Awesome Chinese NLP
1.0.0
Una lista curada de recursos para PNL (procesamiento del lenguaje natural) para chinos
Información relacionada con el procesamiento del lenguaje natural chino
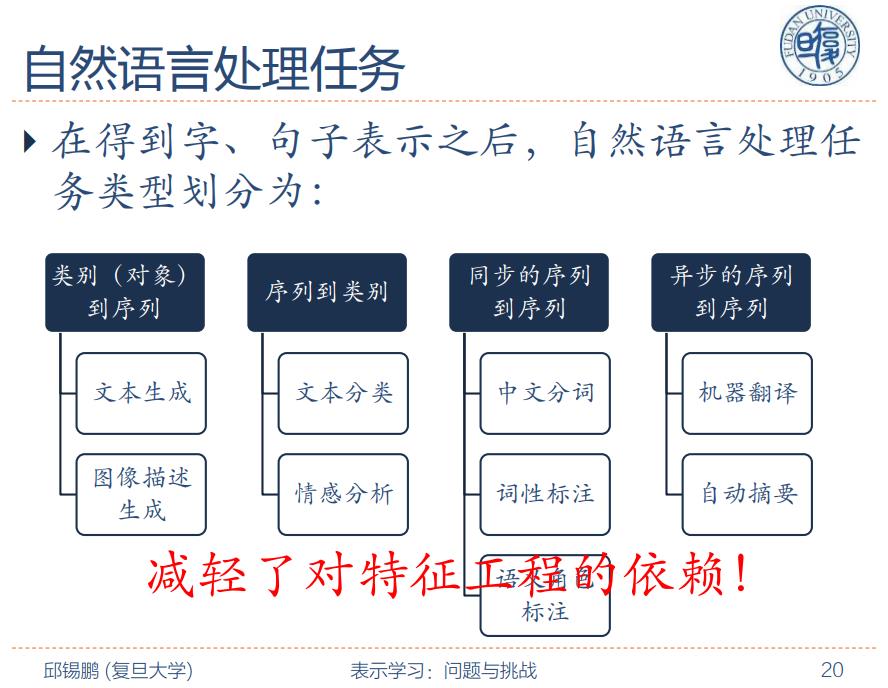
La imagen es del profesor Qiu Xipeng de la Universidad Fudan
THULAC CHILAT TOOL DE TERRAMIENTO DE ANÁLISIS CHINO POR TSINGHUA (C ++/Java/Python)
Nlpir por la Academia de Ciencias de China (Java)
LTP Language Technology Platform de Harbin Institute of Technology (C ++) Pylyp LTP Python Encapsulación
Fudannlp por Fudan (Java)
Baidulac por la herramienta de análisis léxico de código abierto de Baidu para chino, incluida la segmentación de palabras, el etiquetado de parte del voz y el reconocimiento de entidades nombrado.
Hanlp (Java)
FastNLP (Python) Un conjunto de procesamiento NLP ligero.
SnownLP (Python) Biblioteca de Python para procesar texto chino
Yayanlp (Python) Paquete de procesamiento de lenguaje natural chino escrito en Python puro, llamado "Yaya Language"
Xiao Ming NLP (Python) Herramienta de procesamiento de lenguaje natural chino ligero
Deepnlp (Python) Learning Deep Learning NLP Pipeline implementada en TensorFlow con modelos chinos previos a la aparición.
chino_nlp (C ++ y Python) Herramientas y ejemplos de procesamiento de lenguaje natural chino
marco de aprendizaje profundo de procesamiento de lenguaje de Lightnlp (Python) basado en Pytorch y TorchText
Anotador de anotador chino (Python) para el cuerpo chino Corpus Herramienta de texto de texto chino
Poplar (TypeScript) Una herramienta de anotación basada en la web para el procesamiento del lenguaje natural (PNL)
Jiagu (Python) Jiagu se basa en bilstm y otros modelos y está entrenado en corpus a gran escala. Proporcionará funciones comunes de procesamiento del lenguaje natural, como segmentación de palabras chinas, anotación de parte de voz, reconocimiento de entidades de nombres, análisis de sentimientos, extracción de relaciones de gráficos de conocimiento, extracción de palabras clave, resumen de texto y nuevo descubrimiento de palabras.
