browser fingerprinting
1.0.0
El desarrollo de este repositorio no hubiera sido posible sin el apoyo de muchos socios y patrocinadores. Uno de estos socios es SrapingBee, que es un servicio de raspado web en la nube con algunas características de detección anti-bots incorporadas.
SCRAPINGBEE: regístrese para una prueba gratuita y obtenga -10% en la primera factura con el código "niespodd"
Ya sea que esté comenzando a construir un raspador web desde cero y preguntándose qué está haciendo mal porque su solución no funciona, o ya ha estado trabajando con rastreadores durante un tiempo y está atrapado en una página que le da un error diciendo que es un bot, no puede ir más allá, sigue leyendo.
Las soluciones antimotas han evolucionado en los últimos años. Cada vez más sitios web introducen medidas de seguridad: desde simples, como filtrar direcciones IP de acuerdo con su geolocalización, hasta las avanzadas basadas en el análisis en profundidad de los parámetros del navegador y el análisis de comportamiento. Todo esto hace que el contenido de raspado web sea más difícil y costoso que hace unos años. Sin embargo, todavía es posible. Aquí destaco algunos consejos que puede encontrar útiles.
A continuación puede encontrar una lista de servicios curados que usé para obtener diferentes protecciones contra el botón. Dependiendo de su caso de uso, es posible que necesite uno de los siguientes:
| Escenario/caso de uso | Solución | Ejemplo |
|---|---|---|
| Sesiones de corta duración sin autores | Conjunto de direcciones IP giratorias | Eso es útil cuando raspa sitios web como Amazon, Walmart o Public LinkedIn Pages. Ese es cualquier sitio web donde no se requiere inicio de sesión. Planea hacer una gran cantidad de sesiones de corta duración y puede permitirse ser bloqueado de vez en cuando. |
| Sitios web geográficamente restringidos | Conjunto de direcciones IP específicas de la región | Esto es útil cuando el sitio web usa un firewall similar al de CloudFlare para bloquear la geografía completa para acceder a ella. |
| Sesiones de larga vida después del inicio de sesión | Conjunto repetible de direcciones IP y un conjunto estable de huellas digitales del navegador | El escenario más común aquí es la automatización de las redes sociales, por ejemplo, crea una herramienta para automatizar las cuentas de redes sociales para administrar anuncios de manera más eficiente. |
| Detección basada en JavaScript | Uso de bibliotecas de evasión populares, similar a titiritero-extratraal | Hay varios sitios web que utilizan huellas dactilares que se pueden pasar fácilmente cuando emplea complementos de código abierto, como el complemento de titiros de titiriteros antes mencionado para trabajar con su software existente. |
| Detección con técnicas de huellas digitales del navegador | Huellas digitales del navegador de aspecto natural. Es decir, haber cubierto toda la superficie que está siendo validada por la solución JavaScript instalada en el sitio web de destino. | Estos son uno de los casos más avanzados. Los ejemplos convencionales son procesadores de tarjetas de crédito como Adyen o Stripe. Se está creando una huella digital de navegador muy sofisticada para detectar fraude crediticio o provocar autorización adicional del usuario. |
| Conjunto único de técnicas de detección | Software BOT especializado que se dirige a la superficie de detección única del sitio web objetivo. | Los buenos ejemplos son los sitios web de zapatillas de deporte y las tiendas de comercio electrónico, según los informes, bajo un fuerte ataque del software BOT personalizado. |
