7.3 (FP32) | - | 25.8 |
| 006 | yolov3 diminuto | 416 × 416 | 6.96g | 6.06m | 23.0 | 33.1 | 16.6 |
| 007 | yolov4 | 416 × 416 | 5.62g | 8.86m | 33.7 | 40.2 | 21.7 |
| 008 | Yolov5-lite s nuestro | 416 × 416 | 1.66g | 1.64m | 3.4 | 42.0 | 25.2 |
| 009 | Yolov5-lite c our | 512 × 512 | 5.92g | 4.57m | 9.2 | 50.9 | 32.5 |
| 010 | Nanodet-eficienteLite2 | 512 × 512 | 7.12g | 4.71m | 18.3 | - | 32.6 |
| 011 | Yolov5s (6.0) | 640 × 640 | 16.5G | 7.23m | 14.0 | 56.0 | 37.2 |
| 012 | Yolov5-lite g our | 640 × 640 | 15.6g | 5.39m | 10.9 | 57.6 | 39.1 |
Vea el wiki: https://github.com/ppogg/yolov5-lite/wiki/test-the-map-of-models-upout-coco
| Equipo | Backend informático | Sistema | Aporte | Estructura | v5lite-e | v5lite-s | v5lite-c | v5lite-G | Yolov5s |
|---|---|---|---|---|---|---|---|---|---|
| Enterrar | @i5-10210u | Ventana (x86) | 640 × 640 | abierto | - | - | 46 ms | - | 131 ms |
| Nvidia | @RTX 2080ti | Linux (x86) | 640 × 640 | antorcha | - | - | - | 15 ms | 14 ms |
| Redmi K30 | @Snapdragon 730g | Android (ARMV8) | 320 × 320 | ncnn | 27 ms | 38 ms | - | - | 163 ms |
| Xiaomi 10 | @Snapdragon 865 | Android (ARMV8) | 320 × 320 | ncnn | 10 ms | 14 ms | - | - | 163 ms |
| Fraspberrypi 4B | @Arm Cortex-A72 | Linux (ARM64) | 320 × 320 | ncnn | - | 84 ms | - | - | 371 ms |
| Fraspberrypi 4B | @Arm Cortex-A72 | Linux (ARM64) | 320 × 320 | MNN | - | 71 ms | - | - | 356 ms |
| Axera-pi | Cortex A7@CPU 3.6tops @npu | Linux (ARM64) | 640 × 640 | axpi | - | - | - | 22 ms | 22 ms |
https://zhuanlan.zhihu.com/p/672633849
入群答案: 剪枝 o 蒸馏 o 量化 o 低秩分解(任意其一均可)
| Modelo | Tamaño | Columna vertebral | Cabeza | Estructura | Diseñar para |
|---|---|---|---|---|---|
| v5lite-e.pt | 1.7m | shufflenetv2 (megvii) | v5litee-cabeza | Pytorch | C-CPU |
| v5lite-e.bin v5lite-e.param | 1.7m | shufflenetv2 | v5litee-cabeza | ncnn | C-CPU |
| v5lite-e-int8.bin v5lite-e-int8.param | 0.9m | shufflenetv2 | v5litee-cabeza | ncnn | C-CPU |
| v5lite-e-fp32.mnn | 3.0m | shufflenetv2 | v5litee-cabeza | MNN | C-CPU |
| v5lite-e-fp32.tnnmodel v5lite-e-fp32.tnnproto | 2.9m | shufflenetv2 | v5litee-cabeza | tnn | C-CPU |
| v5lite-e-320.onnx | 3.1m | shufflenetv2 | v5litee-cabeza | onnxruntime | x86-cpu |
| Modelo | Tamaño | Columna vertebral | Cabeza | Estructura | Diseñar para |
|---|---|---|---|---|---|
| v5lite-s.pt | 3.4m | shufflenetv2 (megvii) | v5lites-cabeza | Pytorch | C-CPU |
| v5lite-s.bin v5lite-s.param | 3.3m | shufflenetv2 | v5lites-cabeza | ncnn | C-CPU |
| v5lite-s-int8.bin V5LITE-S-INT8.PARAM | 1.7m | shufflenetv2 | v5lites-cabeza | ncnn | C-CPU |