SmoothNLP (Python y Java) Enfoque en la tecnología PNL interpretable
Foolnltk (Python y Java) Un kit de herramientas de lengua natural china
Corenlp por Stanford (Java) Una suite Java de herramientas de Core NLP.
Estrofa de Stanford (Python) Una biblioteca de Python NLP para muchos idiomas humanos
Kit de herramientas de lenguaje natural NLTK (Python)
Procesamiento del lenguaje natural de fuerza industrial de Spacy (Python) con un curso en línea
Textacy (Python) PNL, antes y después de Spacy
OpenNLP (Java) Un kit de herramientas basado en aprendizaje automático para el procesamiento del texto del lenguaje natural.
Gensim (Python) Gensim es una biblioteca de Python para modelado de temas, indexación de documentos y recuperación de similitud con grandes corporativas.
Kashgari: marco de PNL simple y potente, cree su modelo de última generación en 5 minutos para el reconocimiento de entidad nombrado (NER), el etiquetado de parte de voz (POS) y las tareas de clasificación de texto. Incluye Bert y Word2Vec incrustados.
Jieba Chinese Word Particle (derivado de Python y una gran cantidad de otros lenguajes de programación) es el mejor componente de participio de palabras chinas de Python
La herramienta de segmentación de palabras chinas de la Universidad de Pekín (Python) es una herramienta de segmentación de palabras chinas altamente precisa que es simple y fácil de usar. En comparación con las herramientas de código abierto existentes, mejora en gran medida la precisión de la segmentación de palabras.
KCWS Aprendizaje profundo Participio de palabras chino (Python) Bilstm+CRF e IDCNN+CRF
ID-CNN-CWS (Python) iteró convoluciones dilatadas para la segmentación de palabras chinas
Genius Chinese Word participe (Python) Genius es un componente de participio de palabras chino de código abierto que utiliza el algoritmo de campo aleatorio condicional CRF (campo aleatorio condicional).
Participio chino de Lloss (Python)
Yaha "口" participio chino (Python)
Algoritmo de segmentación de palabras chinas (Python) sin cuerpo sin corpus
GO SEGMIGACIÓN DE TEXTO EFECTIVO; Apoyo inglés, chino, japonés y otros.
ANSJ Participio de palabras chino (Java) Implementación de Java del participio de palabras chino basada en n-gram+CRF+hmm
Mitie (C ++) Biblioteca y herramientas para la extracción de información
Lenguaje, motor y herramientas de Duckling (Haskell) para expresar, probar y evaluar reglas de lenguaje compuestas en cadenas de entrada.
IEPY (Python) IEPY es una herramienta de código abierto para la extracción de información centrada en la extracción de relaciones.
Snorkel Un sistema de creación de datos y gestión de capacitación centrado en la extracción de información
Extracción de relación neuronal implementada con LSTM en TensorFlow
Un modelo de red neuronal para el reconocimiento de entidades con nombre chino
Bert-chines -ner usa el modelo de idioma pre-entrenado Bert para hacer ner chino
Información-extracción china-china China nombrada Reconocimiento de entidad con IDCNN/BILSTM+CRF, y extracción de relación con BigRu+2att Reconocimiento de entidades chinas y extracción de relaciones
Familia Un conjunto de herramientas para modelos de temas industriales producidos por Baidu
Clasificación de texto Todo tipo de modelos de clases de texto y más con aprendizaje profundo. Utilice las preguntas y respuestas de Zhihu como datos de prueba.
Complejecedextracción El concepto y el patrón explícito de los eventos compuestos chinos, incluidos eventos condicionales, eventos causales, eventos de seguimiento, eventos de inversión y otra extracción de eventos, y forman un mapa racional.
Textrank4zh extrae automáticamente palabras clave y resúmenes del texto chino
Rasa Nlu (Python) convierte el lenguaje natural en datos estructurados, una bifurcación china en Rasa Nlu Chi
Rasa Core (Python) Motor de diálogo basado en aprendizaje automático para software de conversación
ChatStack Una interfaz de usuario de tuberías completa para construir un sistema NLU chino
Snips NLU (Python) Snips NLU es una biblioteca de Python que permite analizar oraciones escritas en lenguaje natural y extrae información estructurada.
