CollaRE
v1.4

Collare ist ein Tool für Collaborative Reverse Engineering, mit dem Teams, die mehr als ein Tool während eines Projekts verwenden müssen, um zusammenzuarbeiten, ohne die Dateien an einem separaten Standort zu teilen. Es enthält auch eine sehr einfache Benutzerverwaltung und kann als solche für einen Multi-Project-Server verwendet werden, auf dem verschiedene Teams an verschiedenen Projekten arbeiten. Das Back-End des Tools ist eine einfache Flask app mit nginx , die in Docker ausgeführt wird und mit Dateien und JSON-basierten Manifesten funktioniert, die die relevanten Daten enthalten. Das Front-End ist ein PYQT-basiertes GUI-Tool mit einer einfachen Schnittstelle, mit der die Projektbanken verwaltet und mit den Binärdateien und ihren entsprechenden Reverse Engineering-Datenbanken arbeiten können. Ab sofort unterstützt das Tool Binary Ninja , Cutter (Rizin) , Ghidra , Hopper Dissassembler , IDA , JEB und Android Studio (Decompiled by JADX) . Die Implementierung wird so weit wie möglich aus den inneren Arbeitswerken dieser Tools abstrahiert, um Probleme mit API -Änderungen zu vermeiden, und integriert sich daher nicht direkt in diese Tools in Form eines Plugins (mit Ausnahme von Datenmigrations -Plugins, die unten beschrieben wurden). Die Arbeit basiert nur auf der Verwaltung der Dateien, die von diesen Tools (im wahrsten Sinne des Wortes nur auf den bekannten Dateierweiterungen basierend) und einfacher check-out und check-in Vorgänge im SVN-Stil erstellt wurden.
Nehmen Sie die neueste Binärveröffentlichung aus diesem Repository oder klonen Sie das Repo und führen Sie sudo python3 setup.py install auf Linux aus oder verwenden Sie die Befehlszeile unter Windows und führen Sie python3 setup.py install aus. Auf Linux installiert dies das Tool auf dem PATH und Sie können es einfach mit collare -Befehl ausführen. Unter Windows stellt dies die Datei in die C:Users<USERNAME>AppDataLocalProgramsPython<PYTHON_VERSION>Scriptscollare.exe (je nachdem, wie Sie Python installiert haben).
Für GNOME -basierte Desktop -UIS können Sie die folgenden Desktop -Datei verwenden (Pfade zu Dateien können je nach Version von Collare und Python variieren):
[Desktop Entry]
Type=Application
Encoding=UTF-8
Name=CollaRE
Exec=/usr/local/bin/collare
Icon=/usr/local/lib/python3.8/dist-packages/collare-1.2-py3.8.egg/collare/icons/collare.png
Terminal=false
Um Unterstützung für Cutter zu aktivieren, fügen Sie Ihrem Pfad einen Cutter hinzu (wenn Sie cmd / terminal Cutter öffnen, sollte die Anwendung starten). Wenn Sie Cutter (Rizin) -Projekte sparen, müssen Sie .rzdb manuell anhängen. Entfernen Sie nicht die Erweiterung, die die Datei bereits hat (zum Beispiel exe oder so ).
Um Unterstützung für binäre Ninja zu ermöglichen, fügen Sie Ihrem Weg eine Datei binaryninja hinzu (wenn Sie cmd / terminal schreiben binaryninja sollten Sie die Anwendung starten). Binärer Ninja entfernt standardmäßig Dateierweiterungen. Das Tool enthält jedoch, dass die Originaldateierweiterung nicht manuell zurücklegen muss. Das Speichern der Projekte wie in einem Standardpfad reicht aus, um die lokale bndb -Datenbank erfolgreich voranzutreiben.
Um die Unterstützung für Hopper Disassembler zu ermöglichen, fügen Sie Ihrem Pfad einen Hopper hinzu (wenn Sie cmd / terminal Writing Hopper öffnen, sollte die Anwendung starten). Hopper entfernt standardmäßig Dateierweiterungen. Das Tool enthält jedoch, dass die Originaldateierweiterung nicht manuell zurücklegen muss. Das Speichern der Projekte einfach mit Ctrl+S reicht aus, um die lokale hop -Datenbank erfolgreich voranzutreiben.
Um Unterstützung für JEB zu ermöglichen, fügen Sie Ihrem Pfad eine Datei jeb hinzu (wenn Sie cmd / terminal schreiben, sollte jeb die Anwendung starten). Dies kann durch Umbenennen der Standard -Läufer -Skriptdatei für Ihr Betriebssystem in jeb erfolgen (für Windows wäre dies tatsächlich jeb.bat ).
Um Unterstützung für IDA -Tool zu aktivieren, fügen Sie Ihrem Pfad eine Dateien ida64 und ida hinzu (wenn Sie cmd / terminal schreiben ida64 / ida sollten die Anwendung starten).
Um die Unterstützung dieses Tools zu aktivieren, fügen Sie Ihrem Pfad eine Datei ghidraRun und analyzeHeadless ( .bat for Windows) hinzu (wenn Sie cmd / terminal schreiben, sollte ghidraRun die Anwendung starten). Beachten Sie, dass analyzeHeadless im support im Ghidra -Root -Verzeichnis ist. Stellen Sie also sicher, dass Sie PATH anpassen, um beide Dateien aufzunehmen. Der Prozess der Initialisierung der Datenbank mit Ghidra ist etwas komplizierter, da Ghidra auf keinen Fall die Datei verarbeitet, ohne ein Projekt zu erstellen. Um die Ghidra -Datenbank (als ghdb bezeichnet) zu überschreiten, werden Sie aufgefordert, ein Projekt manuell zu erstellen, wenn die automatische Verarbeitung fehlschlägt (im Grunde, wenn die von Ihnen verarbeitete Datei nicht ELF/PE ist) und dann den Pfad zur gpr -Datei angeben (sorry dafür).
Da APK- und JAR -Dateien während der Reverse Engineering -Bemühungen häufig auftreten, unterstützt das Collare -Tool auch die Arbeit mit diesen Dateienarten. Um diese Tools zu unterstützen, müssen Sie sicherstellen, dass die Dateien android-studio und jadx beide im Pfad sind (wenn Sie cmd / terminal schreiben android-studio / jadx sollten die Anwendung starten). Das JADX -Tool wird verwendet, um die Dekompilierung der JAR/APK -Datei durchzuführen, und das Android Studio wird verwendet, um die resultierenden Dateien zu öffnen. Beachten Sie, dass die Verwendung von Android Studio optional ist, da Sie jedes andere Tool, das Gradle-Projekte unter android-studio -Befehl (z. B. Intellij IDIDE) übernimmt.
