fmfm filemanager
1.0.0
Un administrador/espectador de documentos basado en la web sobre Flask+Python. Actualmente se admiten PDF, el archivo zip (de imágenes), Markdown y los documentos EPUB.
Esto todavía está en la etapa beta y el código no es seguro. No use esto en servidores públicos.
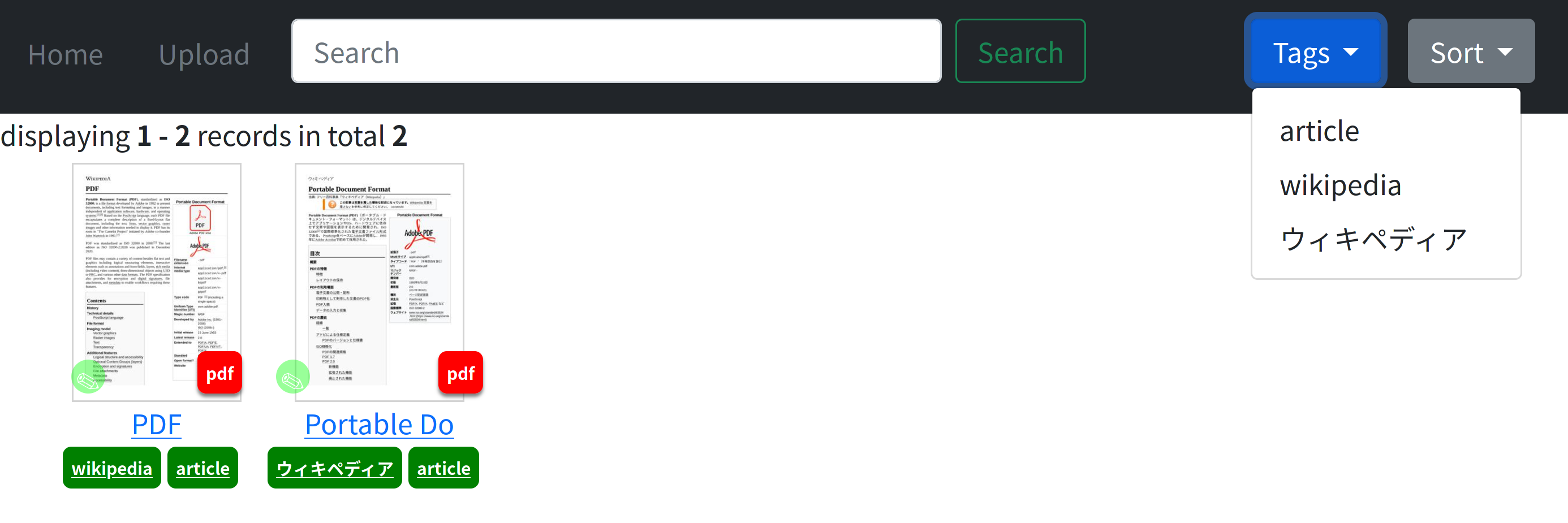
Haga clic en la miniatura abre el espectador. La insignia de "PDF" inferior derecha salta al archivo original. Se admiten etiquetado y búsqueda de documentos.
Se incluye un pequeño visor de documentos basado en HTML. Capacidades:
S )
La lectura de Epub está impulsada por BIBI. (¡Este es un software fantástico!)