Deeppavlov (Python) Una biblioteca de código abierto para construir sistemas de diálogo de extremo a extremo y chatbots de capacitación.
Chatscript Herramienta de lenguaje natural/administrador de diálogo, un motor de chatbot basado en reglas.
Chatterbot (Python) Chatterbot es un motor de diálogo conversacional de aprendizaje automático para crear bots de chat.
Chatbot (python) chatbot situacional basado en la coincidencia vectorial
Tipask (PHP) es un sistema de preguntas y respuestas de PHP de código abierto desarrollado basado en el marco de Laravel, fácil de escala, con una fuerte capacidad de carga y estabilidad.
PreguntHAnsweringSystem (Java) Un sistema de preguntas y respuestas humanos implementados con Java que puede analizar automáticamente las preguntas y dar respuestas a los candidatos.
QA-Snake (Python) Preguntas y respuestas automáticas basadas en motores de búsqueda múltiple y tecnologías de aprendizaje profundo
Modelo de secuencia de chatbot a la secuencia implementado usando TensorFlow (Python)
Sistema de preguntas y respuestas de comprensión de lectura china (Python) implementado por algoritmo de aprendizaje profundo
Anyq de Baidu incluye principalmente un marco del sistema de preguntas y respuestas para las colecciones de preguntas frecuentes y una herramienta de coincidencia semántica de texto SIMNET.
Código de referencia de comprensión de lectura china de Dureader (Python)
Marco de robot automático basado en SmartQQ (Python)
QasystemonMedicalKG (Python) Un gráfico de conocimiento centrado en la enfermedad para campos médicos, y utiliza este gráfico de conocimiento para completar las preguntas y respuestas automáticas y los servicios de análisis.
GPT2-Chitchat (Python) Modelo GPT2 para el chat chino
CDIAL-GPT (Python) proporciona un conjunto de datos de diálogo chino a gran escala y proporciona un modelo previamente capacitado del diálogo chino (modelo GPT chino) en este conjunto de datos
Openkg.cn
Archema de mapa de conocimiento de color chino abierto
Mapa conceptual chino a gran escala CN-Probase Introducción de cuenta oficial
Descarga de código abierto a gran escala de 140 millones de gráficos de conocimiento chino
Recuperación de información del gráfico de conocimiento agrícola, reconocimiento de entidad nombrado, extracción de relaciones, construcción de árboles de clasificación, minería de datos en el campo agrícola
CLDC Alianza de recursos de idioma chino
Volcado de Wikipedia chino
Marco de modelos pre-entrenado chino basado en diferentes corpus y diferentes modelos (como Bert y GPT), admite modelos previamente capacitados para diferentes tareas de corpus, codificadores y objetivo (de RUC y Tencent)
OpenClap Multi-Dominio Open Open Language Model Repository (de Tsinghua)
1998 Biblioteca de anotaciones parciales diarias de 1998 People @baidupan
Sogou 20061127 News Corpus (incluidas categorías) @ Baidu Pan
Udchinese (para entrenar a Spacy POS)
Modelo chino Word2Vec
Cientos de vectores de palabras chinos pretrados
Tencent AI Lab Incorporación del corpus para palabras y frases chinas
Bert de pre-entrenamiento chino con enmascaramiento de palabras enteras
El código de entrenamiento chino GPT2 puede escribir poesía, noticias, novelas o capacitar a modelos de idiomas generales.
Evaluación del idioma chino Evaluación de referencia China Glue incluye conjuntos de datos representativos, modelos de referencia (previamente), corpus y clasificaciones.
La base de datos del diccionario de Xinhua chino incluye modismos, modismos, palabras y caracteres chinos.
Sinónimos: el kit de herramientas de sinónimos chinos se basa en los sinónimos de la capacitación de Wikipedia China y Word2Vec y se encapsula como un archivo de paquete Python.
Chino_conversation_sentiment Un conjunto de datos de sentimiento chino puede ser útil para el análisis de sentimientos.
Corpus de emergencia chino
DGK_LOST_CONV Corpus de diálogo chino
Conjuntos de datos para capacitar al sistema de chatbot
Versión de Bagua de la respuesta china
Corpus de chat público chino
La información de anuncio del mercado de valores de China se arrastra para obtener el anuncio del mercado de valores de China (SZ, SH) del servidor de Juchao Network a través de Python Scripts (compañías que cotizan en bolsa y agencias reguladoras)
Tushare Financial Data Interface Tushare es un paquete de interfaz de datos financieros de Python de código abierto y gratuito.
