CollaRE
v1.4

Collare es una herramienta para la ingeniería inversa colaborativa que tiene como objetivo permitir que los equipos que necesitan usar más de una herramienta durante un proyecto para colaborar sin la necesidad de compartir los archivos en una ubicación separada. También contiene una administración de usuarios muy simple y, como tal, se puede utilizar para un servidor de proyectos múltiples donde los diferentes equipos trabajan en diferentes proyectos. El back-end de la herramienta es una Flask app simple con nginx frente a TI en Docker que funciona con archivos y manifiestas basadas en JSON que contienen los datos relevantes. El front-end es una herramienta GUI basada en PYQT con una interfaz simple que permite administrar los proyectos y trabajar con los archivos binarios y sus correspondientes bases de datos de ingeniería inversa. A partir de ahora, la herramienta es compatible con Binary Ninja , Cutter (Rizin) , Ghidra , Hopper Dissassembler , IDA , JEB y Android Studio (Decompiled by JADX) . La implementación se abstrae del funcionamiento interno de estas herramientas tanto como sea posible para evitar problemas con cualquier cambio de API y, por lo tanto, no se integra directamente en aquellas herramientas en forma de complemento (excepto los complementos de migración de datos que se describen a continuación). El trabajo se basa exclusivamente en administrar los archivos producidos por estas herramientas (literalmente basado en las extensiones de archivos bien conocidas) y simples operaciones check-out y check-in svn.
Obtenga la última versión binaria de este repositorio o clone el repositorio y ejecute sudo python3 setup.py install en Linux o use la línea de comandos en Windows y ejecute python3 setup.py install . En Linux, esto instalará la herramienta en la PATH y podrá ejecutarla simplemente con el comando collare . En Windows esto pondrá el archivo en el C:Users<USERNAME>AppDataLocalProgramsPython<PYTHON_VERSION>Scriptscollare.exe (dependiendo de cómo instaló Python).
Para UIS de escritorio basado en GNOME, puede usar el siguiente archivo de escritorio (las rutas a los archivos pueden variar según la versión de Collare y Python):
[Desktop Entry]
Type=Application
Encoding=UTF-8
Name=CollaRE
Exec=/usr/local/bin/collare
Icon=/usr/local/lib/python3.8/dist-packages/collare-1.2-py3.8.egg/collare/icons/collare.png
Terminal=false
Para habilitar el soporte para el cortador, agregue un Cutter de archivo a su ruta (cuando abra cmd / terminal Writing Cutter debe iniciar la aplicación). Al guardar proyectos de Cutter (Rizin), debe agregar manualmente .rzdb . No elimine la extensión que el archivo ya tiene ( exe más o so , por ejemplo).
Para habilitar el soporte para Ninja binario, agregue un archivo binaryninja a su ruta (cuando abre cmd / terminal escribiendo binaryninja debe iniciar la aplicación). Binary Ninja está eliminando las extensiones de archivos de forma predeterminada, sin embargo, la herramienta cuenta para esto, por lo que no es necesario volver a colocar la extensión del archivo original manualmente. Guardar los proyectos como está en una ruta predeterminada es suficiente para poder presionar con éxito la base de datos bndb local.
Para habilitar el soporte de Hopper Dissembler, agregue una Hopper de archivo a su ruta (cuando abra cmd / terminal Writing Hopper debe iniciar la aplicación). Hopper está eliminando las extensiones de archivos de forma predeterminada, sin embargo, la herramienta cuenta para esto, por lo que no es necesario volver a colocar la extensión del archivo original manualmente. Guardar los proyectos simplemente con Ctrl+S es suficiente para poder impulsar con éxito la base de datos LOP hop .
Para habilitar el soporte para JEB, agregue un archivo jeb a su ruta (cuando abra cmd / terminal Writing jeb debe iniciar la aplicación). Esto se puede hacer renombrando el archivo de script de corredor predeterminado para su sistema operativo a jeb (para Windows, esto en realidad sería jeb.bat ).
Para habilitar el soporte para la herramienta IDA, agregue los archivos ida64 e ida a su ruta (cuando abre cmd / terminal Writing ida64 / ida debe iniciar la aplicación).
Para habilitar el soporte de esta herramienta, agregue un archivo ghidraRun y analyzeHeadless ( .bat para Windows) a su ruta (cuando abra cmd / terminal Writing ghidraRun debe iniciar la aplicación). Tenga en cuenta que analyzeHeadless está en la carpeta support en el directorio root de Ghidra, así que asegúrese de ajustar PATH para acomodar ambos archivos. El proceso de inicialización de la base de datos con Ghidra es un poco más complicado, ya que no hay forma de que Ghidra procese los archivos sin crear un proyecto. Por lo tanto, para poder impulsar la base de datos Ghidra (denominada ghdb ), se le pedirá que cree un proyecto manualmente siempre que el procesamiento automático falle (básicamente cada vez que el archivo que procesa no es ELF/PE) y luego especifique la ruta al archivo gpr (lo siento).
Como los archivos APK y JAR a menudo se encuentran durante los esfuerzos de ingeniería inversa, la herramienta Collare también admite trabajar con este tipo de archivos. Para habilitar el soporte de estas herramientas, es necesario asegurarse de que los archivos android-studio y jadx estén en la ruta (cuando abre cmd / terminal escribiendo android-studio / jadx debe iniciar la aplicación). La herramienta JADX se utiliza para realizar la descompilación del archivo JAR/APK y el estudio Android se usa para abrir los archivos resultantes. Tenga en cuenta que el uso de Android Studio es opcional, ya que puede alias cualquier otra herramienta que maneje proyectos de graduación bajo el comando android-studio (como la idea IntelliJ).
Después de implementar el lado del servidor como se menciona en su propio archivo ReadMe, es necesario distribuir el archivo de certificado usado a todos los usuarios de la aplicación, así como usar la cuenta admin predeterminada con la contraseña admin para crear otras cuentas de usuario (no olvide cambiar la contraseña del usuario admin ) a través de la pestaña Admin . Cuando los usuarios están configurados, cualquiera puede crear sus propios proyectos y comenzar a trabajar con la herramienta misma.