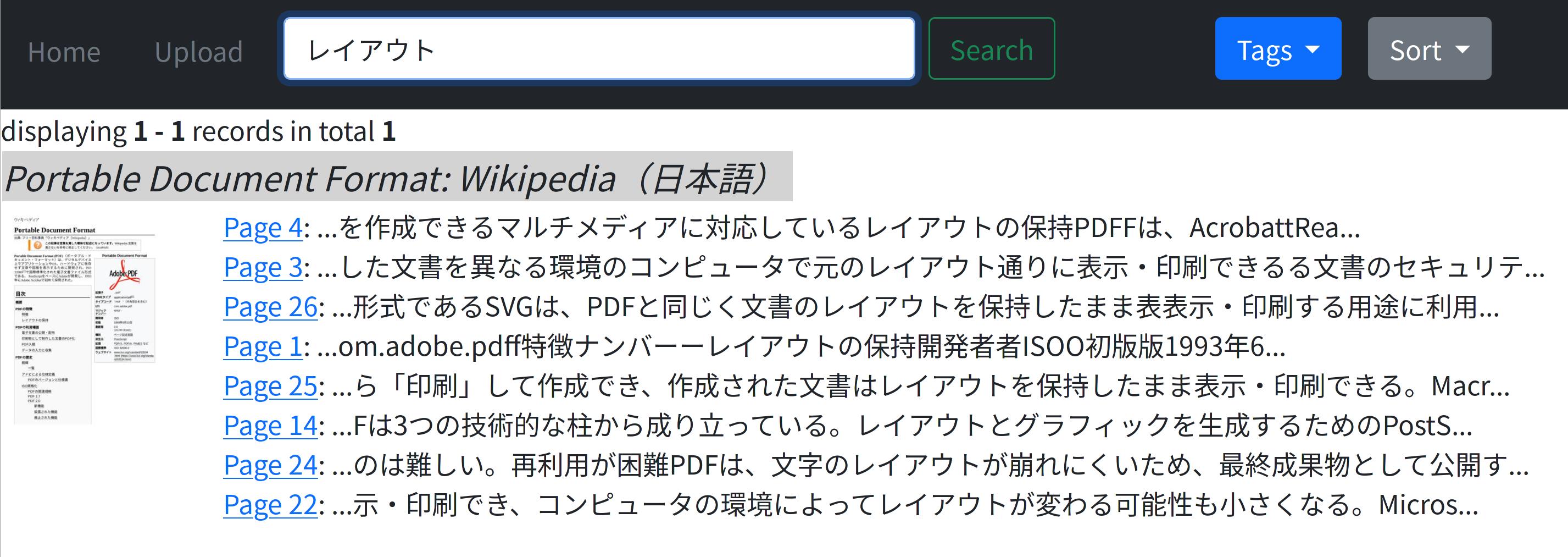
Búsqueda de texto completo (PDF, EPUB y Markdown)

日本語も検索可能です Se admite la búsqueda japonesa. (Tokenizer: 2 gramos)
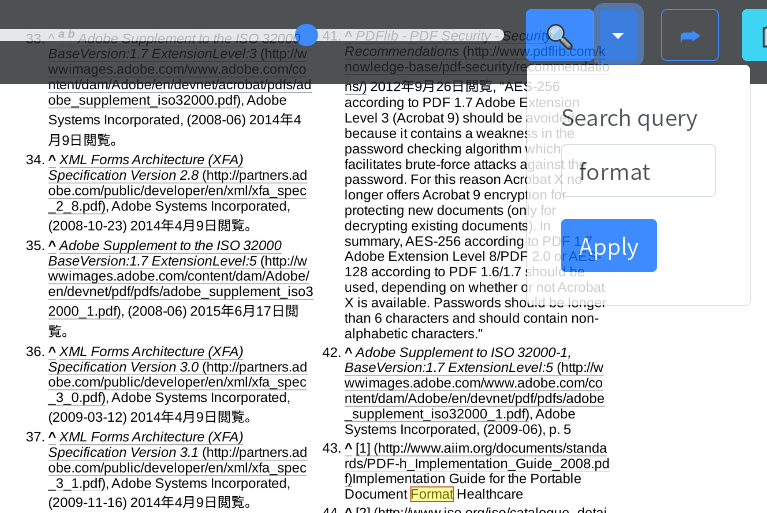
(Solo PDF) Los golpes de búsqueda están altos en la vista de página; También es posible la búsqueda en la página. (Atajo: F Key)
r2l : el documento es de derecha a izquierda (PDF y ZIP)spread : el documento se muestra en la vista de propagación (PDF y ZIP)hide : oculta el documento; Funciona, pero actualmente el archivo encontrado por búsqueda . 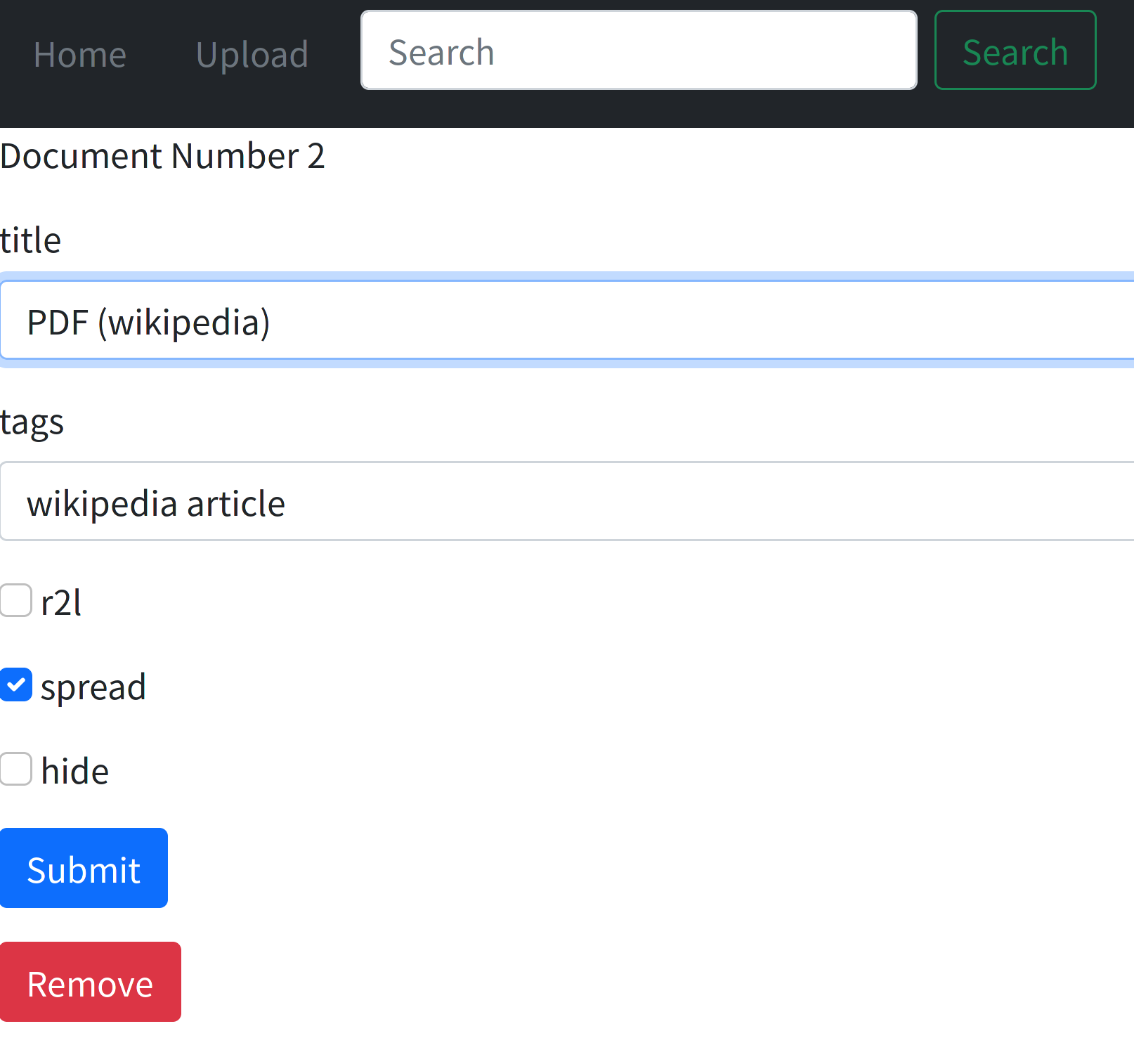
fmfm_util.py ).fmfm_util.py import ... para importar todos los archivos desde la carpeta de inbox .fmfm_util.py remove 1 2 3 ... para eliminar los libros especificados de DB.fmfm_util.py update 1 2 3 ... para actualizar los metadatos en el DB.fmfm_util.py update_title 1 2 3 ... para actualizar los metadatos, y el título se reemplaza por los metadatos del archivo. git clone Este repositorio y cd en la carpetaSECRET_KEY a algo aleatorio en settings.pyBibi-v1.2.0.zip de las versiones de BIBI, desempaquete el archivo y mueva la carpeta Bibi-v1.2.0 en la carpeta static .docker-compose up -dhttp://localhost:8888 por un navegador web.docker container stop fmfm-filemanager-python3-1 .pip install -r requirements.txt (también necesita el paquete cmake y poppler-cpp en una distribución)python server.py o bash run_fmfm_local.shhttp://localhost:5000/ (ex) o http://localhost:8888/ (segundo) por un navegador web. static de paso de Nginx mejora el rendimiento. Ver nginx_conf.sample por ejemplo. 