Conjuntos de datos de texto financiero Smoothnlp conjuntos de datos de texto financiero (público) conjuntos de datos financieros públicos para investigaciones de PNL
Corpus de la industria de seguros [52NLP Introducción al blog] Opendata en el área de seguros para tareas de aprendizaje automático
La base de datos más completa de la antigua poesía y letra china. Casi 14,000 poetas de las dinastías Tang y Song, casi 55,000 poemas Tang y 260,000 poemas de canciones. Había 1.564 poetas en la dinastía de la canción y 21.050 poemas.
Datos de comprensión de lectura china de durroader
Los datos pequeños del corpus chino incluyen algunos datos pequeños, como el reconocimiento de entidades con nombre chino, el reconocimiento de la relación china, la comprensión de lectura china, etc.
Litero-Literatura china-gan-re-dataset Un conjunto de datos de extracción de reconocimiento de entidad y reconocimiento de la entidad con nombre de discurso para el texto de la literatura china
Proyecto de inferencia de texto chino ChinesetextualIference, incluida la traducción y construcción de 880,000 conjuntos de datos chinos que contienen texto que contienen texto, y el modelo de juicio que contiene texto basado en el aprendizaje profundo.
Corpus de procesamiento de lenguaje natural chino a gran escala Wikipedia (Wiki2019zh), Corpus News (News2016zh), Q&A de Enciclopedia (BAIKE2018QA)
Nombre chino Corpus Nombre chino, apellido, nombre, nombre, nombre, nombre japonés, nombre de traducción, nombre de inglés.
Nombre de la empresa, Nombre de la organización Corpus Abreviatura de la empresa, abreviatura, palabra de marca, nombre empresarial.
Varias implementaciones de filtrado de palabras confidencial en la base de datos de palabras confidenciales chinas + una cierta base de datos de palabras sensibles a las palabras de 1 W
Abreviación china Un corpus de la abreviatura china, incluidas las formas completas negativas.
Materiales de preprocesamiento de datos chinos Diccionario de participio de palabras chino y palabras de parada china
Diccionario Han Chino
Sentibridge: La base de conocimiento emocional de la entidad china describe cómo las personas describen una entidad, incluidas noticias, turismo y catering, un total de 300,000 pares.
OpenCorpus una colección de corporativas disponibles gratuitamente (chino).
Análisis de propensión de chinesenlpcorpus emocional/de punto de vista/comentario, reconocimiento de entidad de nombres chinos, sistema de recomendación
FinancialDataSets SmoothNlP TEXTO DE TEXTO FINANCIERO (público) conjuntos de datos financieros públicos solo para investigaciones de PNL
People's Daily & Children's Fairy Tale PD & CFT: un conjunto de datos de comprensión de lectura china
Wiki chino 230,000 entradas de alta calidad - Actualizadas al 23 de julio - Información sensible o controvertida filtrada
Laboratorio de procesamiento del lenguaje natural y Laboratorio de Computación de Humanidades de la Universidad de Tsinghua
Laboratorio clave del Ministerio de Educación, Lingüística computacional, Universidad de Pekín
Grupo de investigación de procesamiento de lenguaje natural, Instituto de Computación, Academia de Ciencias de China
Laboratorio de procesamiento de tecnología inteligente del Instituto Harbin de Tecnología y Procesamiento de Lenguas Naturales
Centro de Investigación de Recuperación de Información y Computación Social del Instituto Harbin de Tecnología
Grupo de procesamiento del lenguaje natural de la Universidad de Fudan
Grupo de procesamiento del lenguaje natural de la Universidad Soochow
Grupo de investigación de procesamiento de lenguaje natural de la Universidad de Nanjing
Laboratorio de procesamiento del lenguaje natural de la Northeastern University
Laboratorio de procesamiento de lenguaje natural, Departamento de Ciencia y Tecnología Inteligentes, Universidad de Xiamen
Laboratorio de procesamiento del lenguaje natural de la Universidad de Zhengzhou
Instituto de Investigación de Microsoft de Asia Procesamiento de lenguaje natural
Laboratorio Arca de Huawei Noah
Grupo minero de texto de Cuhk
Grupo de minería de redes sociales de Polyu
Centro de tecnología del lenguaje humano HKust
Laboratorio de NLP de la Universidad Nacional de Taiwán
Sociedad de la Información China
Las conferencias principales, revistas, talleres y tareas compartidas en la comunidad de PNL.