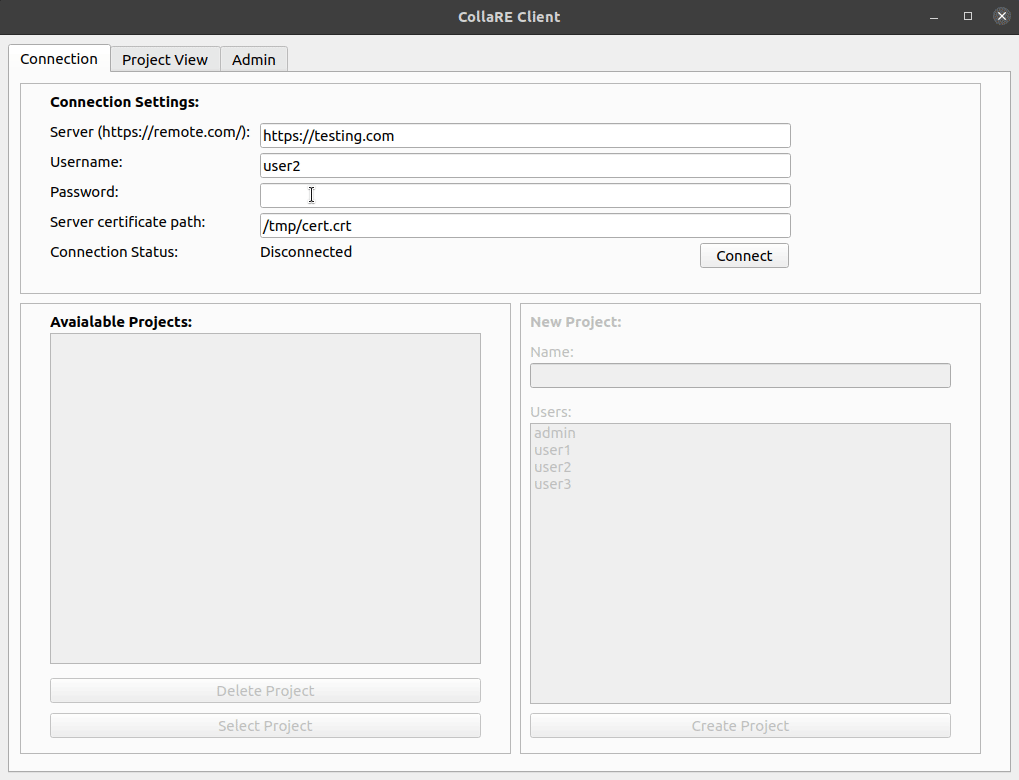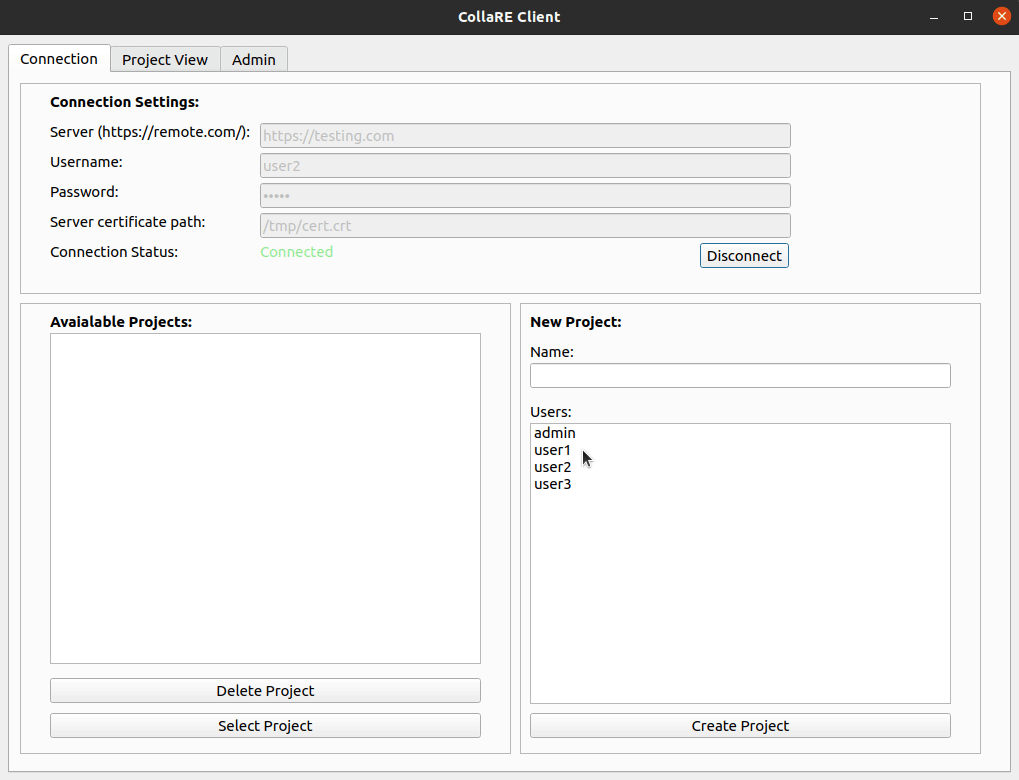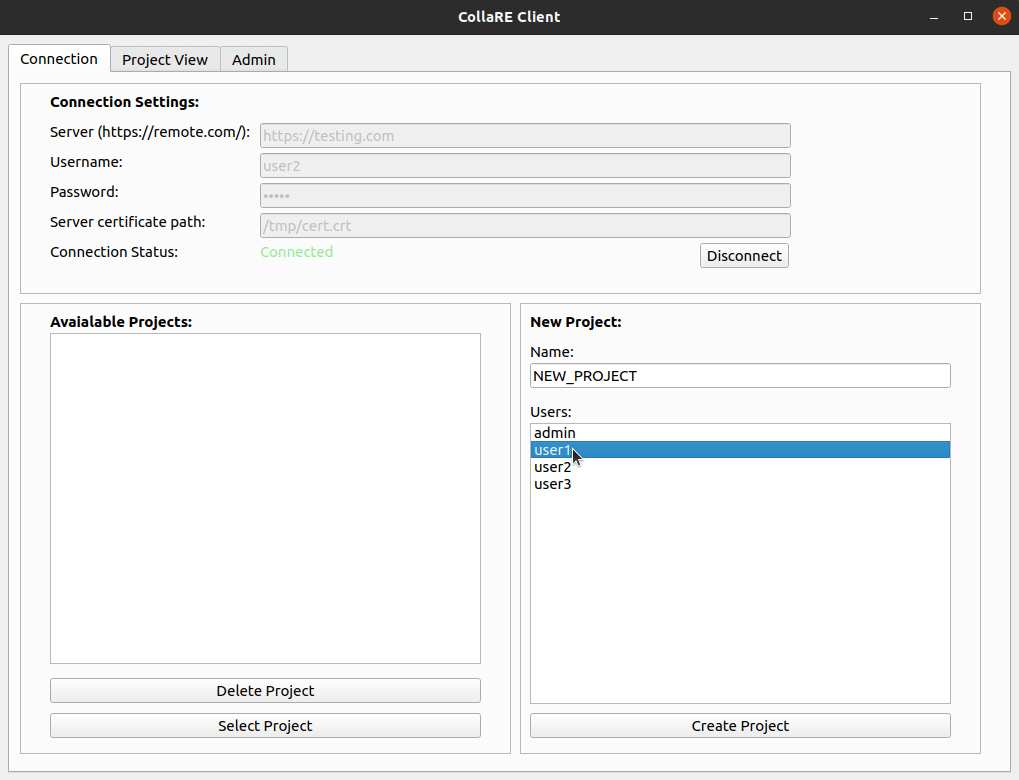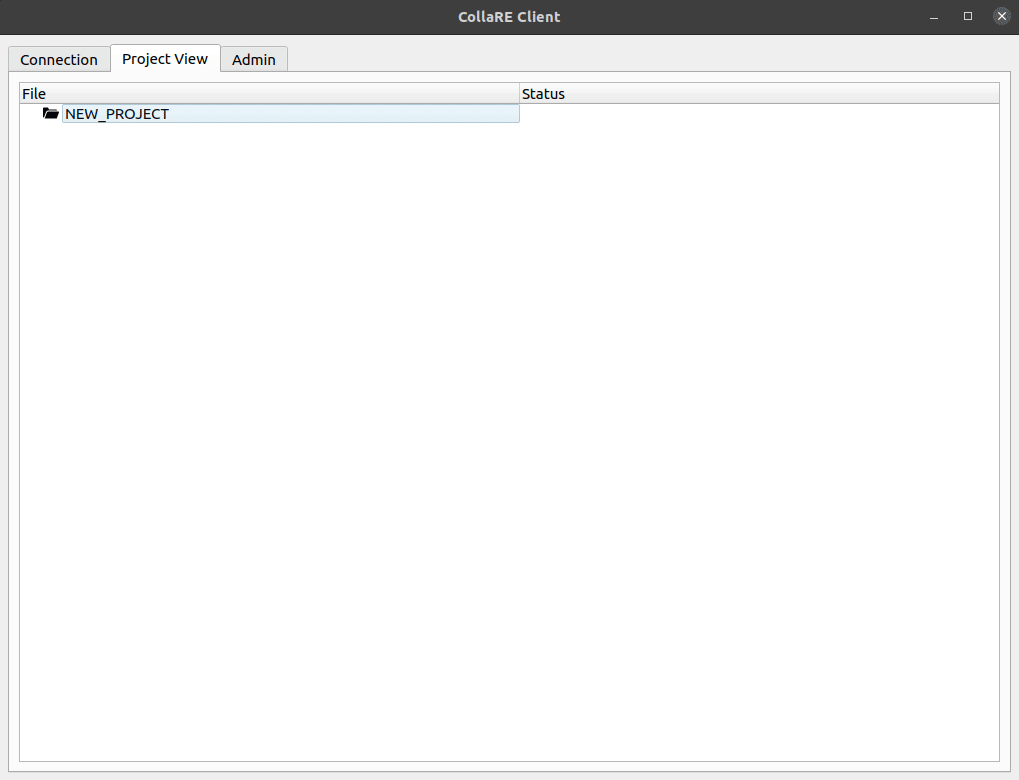
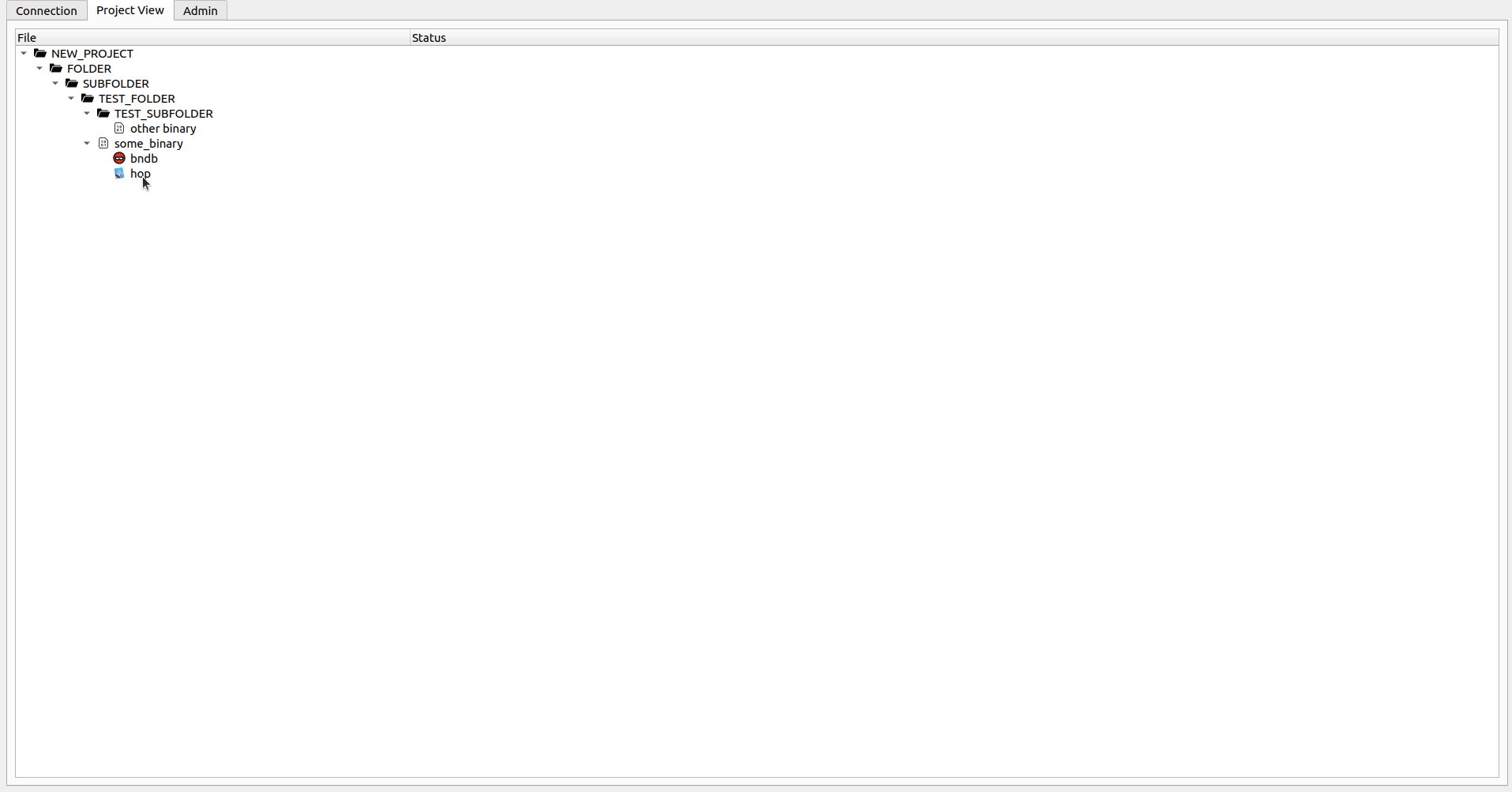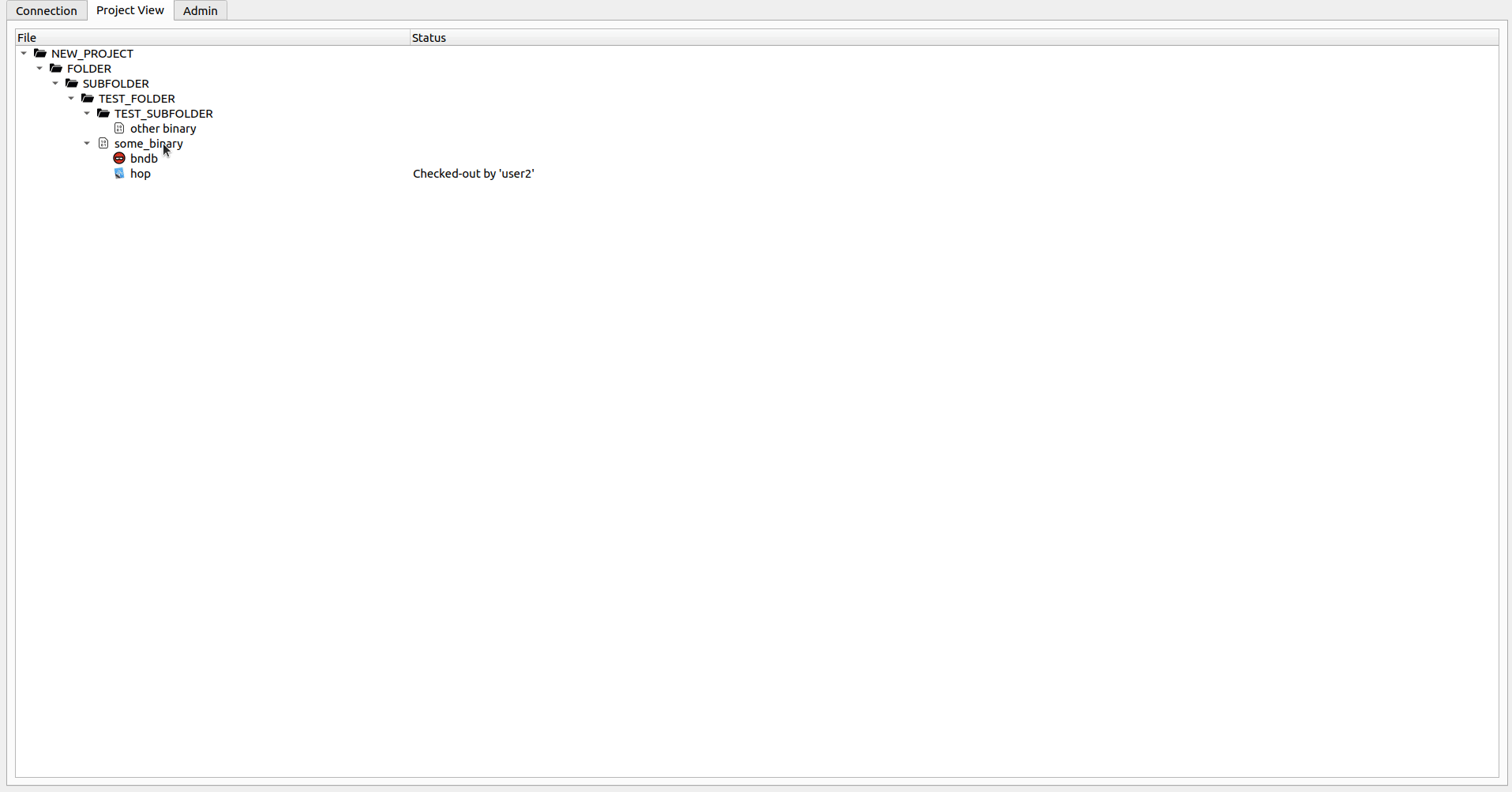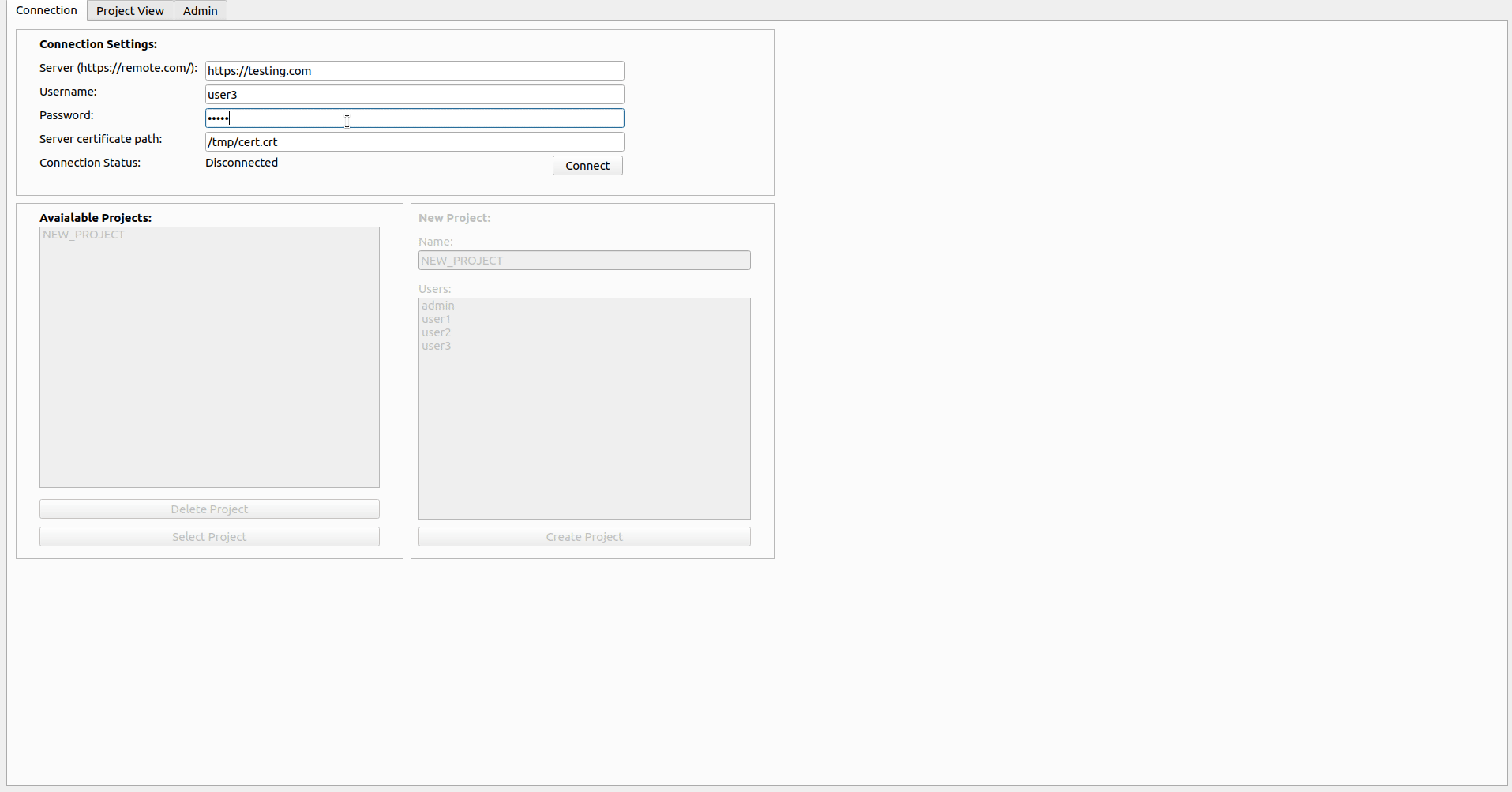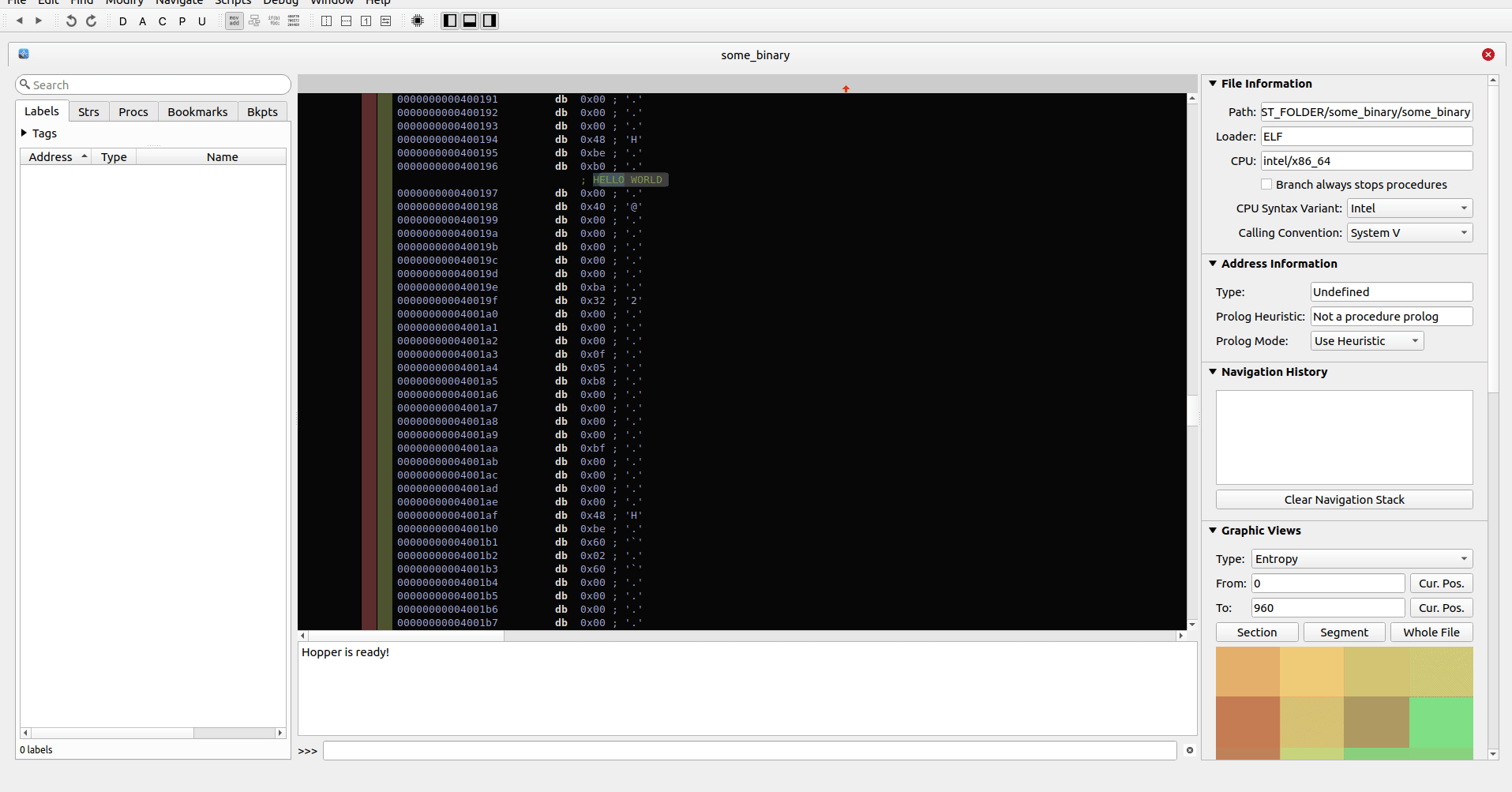
Para crear un proyecto, el usuario primero debe autenticarse en el servidor remoto ingresando la URL, las credenciales y proporcionar un certificado para validar la identidad del servidor. Después de eso, el estado cambiará a Connected y es posible seleccionar o eliminar proyectos existentes o crear un nuevo proyecto simplemente ingresando el nombre (caracteres alfanuméricos y _ solo) y seleccionando a los usuarios que participarán en el proyecto (se puede cambiar más adelante en la pestaña Admin ). Tenga en cuenta que el usuario que está creando el proyecto se agrega automáticamente a la lista de usuarios para que no tenga que seleccionar usted mismo.