| v5lite-s.mnn | 3.3m | shufflenetv2 | v5lites-cabeza | MNN | C-CPU |
| v5lite-s-int4.mnn | 987k | shufflenetv2 | v5lites-cabeza | MNN | C-CPU |
| V5LITE-S-FP16.BIN v5lite-s-fp16.xml | 3.4m | shufflenetv2 | v5lites-cabeza | OpenVivo | x86-cpu |
| V5LITE-S-FP32.Bin V5LITE-S-FP32.XML | 6.8m | shufflenetv2 | v5lites-cabeza | OpenVivo | x86-cpu |
| V5LITE-S-FP16.TFLITE | 3.3m | shufflenetv2 | v5lites-cabeza | tflita | C-CPU |
| V5LITE-S-FP32.TFLITE | 6.7m | shufflenetv2 | v5lites-cabeza | tflita | C-CPU |
| v5lite-s-int8.tflite | 1.8m | shufflenetv2 | v5lites-cabeza | tflita | C-CPU |
| v5lite-s-416.onnx | 6.4m | shufflenetv2 | v5lites-cabeza | onnxruntime | x86-cpu |
| Modelo | Tamaño | Columna vertebral | Cabeza | Estructura | Diseñar para |
|---|---|---|---|---|---|
| v5lite-c.pt | 9m | PPLCNET (Baidu) | V5s-Head | Pytorch | x86-cpu / x86-vpu |
| v5lite-c.bin v5lite-c.xml | 8.7m | Pplcnet | V5s-Head | OpenVivo | x86-cpu / x86-vpu |
| v5lite-c-512.onnx | 18m | Pplcnet | V5s-Head | onnxruntime | x86-cpu |
| Modelo | Tamaño | Columna vertebral | Cabeza | Estructura | Diseñar para |
|---|---|---|---|---|---|
| v5lite-g.pt | 10.9m | Repvgg (tsinghua) | v5liteg-head | Pytorch | X86-GPU / ARM-GPU / ARM-NPU |
| V5LITE-G-INT8.EDGINO | 8.5m | Repvgg-yolov5 | v5liteg-head | Tensor | X86-GPU / ARM-GPU / ARM-NPU |
| V5LITE-G-INT8.TMFILE | 8.7m | Repvgg-yolov5 | v5liteg-head | Moneda | NPU |
| v5lite-g-640.onnx | 21m | Repvgg-yolov5 | yolov5-cabeza | onnxruntime | x86-cpu |
| V5LITE-G-640. JUNTO | 7.1m | Repvgg-yolov5 | yolov5-cabeza | axpi | NPU |
v5lite-e.pt: | Baidu Drive | Google Drive || ─────
ncnn-fp16: | Baidu Drive | Google Drive |
| ─────sencnn-int8: | Baidu Drive | Google Drive |
| ─────mnn-e_bf16: | Google Drive |
| ─────mnn-d_bf16: | Google Drive |
onnx-fp32Baidu Drive | Google Drive |
v5lite-s.pt: | Baidu Drive | Google Drive || ─────
ncnn-fp16: | Baidu Drive | Google Drive |
| ─────sencnn-int8: | Baidu Drive | Google Drive |
tengine-fp32Baidu Drive | Google Drive |
v5lite-c.pt: Baidu Drive | Google Drive |
openvino-fp16Baidu Drive | Google Drive |
v5lite-g.pt: | Baidu Drive | Google Drive |
axpi-int8
Contraseña de unidad de Baidu: pogg
https://github.com/pinto0309/pinto_model_zoo/tree/main/180_yolov5-lite
Python> = 3.6.0 es necesario con todos los requisitos.txt instalado incluyendo pytorch> = 1.7 :
$ git clone https://github.com/ppogg/YOLOv5-Lite
$ cd YOLOv5-Lite
$ pip install -r requirements.txt detect.py ejecuta inferencia en una variedad de fuentes, descargando modelos automáticamente de la última versión Yolov5-Lite y guardando resultados para runs/detect .
