Awesome Chinese NLP
1.0.0
A curated list of resources for NLP (Natural Language Processing) for Chinese
Chinese natural language processing related information
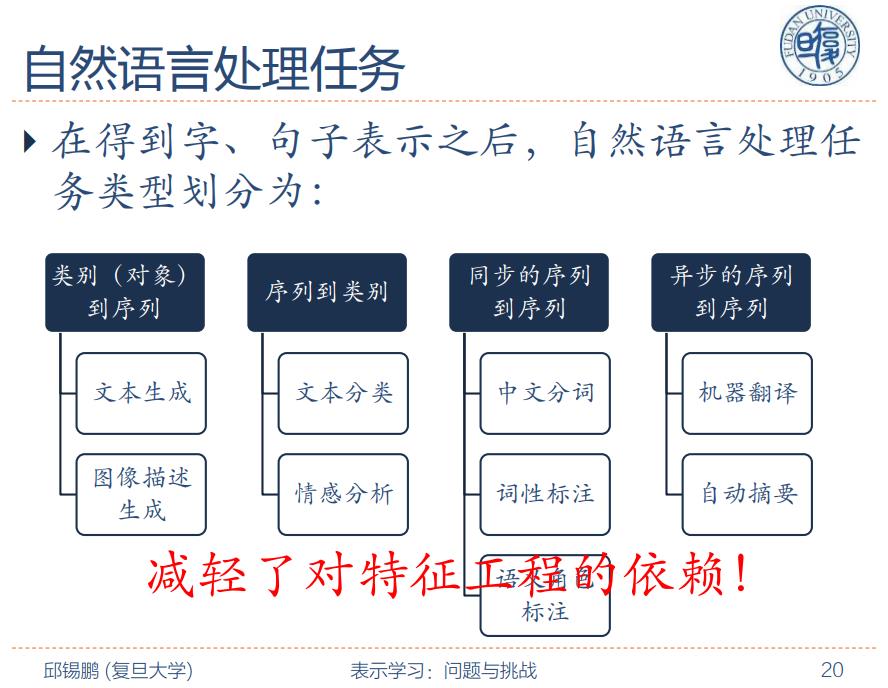
The picture is from Professor Qiu Xipeng of Fudan University
THULAC Chinese lexical analysis toolkit by Tsinghua (C++/Java/Python)
NLPIR by Chinese Academy of Sciences (Java)
LTP language technology platform by Harbin Institute of Technology (C++) pylyp LTP python encapsulation
FudanNLP by Fudan (Java)
BaiduLac by Baidu's open-source lexical analysis tool for Chinese, including word segmentation, part-of-speech tagging & named entity recognition.
HanLP (Java)
FastNLP (Python) A lightweight NLP processing suite.
SnowNLP (Python) Python library for processing Chinese text
YaYaNLP (Python) Chinese natural language processing package written in pure python, named "Yaya Language"
Xiao Ming NLP (Python) Lightweight Chinese Natural Language Processing Tool
DeepNLP (Python) Deep Learning NLP Pipeline implemented on Tensorflow with pretrained Chinese models.
chinese_nlp (C++ & Python) Chinese Natural Language Processing tools and examples
lightNLP (Python) Natural language processing deep learning framework based on Pytorch and torchtext
Chinese-Annotator (Python) Annotator for Chinese Text Corpus Chinese Text Annotator Tool
Poplar (Typescript) A web-based annotation tool for natural language processing (NLP)
Jiagu (Python) Jiagu is based on BiLSTM and other models and is trained on large-scale corpus. It will provide common natural language processing functions such as Chinese word segmentation, part-of-speech annotation, naming entity recognition, sentiment analysis, knowledge graph relationship extraction, keyword extraction, text summary, and new word discovery.
SmoothNLP (Python & Java) Focus on interpretable NLP technology
FoolNLTK (Python & Java) A Chinese Nature Language Toolkit
CoreNLP by Stanford (Java) A Java suite of core NLP tools.
Stanza by Stanford (Python) A Python NLP Library for Many Human Languages
NLTK (Python) Natural Language Toolkit
spaCy (Python) Industrial-Strength Natural Language Processing with a online course
textacy (Python) NLP, before and after spaCy
OpenNLP (Java) A machine learning based toolkit for the processing of natural language text.
gensim (Python) Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corporate.