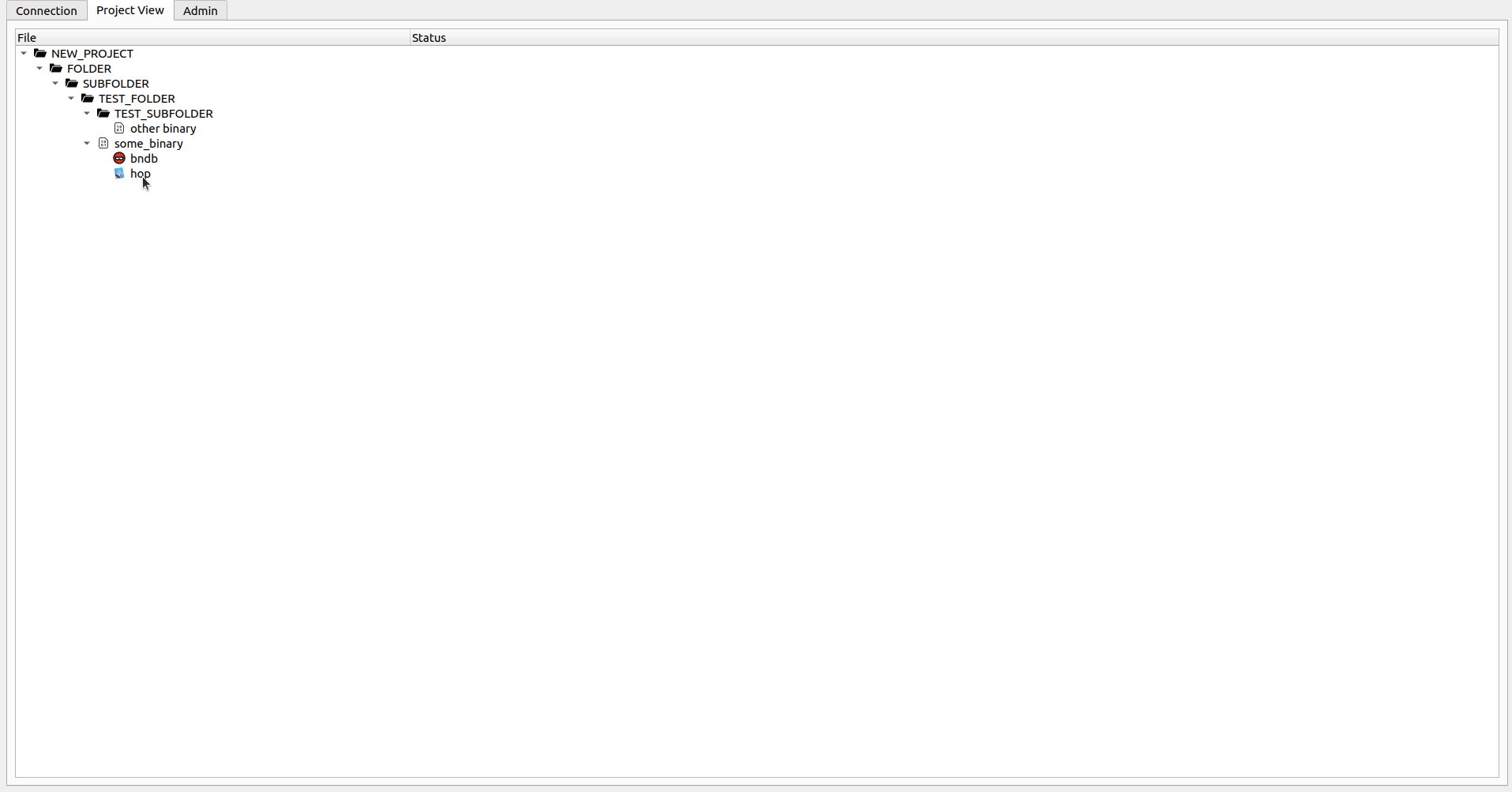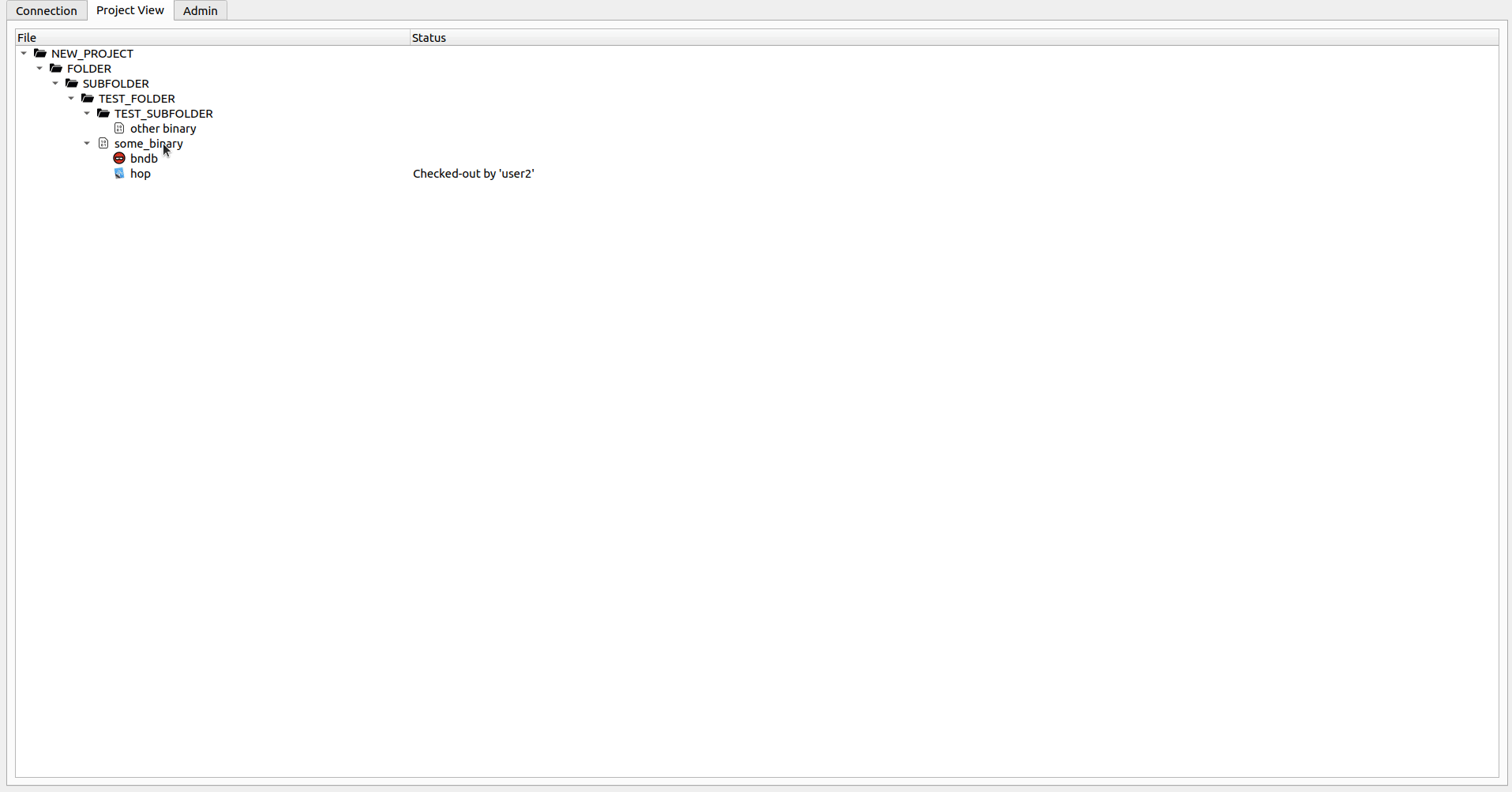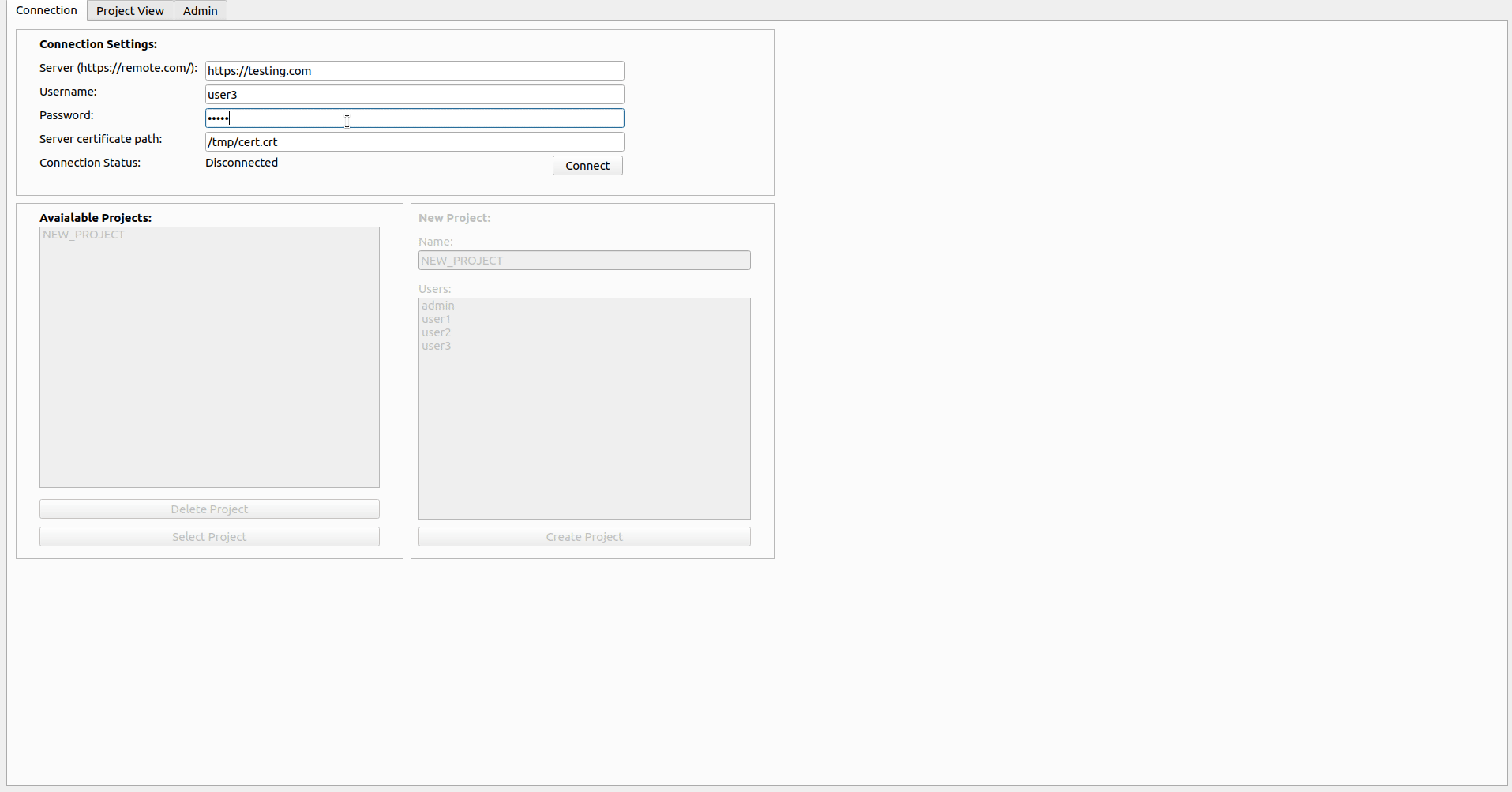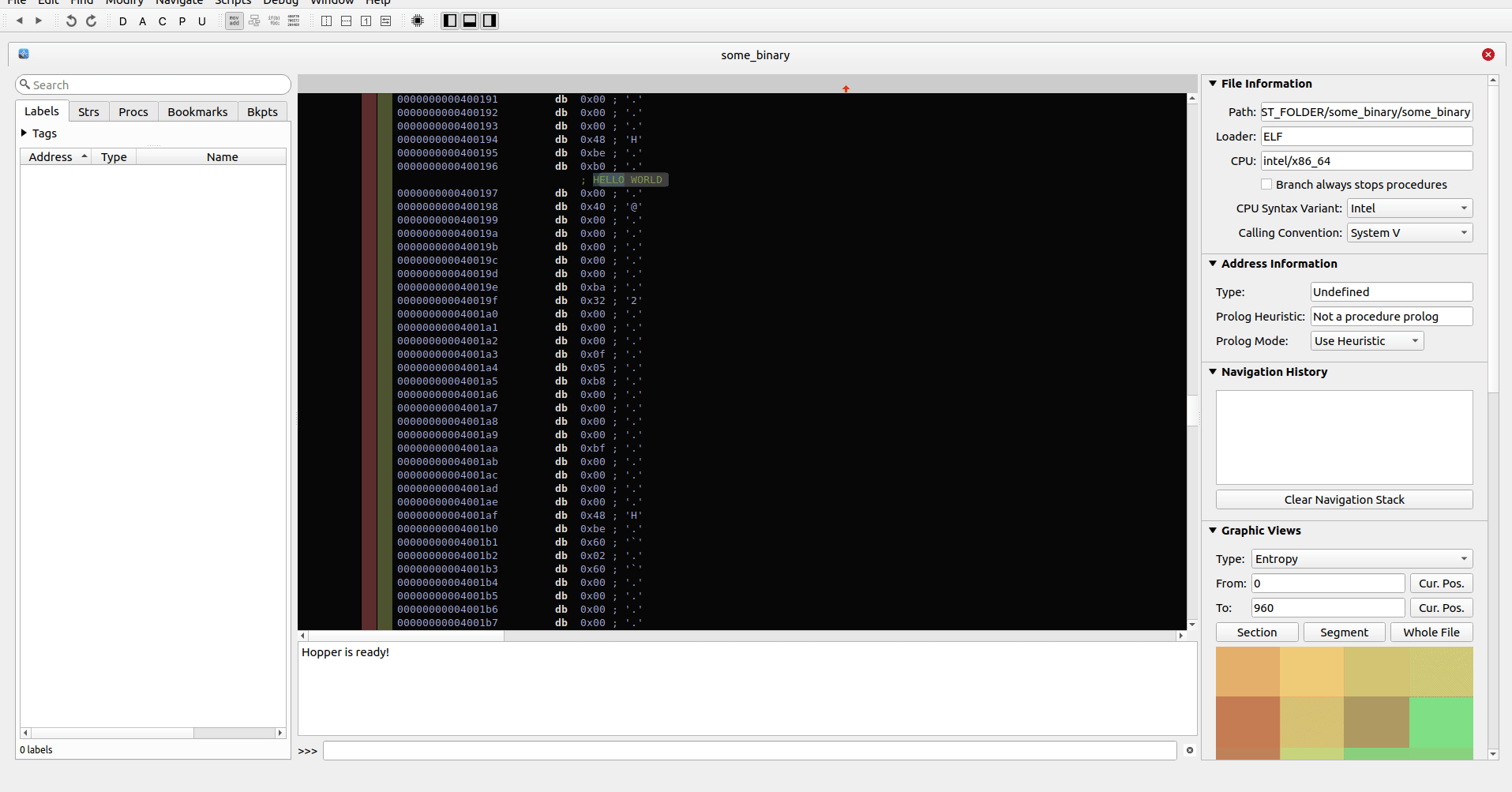
Nach der Bereitstellung der Serverseite, wie in ihrer eigenen ReadMe -Datei erwähnt, müssen die verwendete Zertifikatdatei an alle Benutzer der Anwendung verteilt sowie das Standard admin mit admin verwendet werden, um andere Benutzerkonten (nicht vergessen Sie, das Kennwort des admin zu ändern) über die Registerkarte Admin . Wenn die Benutzer konfiguriert sind, kann jeder seine eigenen Projekte erstellen und mit dem Tool selbst arbeiten.