Una vez que esté en la pestaña Project View puede crear nuevas carpetas (caracteres alfanuméricos y _ solo, lo siento) y usar arrastrar y soltar para cargar archivos (o carpetas).
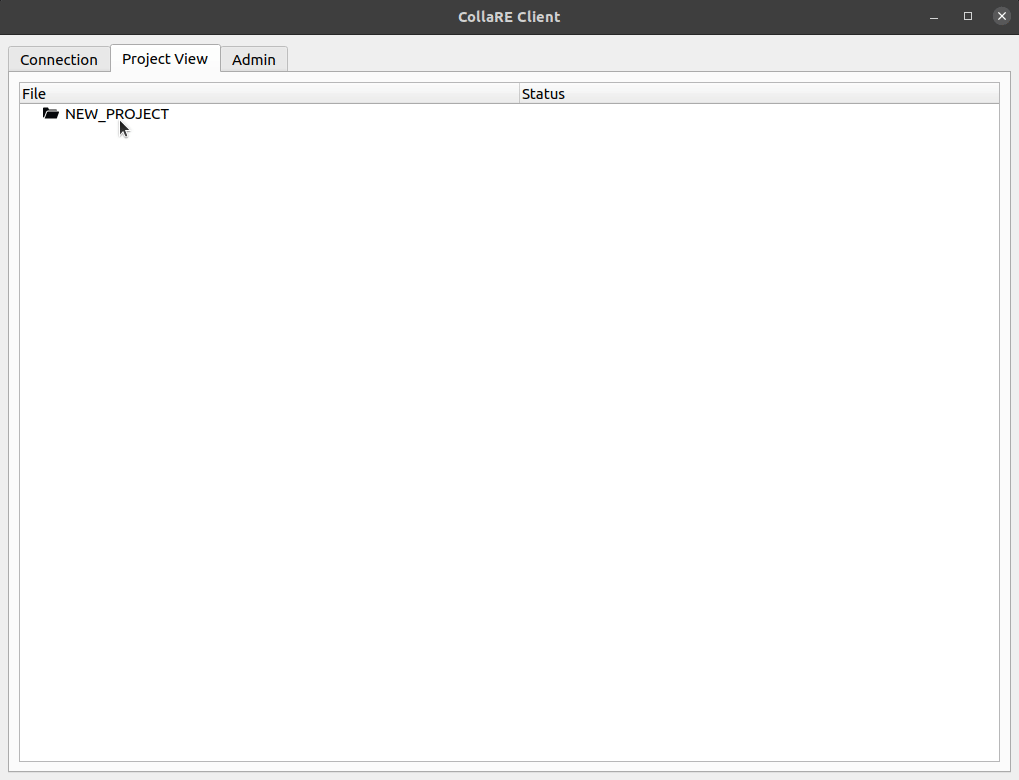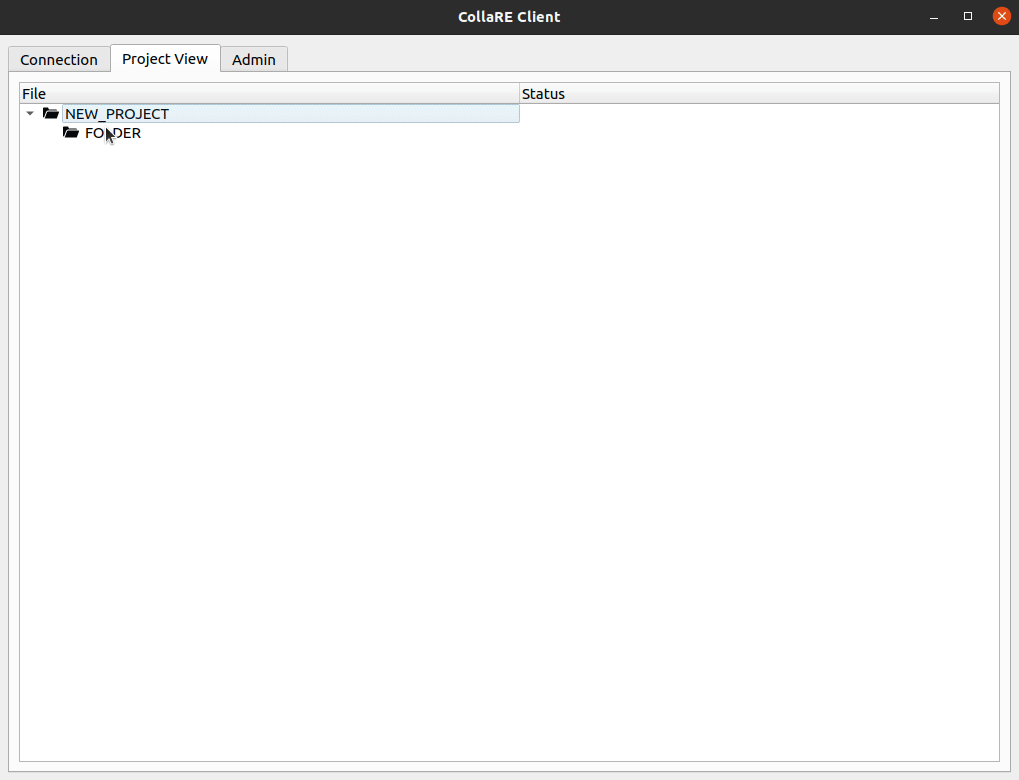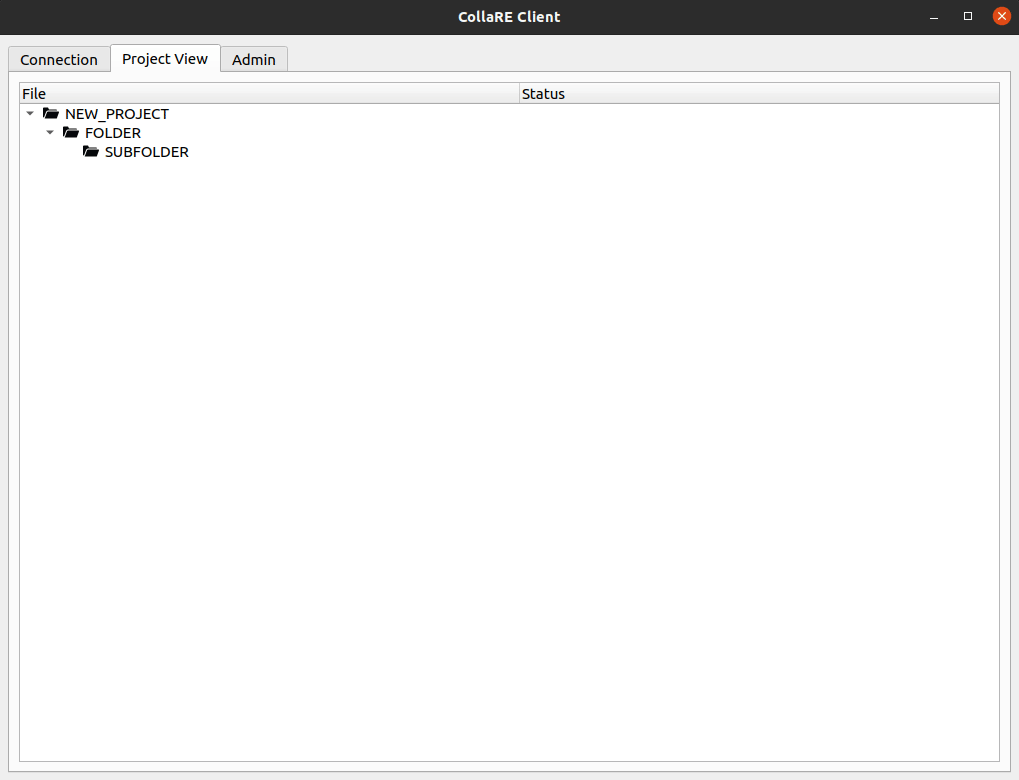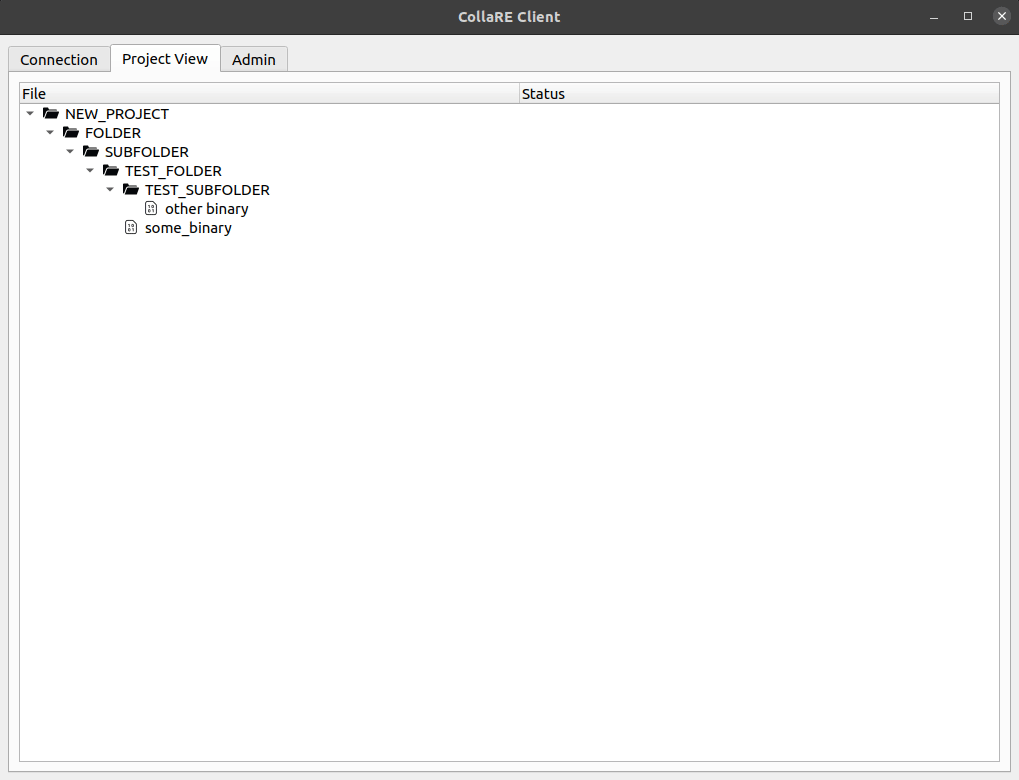
Dado que la herramienta actualmente no tiene complementos o gancos nativos que permitan cargas automáticas cuando se guarde el proyecto, se requiere que el empuje local del archivo DB se active manualmente después de crear las bases de datos deseadas. Esto se puede hacer haciendo clic derecho en el archivo binario cargado y eligiendo la herramienta en la que desea procesar el binario. Puede hacer un análisis básico, pero se recomienda guardar el archivo sin cambiar nada (aparte de agregar rzdb en Cutter y un proceso completamente diferente con Ghidra). No cambie la ruta y el nombre de archivo . Después de hacer esto y cerrar el Disimitador, puede hacer clic derecho en el nombre binario y seleccionar la opción Push Local DBs . Esto cargará la base de datos local y de ahora en adelante cuando desee trabajar con el archivo DB, debe realizar Check-out . Tenga en cuenta que cada binario se puede procesar en todas las herramientas por separado, pero solo puede existir un archivo DB por binario y herramienta.