Kashgari - Simple and powerful NLP framework, build your state-of-art model in 5 minutes for named entity recognition (NER), part-of-speech tagging (PoS) and text classification tasks. Includes BERT and word2vec embedded.
Jieba Chinese word participle (derived by Python and a large number of other programming languages) is the best Python Chinese word participle component
Peking University Chinese word segmentation tool (Python) is a highly accurate Chinese word segmentation tool that is simple and easy to use. Compared with existing open source tools, it greatly improves the accuracy of word segmentation.
kcws Deep Learning Chinese Word Participle (Python) BiLSTM+CRF and IDCNN+CRF
ID-CNN-CWS (Python) Iterated Dilated Convolutions for Chinese Word Segmentation
Genius Chinese word participle (Python) Genius is an open source python Chinese word participle component that uses CRF (Conditional Random Field) conditional random field algorithm.
loso Chinese participle (Python)
yaha "口" Chinese participle (Python)
ChineseWordSegmentation (Python) Chinese word segmentation algorithm without corpus
Go efficient text segmentation; support english, chinese, japanese and other.
Ansj Chinese word participle (java) Java implementation of Chinese word participle based on n-Gram+CRF+HMM
MITIE (C++) library and tools for information extraction
Duckling (Haskell) Language, engine, and tooling for expressing, testing, and evaluating composable language rules on input strings.
IEPY (Python) IEPY is an open source tool for Information Extraction focused on Relation Extraction.
Snorkel A training data creation and management system focused on information extraction
Neural Relation Extraction implemented with LSTM in TensorFlow
A neural network model for Chinese named entity recognition
bert-chinese-ner Use pre-trained language model BERT to do Chinese NER
Information-Extraction-Chinese Chinese Named Entity Recognition with IDCNN/biLSTM+CRF, and Relation Extraction with biGRU+2ATT Chinese Entity Recognition and Relation Extraction
Familia A Toolkit for Industrial Topic Modeling produced by Baidu
Text Classification All kinds of text classificaiton models and more with deep learning. Use Zhihu Q&A as the test data.
ComplexEventExtraction The concept and explicit pattern of Chinese compound events, including conditional events, causal events, follow-up events, reversal events and other event extraction, and form a rational map.
TextRank4ZH Automatically extract keywords and abstracts from Chinese text
Rasa NLU (Python) turn natural language into structured data, a Chinese fork at Rasa NLU Chi
Rasa Core (Python) machine learning based dialogue engine for conversational software
Chatstack A Full Pipeline UI for building Chinese NLU System
Snips NLU (Python) Snips NLU is a Python library that allows to parse sentences written in natural language and extracts structured information.
DeepPavlov (Python) An open source library for building end-to-end dialog systems and training chatbots.
ChatScript Natural Language tool/dialog manager, a rule-based chatbot engine.
Chatterbot (Python) ChatterBot is a machine learning, conversational dialog engine for creating chat bots.
Chatbot (Python) Situational Chatbot based on vector matching
Tipask (PHP) is an open source PHP question and answer system developed based on the Laravel framework, easy to scale, with strong load capacity and stability.
QuestionAnsweringSystem (Java) A Java-implemented human-computer question and answer system that can automatically analyze questions and give candidate answers.
QA-Snake (Python) Automatic Q&A based on multi-search engines and deep learning technologies
Chatbot Model of Sequence to Sequence implemented using TensorFlow (Python)
Chinese Reading Comprehension Question and Answer System (Python) Implemented by Deep Learning Algorithm
AnyQ by Baidu mainly includes a question-and-answer system framework for FAQ collections and a text semantic matching tool SimNet.
DuReader Chinese Reading Comprehension Baseline Code (Python)
Automatic robot framework based on SmartQQ (Python)
QASystemOnMedicalKG (Python) A disease-centered knowledge graph for medical fields, and uses this knowledge graph to complete automatic Q&A and analysis services.