2017 La primera evaluación de comprensión de lectura a máquina "Copa Iflying"
La descripción china 2017 de la imagen china 2017 describe la información principal en una imagen determinada en una oración, desafiando el problema de comprensión de la imagen en el contexto chino.
La traducción de texto a gran escala 2017 AI-Challenger Inglés-chino utiliza datos a gran escala para mejorar las capacidades de los modelos de traducción automática de texto en inglés-chino.
El 2017 Zhihu Kanshan Cup Machine Learning Challenge entrena un modelo que etiqueta automáticamente los datos no etiquetados en función de los datos de entrenamiento de la relación vinculante de los problemas dados por Zhihu y las etiquetas de los temas.
Tarea de preguntas y respuestas chinas de 2018 en el dominio abierto para una pregunta china dada, el sistema de preguntas y respuestas selecciona varias entidades o valores de atributos de una base de conocimiento determinada como la respuesta a la pregunta.
2018 Webank Inteligent Service Chustsing Pregunta La competencia de coincidencia coincide con preguntas sobre el Corpus de servicio al cliente real en chino; Dadas dos oraciones, determine si las intenciones de los dos son similares.
Huawei Cloud NLP es un servicio en la nube para el análisis de texto y la minería proporcionada por varias empresas y desarrolladores, con el objetivo de ayudar a los usuarios a procesar el texto de manera eficiente.
Baidu Cloud NLP proporciona tecnología de procesamiento de lenguaje natural líder en la industria, que proporciona procesamiento de texto de alta calidad y tecnología de comprensión
Alibaba Cloud NLP proporciona herramientas principales para el análisis y minería de texto para todo tipo de empresas y desarrolladores
Tencent Cloud NLP se basa en sistemas de calculación y rastreo distribuidos paralelos, combinados con una tecnología de análisis semántico único, y cumple con PNL, transcodificación, extracción, rastreo de datos y otras necesidades en una sola parada.
Iflytek Open Platform con interacción de voz como la plataforma Core Artificial Intelligence Open
Participio de palabras de laboratorio de Sogou y anotación de parte del discurso
Bosen Data Shanghai Bosen Data Technology Co., Ltd. Se centra en la tecnología de análisis semántico chino
Yunfu Technology NLP Toolkit, gráfico de conocimiento, minería de texto, sistema de diálogo, análisis de opinión pública, etc.
La tecnología Zhiyan se centra en los avances en el aprendizaje profundo y la tecnología de gráficos de conocimiento
La tecnología Zhuiyi se centra en el aprendizaje profundo y el procesamiento del lenguaje natural
Libro de aprendizaje profundo chino
Procesamiento del lenguaje natural Stanford CS224N con Learning Deep 2017
Oxford CS Deepnlp 2017
[Materiales del curso para Georgia Tech CS 4650 y 7650, "lenguaje natural"] (https://github.com/jacobeisenstein/gt-nlp-class)
Procesamiento del habla y el lenguaje por Dan Jurafsky y James H. Martin
52NLP me encanta el procesamiento del lenguaje natural
Hankcs Code Farm
Procesamiento de texto Materiales del curso práctico Procesamiento de texto Materiales del curso práctico incluyen extracción de características de texto (TF-IDF), clasificación de texto, agrupación de texto, Vector de palabras de Word2Vec y sinónimo de palabras de similitud de palabras de palabras chinas, resumen automático de documentos, extracción de información, análisis de sentimientos y minería de opinión y otros experimentos.
Tareas de procesamiento del lenguaje natural NLP_Tasks y referencias seleccionadas
Introducción a la investigación de PNL del maestro de la Universidad de Tsinghua Liu Zhiyuan
Tareas compartidas en PNL chinas, conjuntos de datos y resultados de vanguardia para el procesamiento de lenguaje natural chino