Um einen Projektbenutzer zu erstellen, muss sich zuerst mit dem Remote -Server die URL, die Anmeldeinformationen eingeben, mit dem Remote -Server authentifizieren und ein Zertifikat zur Validierung der Serveridentität bereitstellen. Danach ändert sich der Status in Connected und es ist möglich, vorhandene Projekte auszuwählen oder zu löschen oder ein neues Projekt zu erstellen, indem einfach der Name (Alphanumeric -Zeichen und _ nur _) eingegeben wird und Benutzer auswählen, die am Projekt teilnehmen (können später auf der Registerkarte Admin geändert werden). Beachten Sie, dass der Benutzer, der das Projekt erstellt, automatisch der Benutzerliste hinzugefügt wird, sodass Sie sich nicht selbst auswählen müssen.
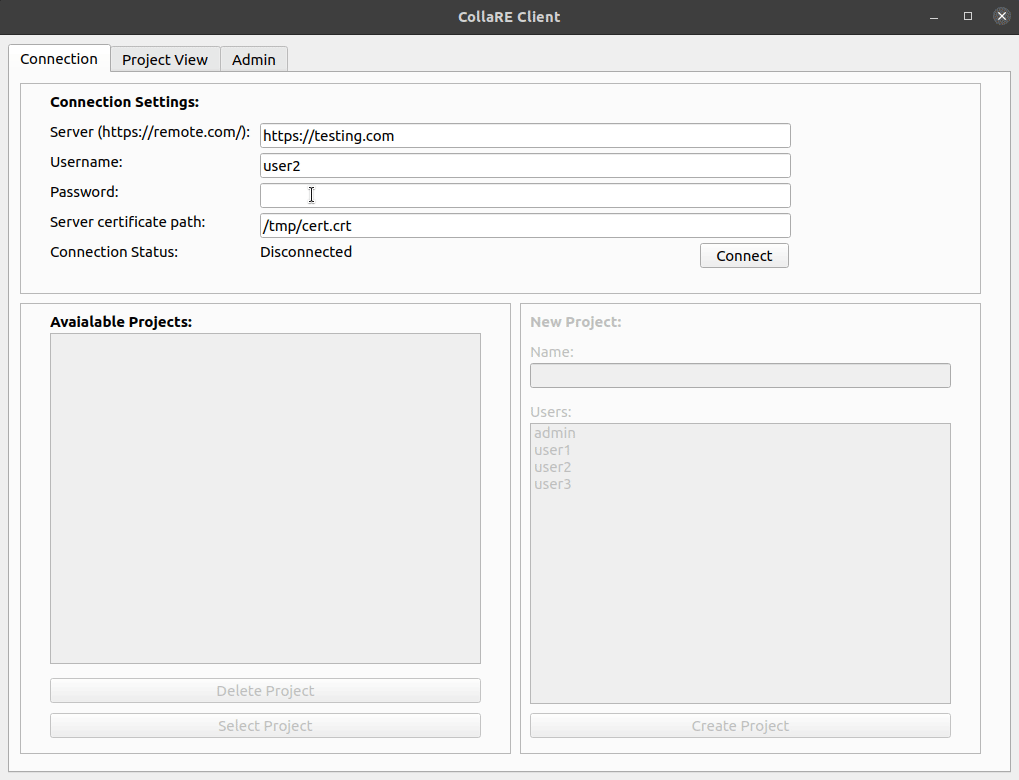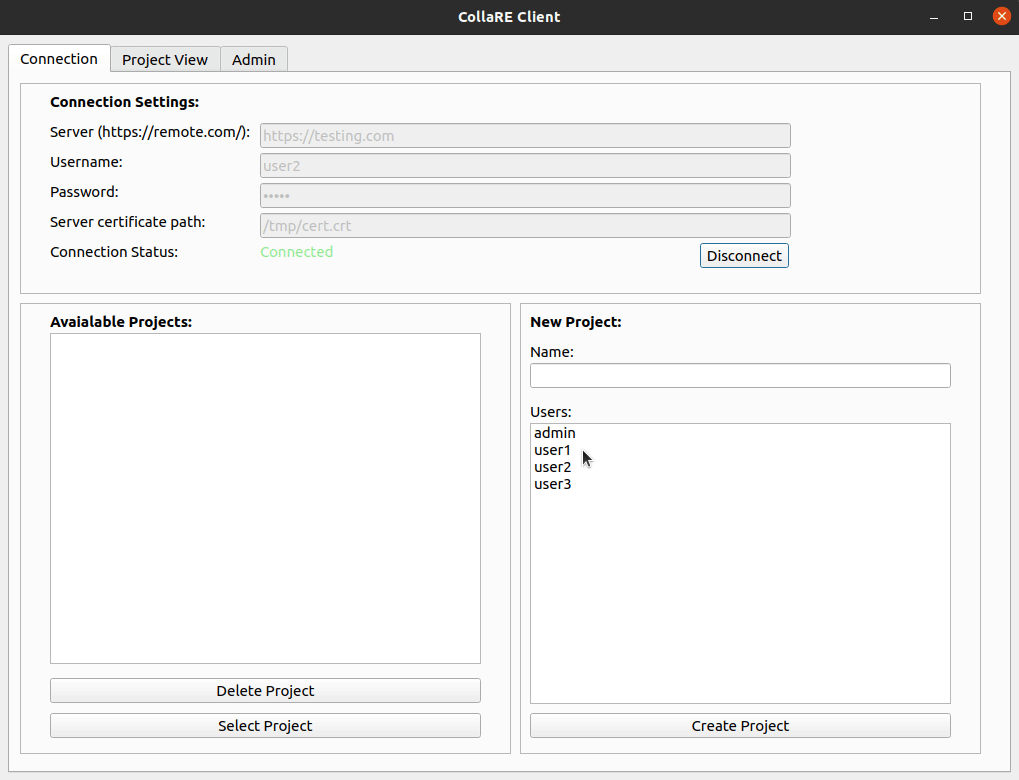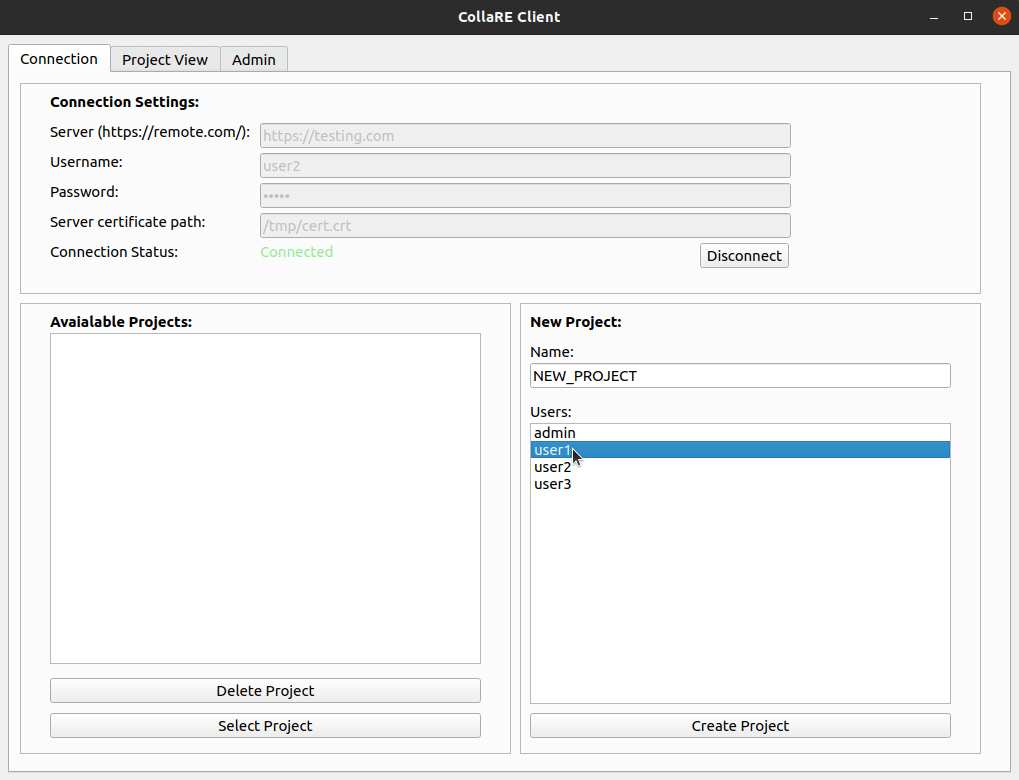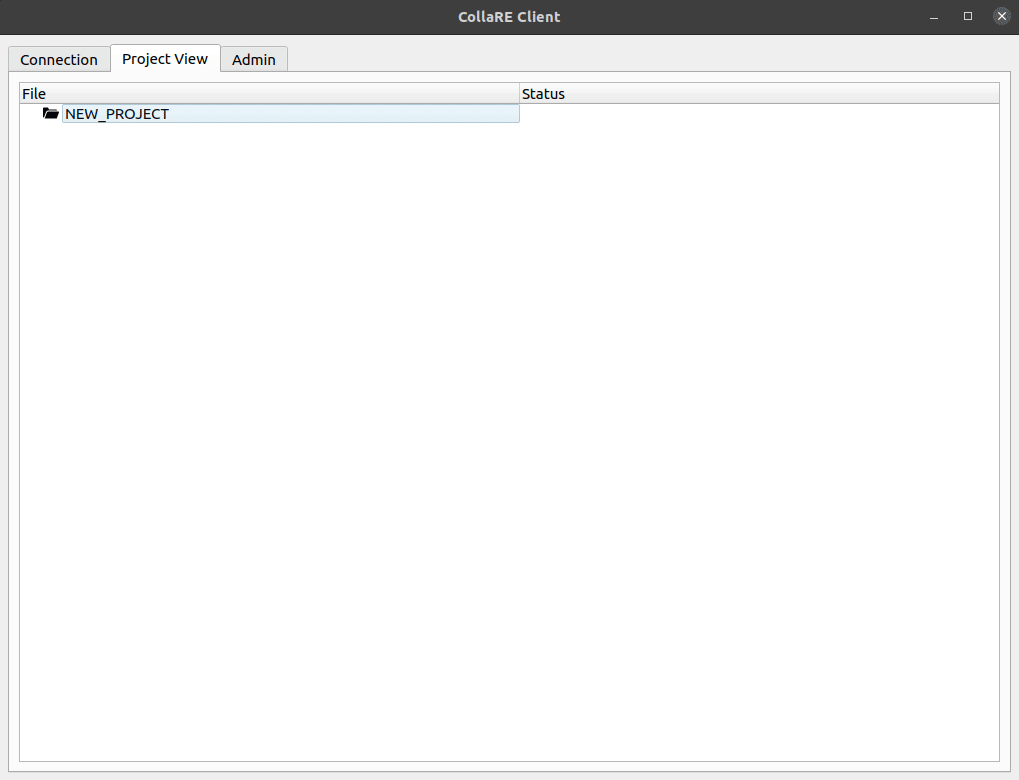