GPT2-chitchat (Python) GPT2 model for Chinese chat
CDial-GPT (Python) provides a large-scale Chinese dialogue dataset and provides a Chinese dialogue pre-trained model (Chinese GPT model) on this dataset
OpenKG.cn
Open Chinese knowledge map schema
Large-scale Chinese concept map CN-Probase official account introduction
Large-scale open source download of 140 million Chinese knowledge graph
Agricultural Knowledge Graph Information retrieval, named entity recognition, relationship extraction, classification tree construction, data mining in the agricultural field
CLDC Chinese Language Resource Alliance
Chinese Wikipedia Dump
Chinese pre-trained model framework based on different corpus and different models (such as BERT and GPT), supports pre-trained models for different corpus, encoder, and target tasks (from RUC and Tencent)
OpenCLaP Multi-Domain Open Source Chinese Pre-trained Language Model Repository (from Tsinghua)
1998 People's Daily Partial Annotation Library @Baidupan
Sogou 20061127 News Corpus (including categories) @ Baidu Pan
UDChinese (for training spaCy POS)
Chinese word2vec model
Hundreds of pre-trained Chinese word vectors
Tencent AI Lab Embedding Corpus for Chinese Words and Phrases
Chinese Pre-training BERT with Whole Word Masking
Chinese GPT2 training code can write poetry, news, novels, or train general language models.
Chinese Language Understanding Assessment Benchmark ChineseGLUE includes representative data sets, benchmark (pretrained) models, corpus, and rankings.
The Chinese Xinhua Dictionary database includes idioms, idioms, words, and Chinese characters.
Synonyms: The Chinese synonyms toolkit is based on the synonyms of Wikipedia Chinese and word2vec training and is encapsulated as a python package file.
Chinese_conversation_sentiment A Chinese sentiment dataset may be useful for sentiment analysis.
Chinese Emergency Corpus
dgk_lost_conv Chinese dialogue corpus
Datasets for Training Chatbot System
Bagua version of Chinese answer
Chinese public chat corpus
China Stock Market Announcement Information Crawling to obtain the announcement of China Stock Market (sz, sh) from the server of Juchao Network through python scripts (listed companies and regulatory agencies)
tushare financial data interface TuShare is a free and open source python financial data interface package.
Financial text datasets SmoothNLP Financial text datasets (public) Public Financial Datasets for NLP Researches
Insurance Industry Corpus [52nlp Introduction to Blog] OpenData in insurance area for Machine Learning Tasks
The most complete database of ancient Chinese poetry and lyrics. Nearly 14,000 poets of the Tang and Song dynasties, nearly 55,000 Tang poems and 260,000 Song poems. There were 1,564 poets in the Song dynasty and 21,050 poems.
DuReader Chinese reading comprehension data
Small data of Chinese corpus include some small data such as Chinese named entity recognition, Chinese relationship recognition, Chinese reading comprehension, etc.
Chinese-Literature-NER-RE-Dataset A Discourse-Level Named Entity Recognition and Relation Extraction Dataset for Chinese Literature Text
ChineseTextualInference Chinese text inference project, including the translation and construction of 880,000 text-containing Chinese text-containing data sets, and the text-containing judgment model based on deep learning.
Large-scale Chinese natural language processing corpus Wikipedia (wiki2019zh), news corpus (news2016zh), encyclopedia Q&A (baike2018qa)
Chinese name corpus Chinese name, surname, name, name, name, Japanese name, translation name, English name.
Company name, organization name corpus Company abbreviation, abbreviation, brand word, enterprise name.
Several implementations of sensitive word filtering in Chinese sensitive word database + a certain 1w word sensitive word database
Chinese abbreviation A corpus of Chinese abbreviation, including negative full forms.
Chinese data preprocessing materials Chinese word participle dictionary and Chinese stop words
Han Chinese dictionary
SentiBridge: The Chinese entity emotional knowledge base describes how people describe an entity, including news, tourism, and catering, a total of 300,000 pairs.
OpenCorpus A collection of freely available (Chinese) corporate.