$ python detect.py --source 0 # webcam
file.jpg # image
file.mp4 # video
path/ # directory
path/ * .jpg # glob
' https://youtu.be/NUsoVlDFqZg ' # YouTube
' rtsp://example.com/media.mp4 ' # RTSP, RTMP, HTTP stream$ python train.py --data coco.yaml --cfg v5lite-e.yaml --weights v5lite-e.pt --batch-size 128
v5lite-s.yaml v5lite-s.pt 128
v5lite-c.yaml v5lite-c.pt 96
v5lite-g.yaml v5lite-g.pt 64Si usa multi-GPU. Es más rápido varias veces:
$ python -m torch.distributed.launch --nproc_per_node 2 train.pyConjunto de entrenamiento y distribución del conjunto de pruebas (la ruta con xx.jpg)
train: ../coco/images/train2017/
val: ../coco/images/val2017/├── images # xx.jpg example
│ ├── train2017
│ │ ├── 000001.jpg
│ │ ├── 000002.jpg
│ │ └── 000003.jpg
│ └── val2017
│ ├── 100001.jpg
│ ├── 100002.jpg
│ └── 100003.jpg
└── labels # xx.txt example
├── train2017
│ ├── 000001.txt
│ ├── 000002.txt
│ └── 000003.txt
└── val2017
├── 100001.txt
├── 100002.txt
└── 100003.txtEnlace : https: //github.com/ppogg/autolabelimg
Puede usar Yolov5-5.0 y Yolov5-Lite basado en LabelImg para autoannotar, Biubiubiu 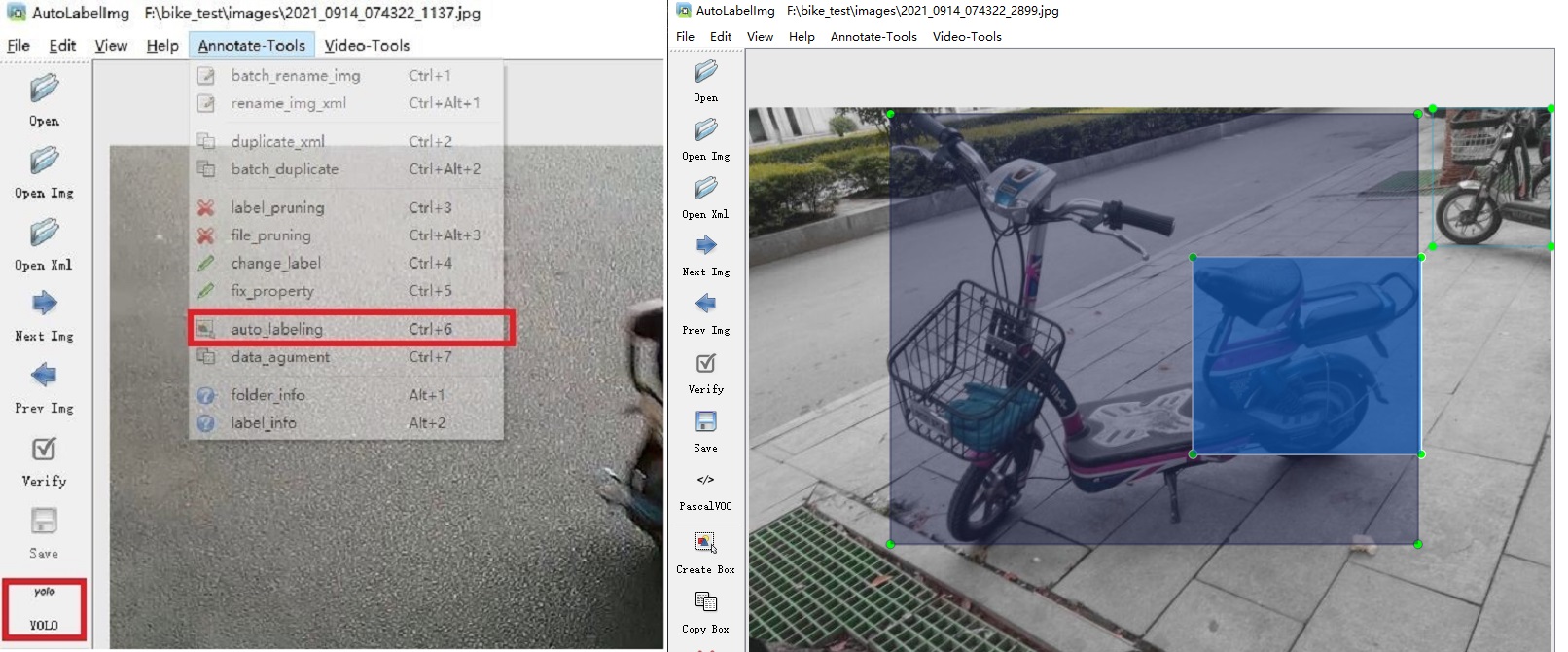
Aquí, los componentes originales de Yolov5 y los componentes reproducidos de Yolov5-Lite se organizan y almacenan en el Model Hub:
$ python main.py --type all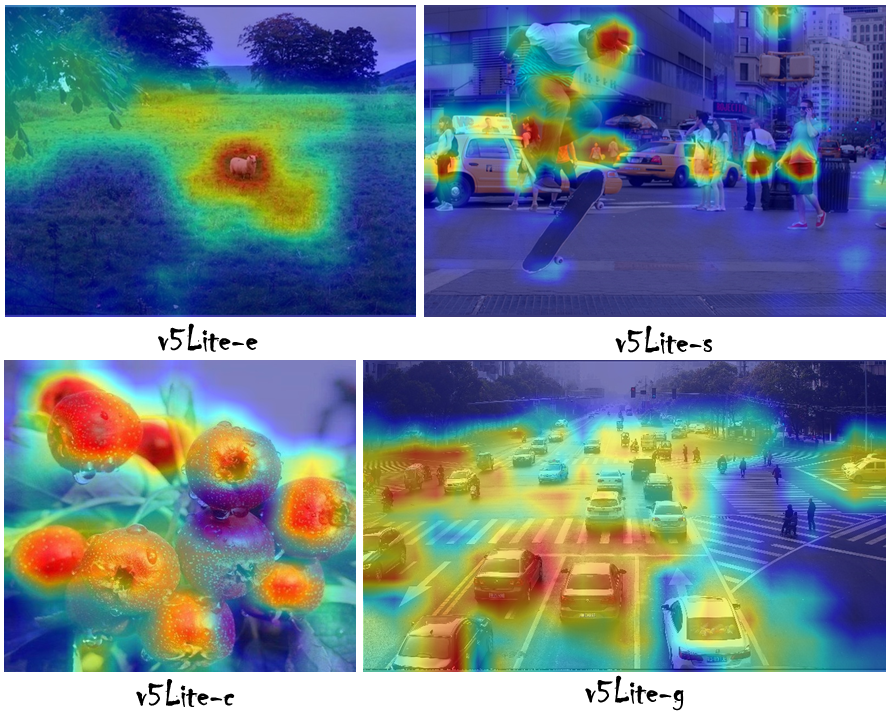
Actualización ...
NCNN para ARM-CPU
MNN para ARM-CPU
OpenVino x86-cpu o x86-vpu
Tensorrt (C ++) para ARM-GPU o ARM-NPU o X86-GPU
Tensorrt (Python) para ARM-GPU o ARM-NPU o X86-GPU
Android para ARM-CPU
Este es un teléfono Redmi, el procesador es Snapdragon 730g y Yolov5-Lite se usa para la detección. La actuación es la siguiente:
Enlace: https://github.com/ppogg/yolov5-lite/tree/master/android_demo/ncnnnroid-v5lite
Android_v5lite-s: https://drive.google.com/file/d/1ctohy68n2b9xyuqflitp-nd2kufwgaur/view?usp=sharing
Android_v5lite-g: https://drive.google.com/file/d/1fnvkwxxp_azwhi000xjiuhj_ohqoujcj/view?usp=sharing
Nueva aplicación de Android: [enlace] https://pan.baidu.com/s/1prhw4fi1jq8vbopyishciq [palabra clave] pogg

¿Qué es el modelo Yolov5-Lite S/E: Zhihu Link (chino): https://zhuanlan.zhihu.com/p/400545131
¿Qué es Yolov5-Lite C Modelo: Zhihu Link (chino): https://zhuanlan.zhihu.com/p/420737659
¿Qué es Yolov5-Lite G Modelo: Link Zhihu (chino): https://zhuanlan.zhihu.com/p/410874403
Cómo implementar en NCNN con FP16 o Int8: CSDN Link (chino): https://blog.csdn.net/weixin_45829462/article/details/119787840
Cómo desplegarse en MNN con FP16 o Int8: Link Zhihu (chino): https://zhuanlan.zhihu.com/p/672633849
Cómo implementar en Onnxruntime: Link Zhihu (chino): https://zhuanlan.zhihu.com/p/476533259(old versión)
Cómo implementar en Tensorrt: Link Zhihu (chino): https://zhuanlan.zhihu.com/p/478630138
Cómo optimizar en Tensorrt: Link Zhihu (chino): https://zhuanlan.zhihu.com/p/463074494
https://github.com/ultralytics/yolov5
https://github.com/megvii-model/shufflenet-series
https://github.com/tencent/ncnn
Si usa yolov5-lite en su investigación, cite nuestro trabajo y le dé una estrella:
@misc{yolov5lite2021,
title = {YOLOv5-Lite: Lighter, faster and easier to deploy},
author = {Xiangrong Chen and Ziman Gong},
doi = {10.5281/zenodo.5241425}
year={2021}
}