| Técnicas de detección de fabricación personalizada simples | Antes de sumergirse en cualquiera de los anteriores, si está apuntando a un sitio web más pequeño, es muy probable que todo lo que necesita es un guión de Scrapy con ajustes, un proxy barato de centros de datos, y está listo. | - |
Una vez que haya decidido qué tipo de evasión se necesitará en su proyecto, puede usar la lista a continuación para elegir el mejor proveedor para su proyecto:
| Tipo | Servicio | Nota |
|---|---|---|
| Apoderado | El poder social  | Altamente recomendado? ✔️ Pros : Los Pools IP son consistentemente buenos, al contrario de los "grandes tiburones" existentes de la industria proxy que cobran por GB, aquí obtienes tráfico ilimitado dentro de un punto final rotativo. Modelo de negocio transparente. Contras: La cobertura GEO se limita a los países que figuran en el sitio web. La IP no se gira al instante, pero prefiere esperar de 10 a 15 segundos. |
BrightData (anteriormente Luminati Networks) | Uno de los proveedores proxy más populares, pero probablemente también más caros. El grupo IP se obtiene principalmente de los usuarios de Holavpn y un SDK de monetización de aplicaciones. | |
Oxilabs | Competidor de Data Bright con más productos de raspado sin código/código bajo. | |
| Raspando como servicio | Rasguño | Altamente recomendado? Uno de los raspados sigilosos más avanzados como servicio. A veces puede ser más barato que construir una solución de raspado dedicada: no cobran por la cantidad de tráfico utilizado. |
Apify.com | Apify se ha convertido en una plataforma SaaS de rasguño y automatización completa, con herramientas preparadas, un proxy integrado y soluciones personalizadas para raspar a cualquier escala. Los desarrolladores también pueden crear raspadores en la plataforma y alquilarlos a otros usuarios. | |
| De-Captcha como servicio | Anti Captcha: servicio de resolución de captcha. Bypass recaptcha, funcaptcha (...) | Explicado por sí mismo. Bitcoin aceptado ❤️. |
Esta es una lista no exhaustiva de empresas que proporcionan las soluciones anti-bots más avanzadas para empresas que van desde sitios de comercio electrónico más pequeños hasta compañías Fortune 500:
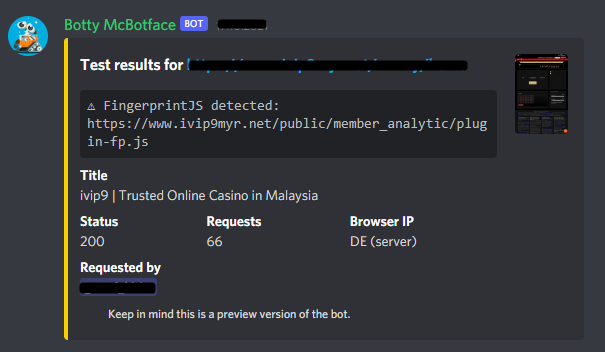
Únete a la comunidad extra. Se ejecuta un probador automatizado Botty McBotface que utiliza varias técnicas complicadas para determinar qué protección exacta utiliza un sitio web probado (créditos para Berstend y otros de #Insiders).
Importante que use este software bajo su propio riesgo. Algunos de ellos contienen malwares solo para su información. No recomiendo usarlos.
| Navegador sigiloso | Titiritero | Selenio | Evasiones | SDK/herramientas | Origen |
|---|---|---|---|---|---|
| Gologin | ✔️ | ✔️ | ? | ? | ? + ??? |
| Incognitón | ✔️ | ✔️ | ? | ✔️ | ? ❓ |
| Clonbrowser | ✔️ | ✔️ | ? | ✔️ | ? |
| Multilogina | ✔️ | ✔️ | ? | ✔️ | ? + ??? |
| Navegador índigo | ✔️ | ✔️ | ? | ✔️ | ? |
| Fantasma | ? | ? | |||
| Kameleo | ✔️ | ✔️ | ? | ✔️ | ? |
| Antbrowser | ? | ||||
| Chebrowser | ?/✔️ | ? | ? |
Leyenda: ? - Evasión basada en el ruido. - No. ✔️ - aceptable (con bibliotecas de soporte o no). ? - Muy lindo.
¡A en este repositorio será apreciado !
Aquí estudio varios aspectos de las técnicas de evasión utilizadas para sortear los sistemas de detección de botes utilizados por los principales sitios web en línea. Cubro asuntos técnicos y no técnicos, incluidas recomendaciones, referencias a artículos científicos y más.
Los hallazgos técnicos que comparto a continuación se basan en las observaciones de ejecutar scripts de raspado web durante unos meses contra sitios web protegidos por los principales proveedores de soluciones antimotas.
Constantemente agrego cosas a esta sección. Con el tiempo, intentaré que se vea y se sienta más estructurado.