ChineseNlpCorpus Emotional/Viewpoint/Comment Proneness Analysis, Chinese Naming Entity Recognition, Recommendation System
FinancialDatasets SmoothNLP Financial Text Datasets (public) Public Financial Datasets for NLP Researches Only
People's Daily & Children's Fairy Tale PD&CFT: A Chinese Reading Comprehension Dataset
Chinese Wiki 230,000 high-quality entries - updated to July 23 - Filtered sensitive or controversial information
Natural Language Processing and Humanities Computing Laboratory of Tsinghua University
Key Laboratory of Ministry of Education, Computational Linguistics, Peking University
Natural Language Processing Research Group, Institute of Computing, Chinese Academy of Sciences
Harbin Institute of Technology Intelligent Technology and Natural Language Processing Laboratory
Harbin Institute of Technology Social Computing and Information Retrieval Research Center
Fudan University Natural Language Processing Group
Natural Language Processing Group of Soochow University
Natural Language Processing Research Group of Nanjing University
Natural Language Processing Laboratory of Northeastern University
Natural Language Processing Laboratory, Department of Intelligent Science and Technology, Xiamen University
Natural Language Processing Laboratory of Zhengzhou University
Microsoft Research Institute of Asia Natural Language Processing
Huawei Noah's Ark Laboratory
CUHK Text Mining Group
PolyU Social Media Mining Group
HKUST Human Language Technology Center
National Taiwan University NLP Lab
Chinese Information Society
NLP Conference Calender Main conferences, journals, workshops and shared tasks in NLP community.
2017 The first "iFlying Cup" Chinese Machine Reading Comprehension Evaluation
2017 AI-Challenger Image Chinese Description describes the main information in a given image in one sentence, challenging the image understanding problem in the Chinese context.
2017 AI-Challenger English-Chinese machine text translation uses large-scale data to improve the capabilities of English-Chinese text machine translation models.
The 2017 Zhihu Kanshan Cup Machine Learning Challenge trains a model that automatically labels unlabeled data based on the training data of the binding relationship of the problems given by Zhihu and the topic tags.
2018 Chinese Q&A Task in Open Domain For a given Chinese question, the Q&A system selects several entities or attribute values from a given knowledge base as the answer to the question.
2018 WeBank Intelligent Customer Service Question Matching Competition matches questions on the real customer service corpus in Chinese; given two sentences, determine whether the intentions of the two are similar.
Huawei Cloud NLP is a cloud service for text analysis and mining provided by various enterprises and developers, aiming to help users process text efficiently.
Baidu Cloud NLP provides industry-leading natural language processing technology, providing high-quality text processing and understanding technology
Alibaba Cloud NLP provides core tools for text analysis and mining for all kinds of enterprises and developers
Tencent Cloud NLP is based on parallel computing and distributed crawling systems, combined with unique semantic analysis technology, and meets NLP, transcoding, extraction, data crawling and other needs in one stop.
iFLYTEK Open Platform with voice interaction as the core artificial intelligence open platform
Sogou Laboratory word participle and part-of-speech annotation
Bosen Data Shanghai Bosen Data Technology Co., Ltd. focuses on Chinese semantic analysis technology
Yunfu Technology NLP toolkit, knowledge graph, text mining, dialogue system, public opinion analysis, etc.
Zhiyan Technology focuses on breakthroughs in deep learning and knowledge graph technology
Zhuiyi Technology focuses on deep learning and natural language processing
Chinese Deep Learning Book
Stanford CS224n Natural Language Processing with Deep Learning 2017
Oxford CS DeepNLP 2017
[Course materials for Georgia Tech CS 4650 and 7650, "Natural Language"] (https://github.com/jacobeisenstein/gt-nlp-class)
Speech and Language Processing by Dan Jurafsky and James H. Martin
52nlp I love natural language processing
hankcs code farm
Text processing practical course materials Text processing practical course materials include text feature extraction (TF-IDF), text classification, text clustering, word2vec training word vector and synonym word forest Chinese word similarity calculation, automatic document summary, information extraction, sentiment analysis and opinion mining and other experiments.
nlp_tasks Natural Language Processing Tasks and Selected References
Introduction to NLP research from Tsinghua University Teacher Liu Zhiyuan
Chinese NLP Shared tasks, datasets and state-of-the-art results for Chinese Natural Language Processing