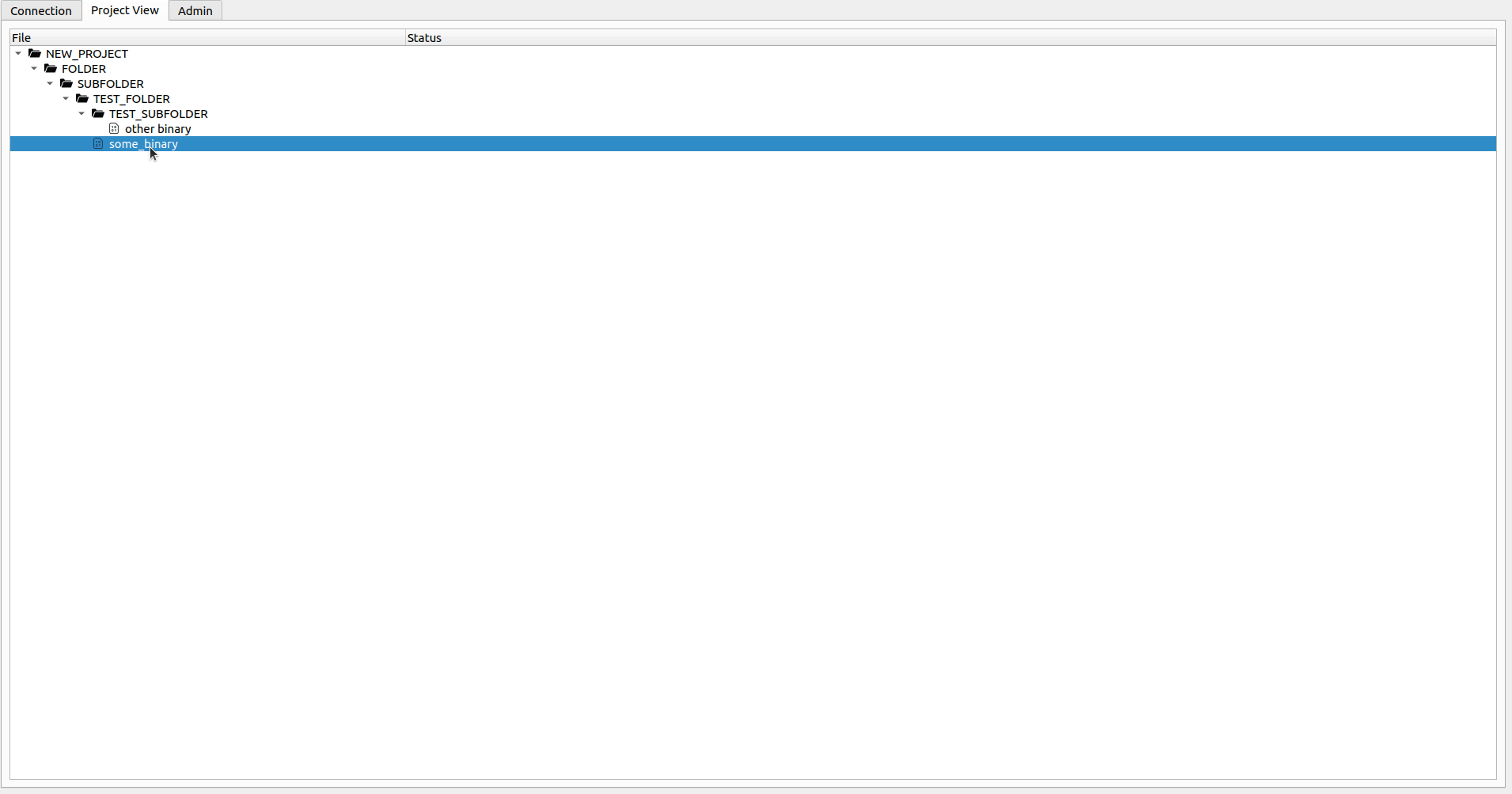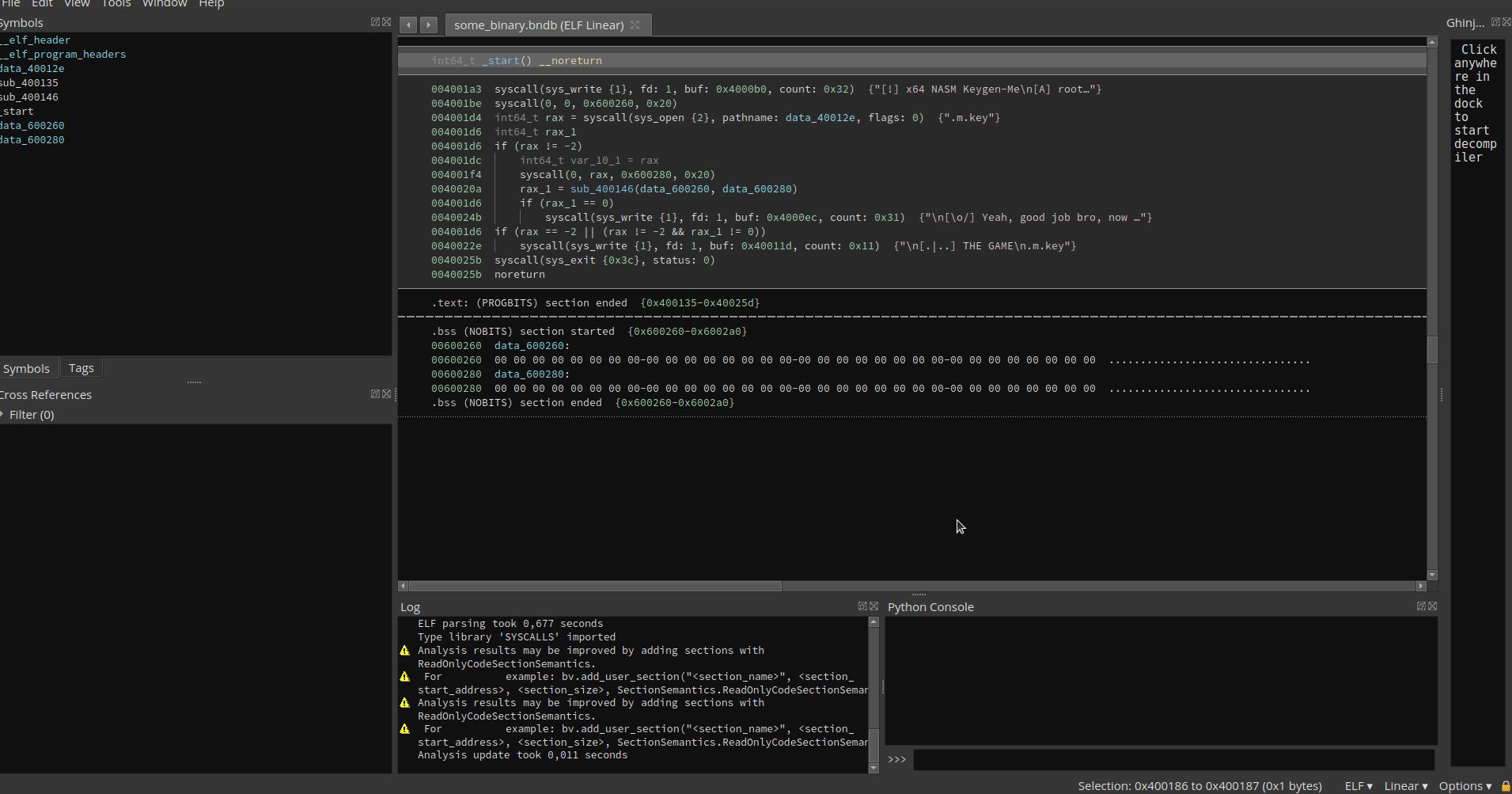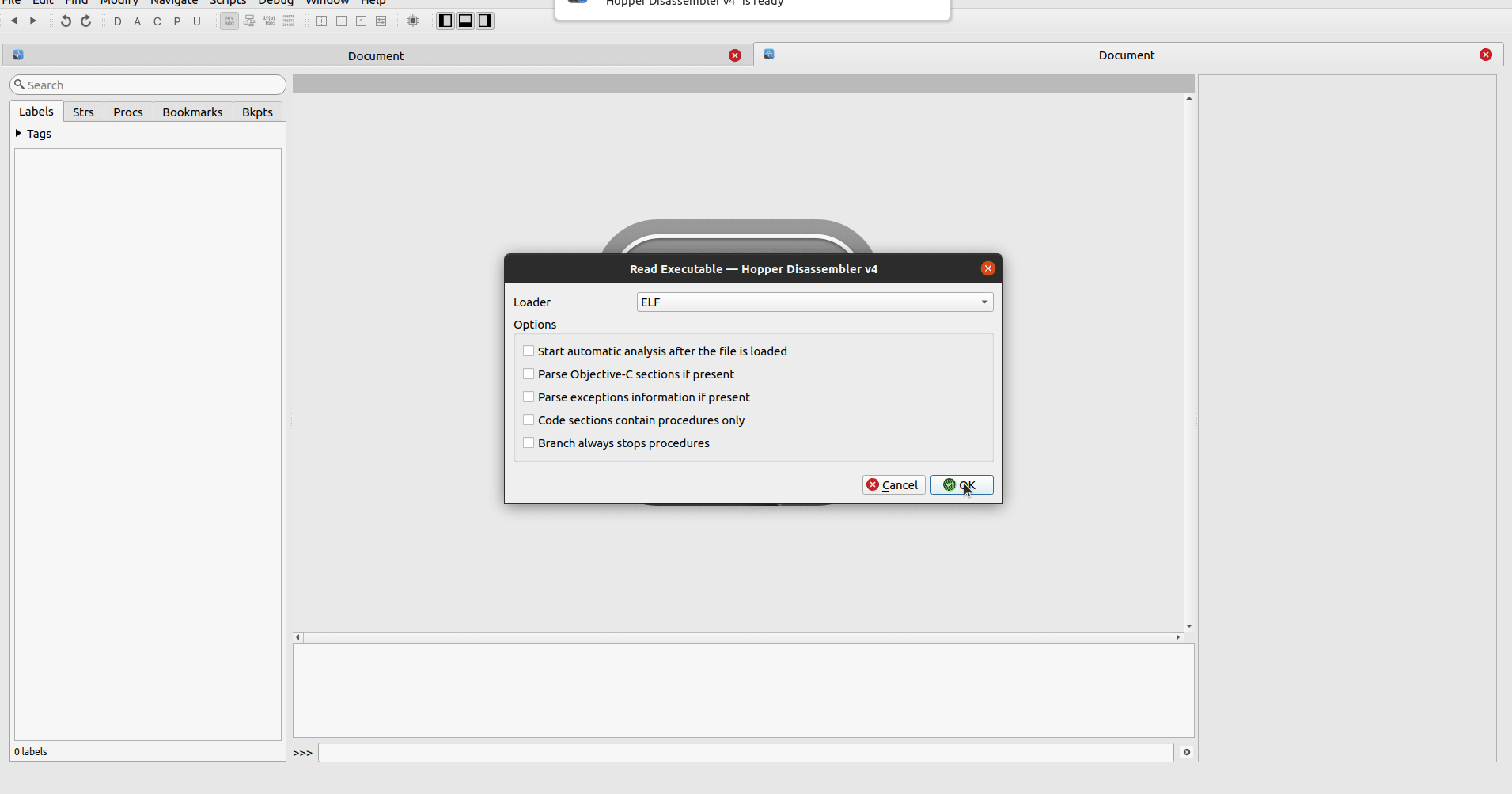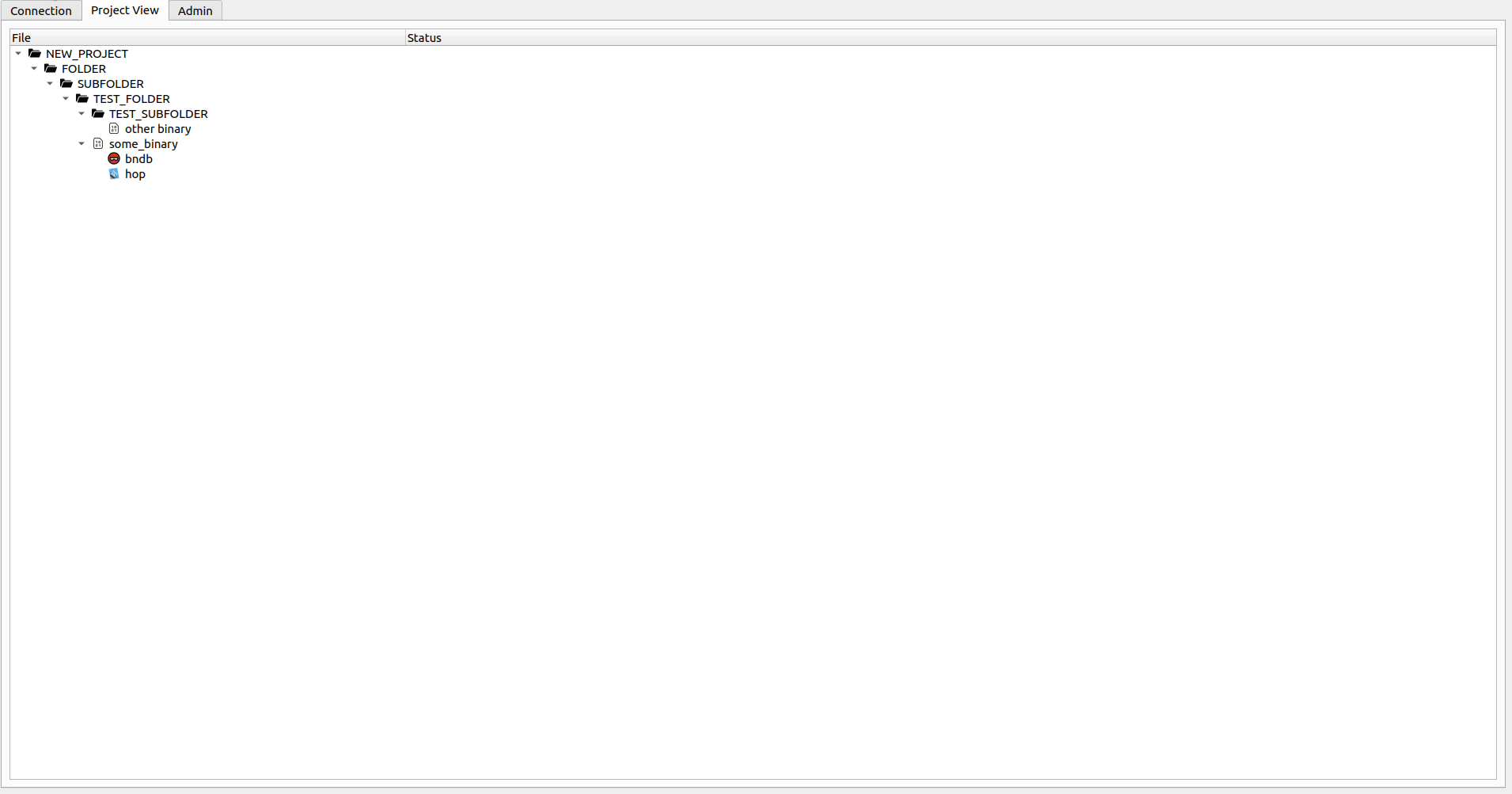
Cuando solo desea inspeccionar el archivo, puede hacer clic con el botón derecho en el archivo DB deseado y seleccione Opción Open File (o simplemente hacer doble clic). Si el archivo se verifica para usted, esto abrirá el archivo local y puede realizar libremente cualquier cambio en el archivo DB. Cuando se haga (o cuando simplemente desea presionar los cambios) puede seleccionar la opción Check-in . Esto cargará los cambios en el servidor y le solicitará si desea mantener el archivo verificado para obtener más cambios. Si desea descartar sus cambios locales, seleccione la opción Undo Check-out en el menú contextual. Esto descartará sus cambios y le permitirá continuar con el archivo desde el servidor. Abrir un archivo sin hacer una operación Check-out primero lo abrirá en un modo de solo lectura falsa (puede hacer cambios en el archivo DB, pero se perderán la próxima vez que salga de salida o abra el archivo).
La herramienta también admite versiones de versiones de DB de manera que cada acción Check-in cuenta como una nueva versión del archivo DB. Se le solicitará que inserte un comentario para la versión que se utiliza para dar más contexto a los cambios que se aplican en esa versión. Entonces es posible abrir o ver las versiones anteriores de los archivos y trabajar en ellos.
La carpeta de complementos dentro de este repositorio contiene complementos para las herramientas compatibles que le permiten compartir comentarios y nombres de funciones entre las herramientas en caso de que trabaje en un binario con múltiples herramientas. Siga las instrucciones de instalación estándar del complemento para la herramienta que le interesa. Cada complemento ofrece una función Import y Export . Cuando planea compartir los datos entre las herramientas, siempre asegúrese de Import datos primero para evitar cambiar el nombre de las funciones que ya renombraron otra persona. Si el complemento viene con algunas capturas, se mencionan en el archivo README del complemento dado. Tenga en cuenta que los complementos están destinados a migrar los datos a otra herramienta en lugar de una colaboración simultánea de varias personas.