✔️ Win / Fail /? Atar :
navigator y windowUser-Agent ). Hay una explicación detallada del problema. La evasión más confiable parece no estar falsificando en absoluto el sistema operativo Host, o el uso de OSFooler-NG.window.outerdimensions . Casi siempre falla cuando viewport size >= screen resolution (pantalla de resolución de pantalla baja en el host).ServiceWorker / WebWorker a través de Existng Puppeteer API.navigator y window : según la documentación multilogina, el navegador personalizado se construye típicamente detrás de las últimas adiciones agregadas por los proveedores del navegador. En este caso, se usa el cromo M7X modificado (casi 10 versiones detrás al escribir esto).puppeteer-extra-plugin-stealth como ML y Kameleo, proporcionan como máximo una anulación para complementos y extensiones nativas enviadas con Google Chrome.TBD (si tiene una suscripción activa en cualquiera de estos servicios y no le importa compartir una cuenta, envíeme un correo electrónico ❤️)
Estos sitios web pueden ser útiles para probar técnicas de huellas dactilares contra un software de raspado web
| Página de prueba | Notas |
|---|---|
| https://bot.incolumitas.com/ | Colección de pruebas muy útil y útil |
| https://plaperdr.github.io/morellian-canvas/prototype/webpage/picassauth.html | lienzo huellas dactilares con esteroides |
| https://pixelscan.net/ | No es 100% realable, ya que a menudo se muestra "inconsistente" a Chrome después de una nueva actualización, pero vale la pena verificar ya que el autor agrega nuevas funciones de detección interesantes de vez en cuando |
| https://browserleaks.com/ | No necesita introducción |
| https://f.vision/ | Página de prueba de buena calidad de algunos ?? tipo |
| https://www.ipqualityscore.com/ip-reputation-check | Servicio comercial con cheque de reputación gratuito contra listas negras populares |
| https://antcpt.com/eng/information/demo-form/recaptcha-3-test-score.html | RECAPTCHA SCORE, así como algunas notas interesantes sobre cómo optimizar los costos de resolución de Captcha |
| https://ja3er.com/ | Huella digital SSL/TLS |
| https://fingerprintjs.com/demo/ | Bueno para pruebas básicas: de las personas que creen y afirman que pueden crear huellas digitales únicas "99.5%" del tiempo |
| https://coveryourtracks.eff.org/ | - |
| https://www.deviceinfo.me/ | - |
| https://amiunique.org/ | - |
| http://uniquemachine.org/ | - |
| http://dnscookie.com/ | - |
| https://whatleaks.com/ | - |
| https://antcpt.com/eng/information/demo-form/recaptcha-3-test-score.html | Revise su puntaje de recaptcha |
| https://antoinevastel.com/bots/ | - |
| https://antoinevastel.com/bots/datadome | - |
| https://iphey.com/ | - |
| https://bot.sannysoft.com/ | - |
| https://webbrowsertools.com/canvas-ingprint/ | - |
| https://webbrowsertools.com/webgl-fingerprint/ | - |
| https://fingerprint.com/products/bot-detection/ | - |
| https://abrahamjuliot.github.io/creepjs/ | Realmente espeluznante, el más fuerte de todos |
Necesito hacer un comentario general a las personas que están evaluando (y/o) planeando introducir software anti-bots en sus sitios web. El software anti-bot no tiene sentido. Su aceite de serpiente se vendió a personas sin conocimiento técnico por mucho dinero.
El bloqueo del tráfico BOT se basa en la premisa de que usted (o su proveedor de tecnología) puede distinguir los bots de los usuarios reales . Para que esto suceda, se aplican varias técnicas invasivas de privacidad. Hasta la fecha, se ha demostrado que ninguno de ellos tiene éxito contra herramientas especializadas de raspado web. El software anti-Bot se trata de reducir el tráfico BOT barato. Hace que el proceso de rasparse sea más costoso y complicado, pero no lo hace completamente imposible .
Los proveedores de software anti-bots utilizan técnicas de detección que se dividen en una de estas dos categorías:
No se utiliza un software de raspado web especializado. El proveedor puede detectar el mal tráfico basado en la información revelada abiertamente por el encabezado User-Agent de raspador, parámetros de conexión, etc.
Como resultado , solo los bots que no están dirigidos a raspar el sitio web específico están bloqueados . Esto hará felices a la mayoría de los gerentes, porque el número total de malos tráfico disminuye y puede parecer que no hay más tráfico de bot en el sitio web. Equivocado.
Los raspadores web más avanzados utilizan proxies residenciales e implementan técnicas de evasión compleja para engañar al software contra el botón para pensar que el raspador web es un usuario real. No existe un mecanismo de detección para evitar esto debido a la limitación técnica de los navegadores web.
En este caso, la mayoría de las veces el proveedor solo podrá agrupar el mal tráfico al encontrar patrones en el tráfico y el comportamiento de Bot. Aquí es donde entra en juego las huellas digitales del navegador. El problema de prohibir el tráfico aquí es que puede ser una operación arriesgada cuando los bots imitan con éxito a los usuarios reales. Existe la posibilidad de que al bloquear los bots, el sitio web no esté disponible para los visitantes reales .
Si crees que esta es una forma de ir a Google "Captcha Resolve API".
Si tiene problemas para raspar el sitio web específico, escríbeme un breve correo electrónico a [email protected] . ¿Tengamos una consulta rápida de Tête-à-Tête a través de Skype?
¿He mencionado que A sería apreciado? :-)
➡️ Ethereum Dirección 0x380a4b41fB5e0e1EB8c616eBD56f62f8F934Bab6