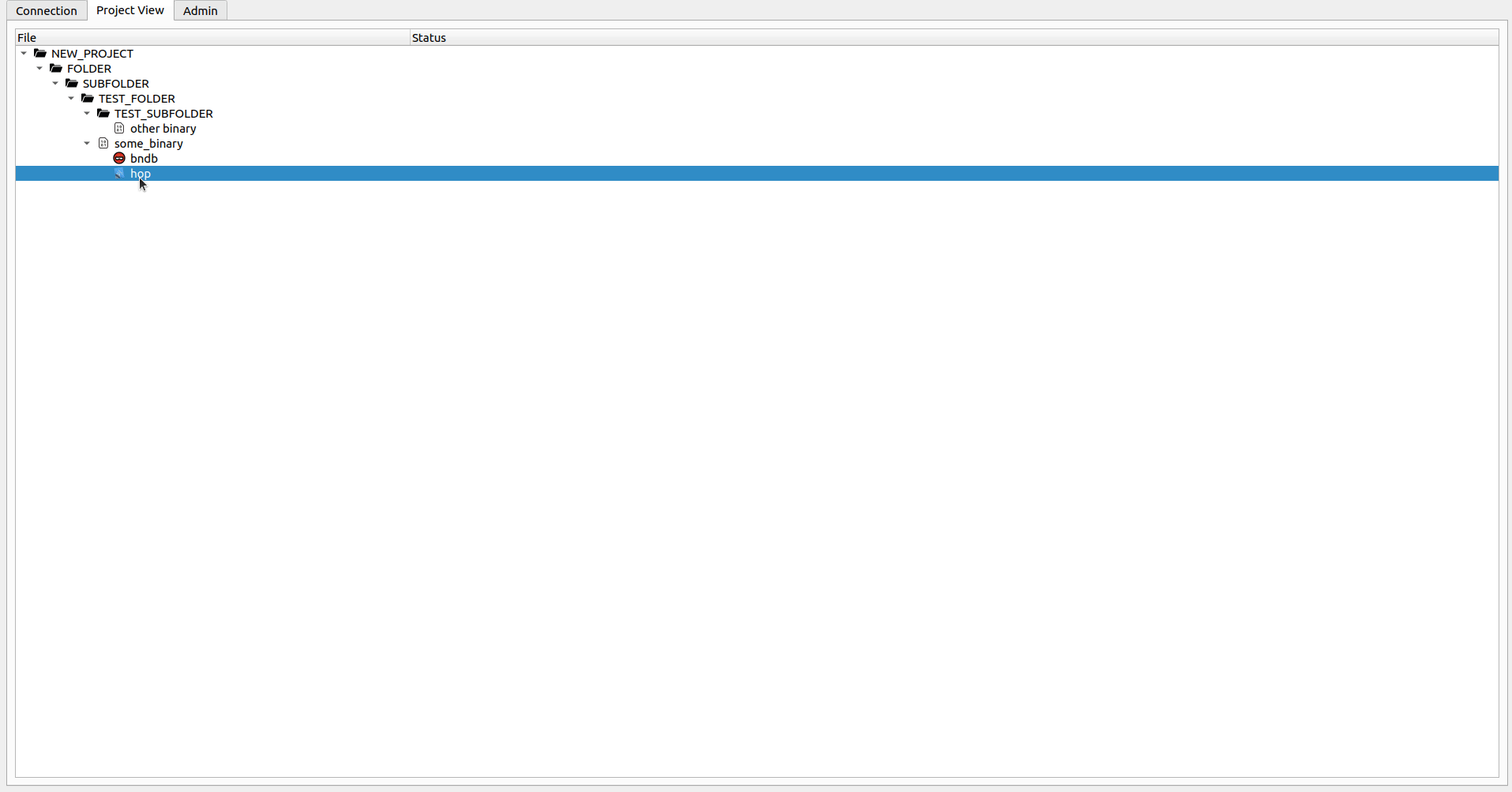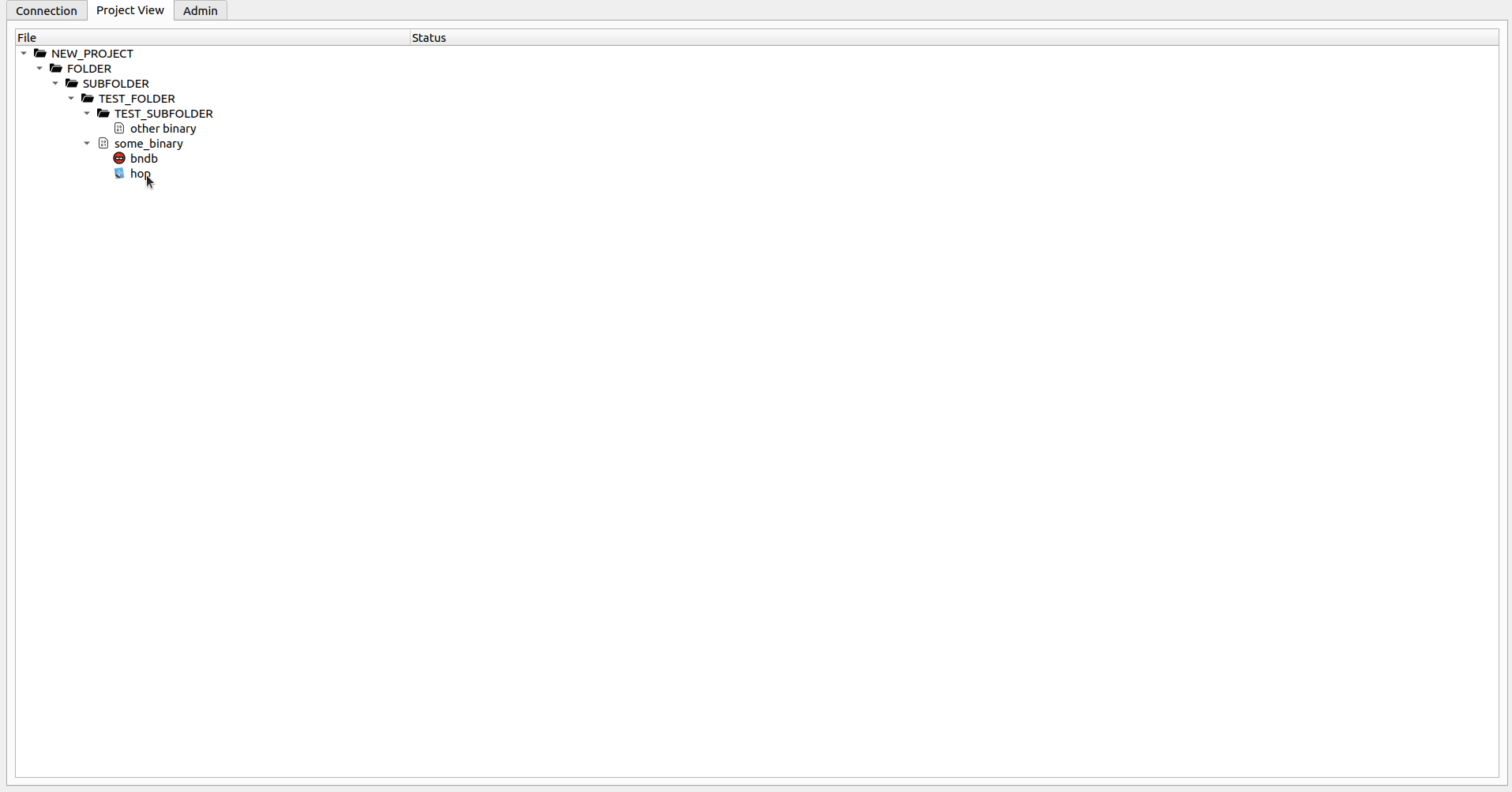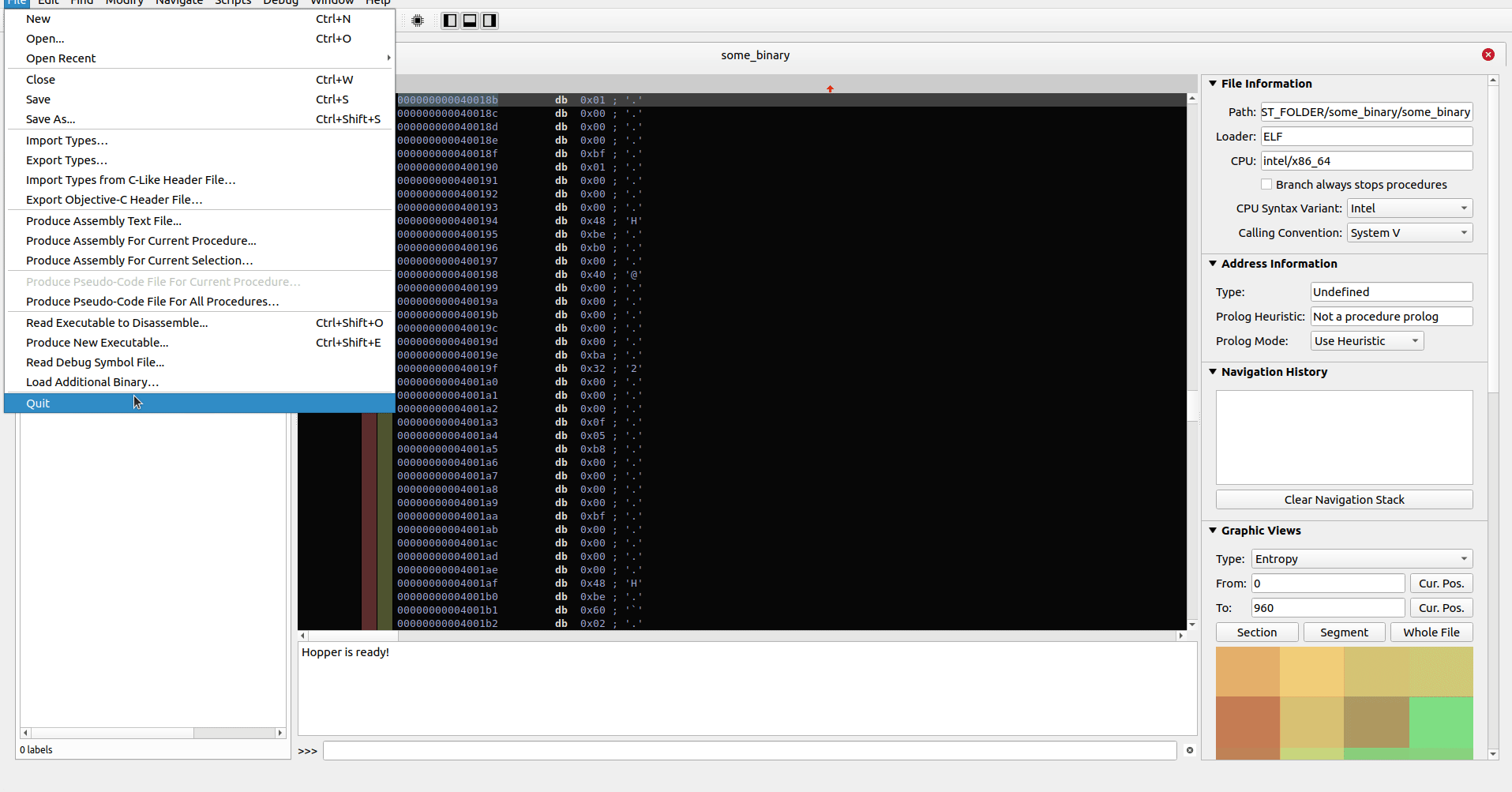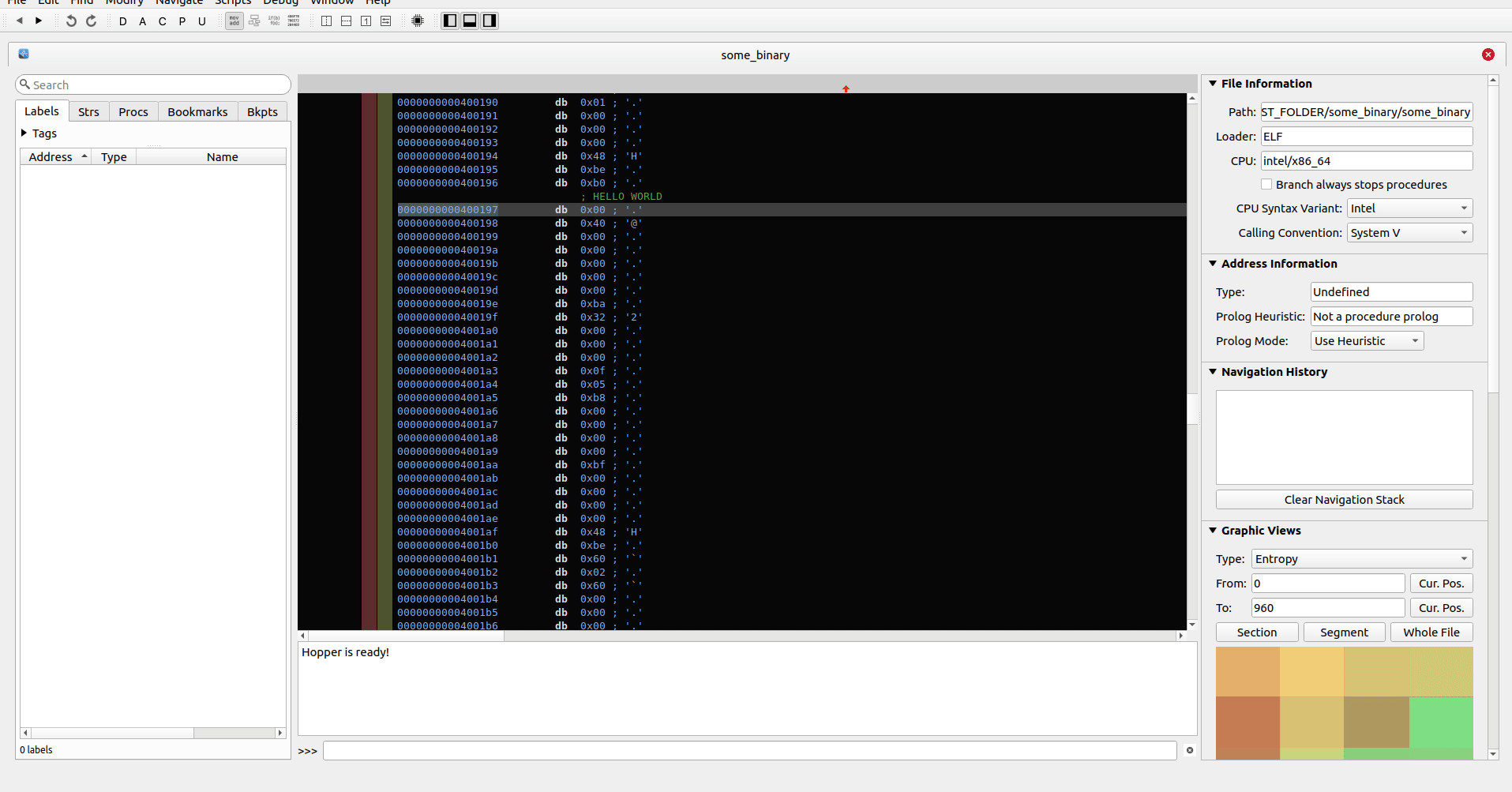
Sobald Sie auf der Registerkarte Project View sind, können Sie neue Ordner (alphanumerische Zeichen und nur _ , sorry) erstellen und Drag & Drop verwenden, um Dateien (oder Ordner) hochzuladen.
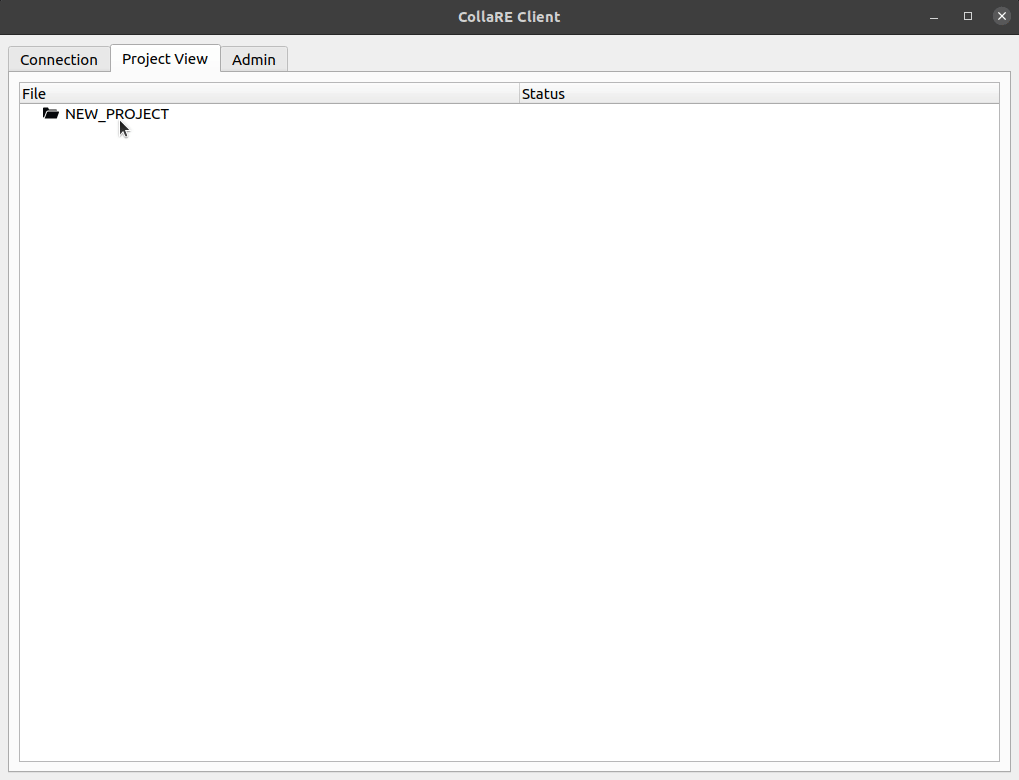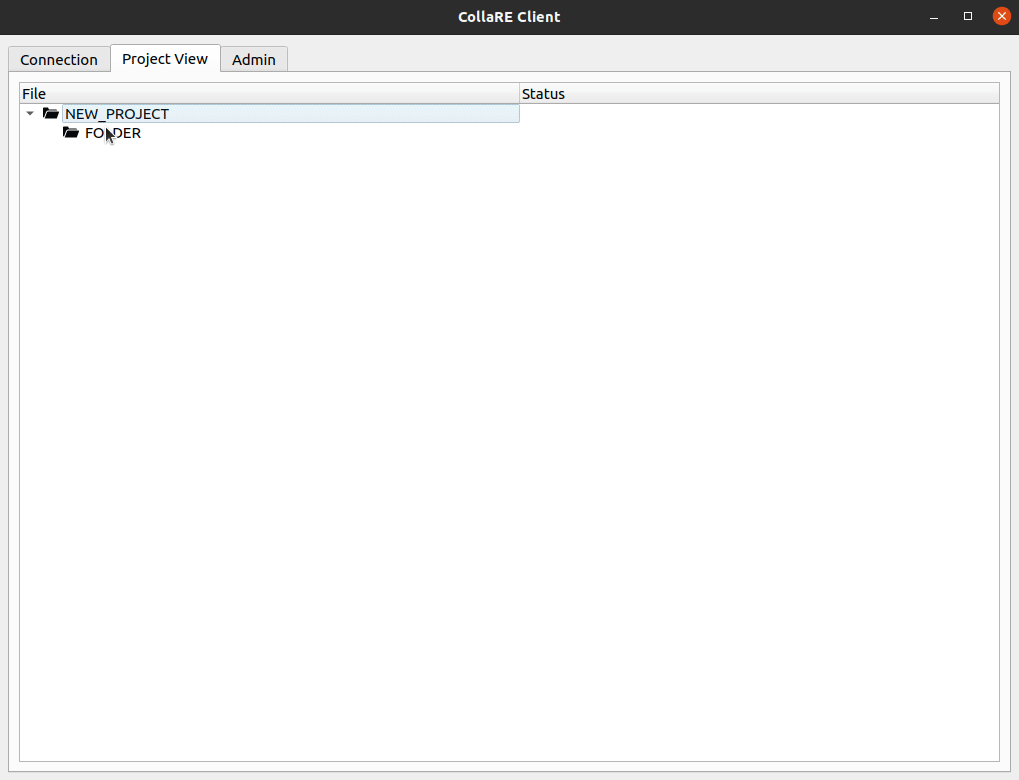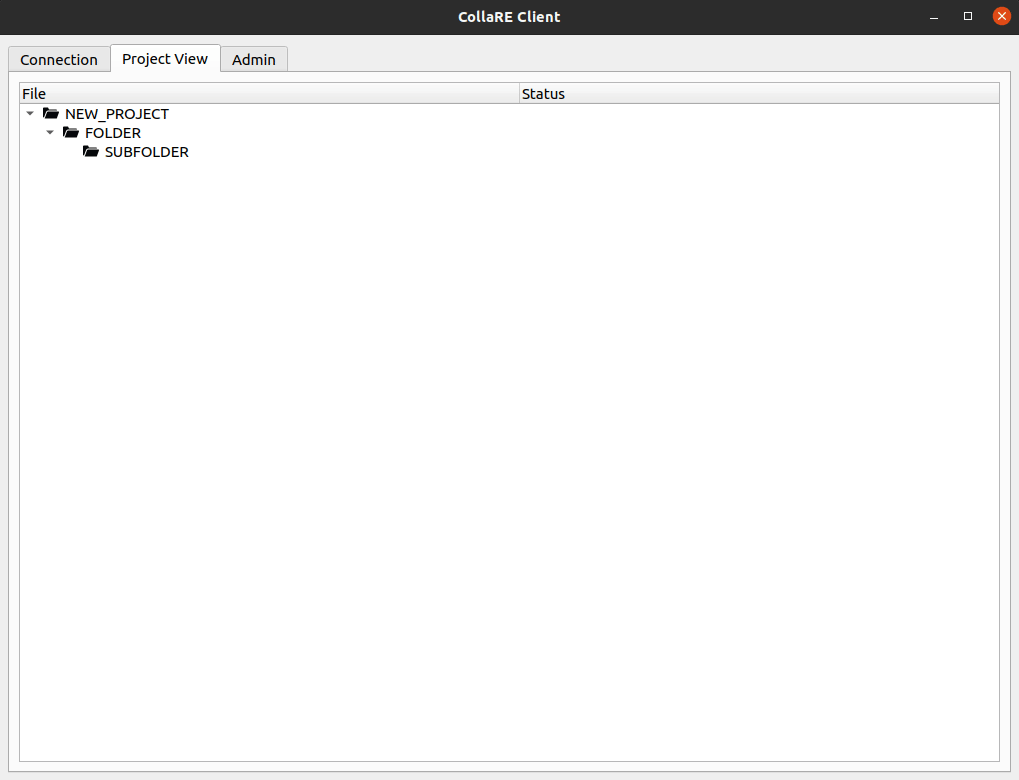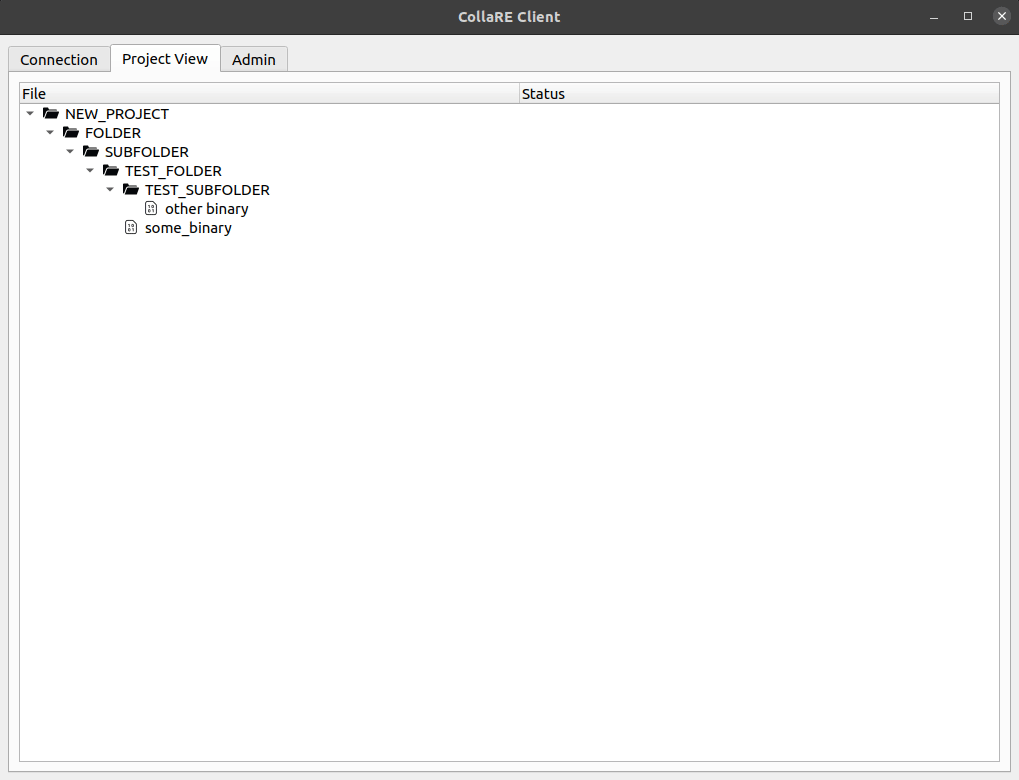
Da das Tool derzeit keine Plugins oder native Hooks enthält, die automatische Uploads beim Speichern des Projekts ermöglichen, ist es erforderlich, dass der lokale DB -Datei -Druck manuell ausgelöst wird, nachdem die gewünschten Datenbanken erstellt werden können. Dies kann durch die rechte Klicken mit der hochgeladenen Binärdatei und die Auswahl des Tools, in dem Sie die Binärdatei verarbeiten möchten, erfolgen. Sie können grundlegende Analysen durchführen. Es wird jedoch dringend empfohlen, die Datei einfach zu speichern, ohne etwas zu ändern (abgesehen von der Anhängen von rzdb in Cutter und völlig unterschiedlichem Prozess mit Ghidra). Ändern Sie den Pfad und den Dateinamen nicht . Nachdem Sie dies tun und den Disassembler schließen können, können Sie mit der rechten Maustaste auf den binären Namen klicken und die Option auswählen, Push Local DBs . Dadurch wird die lokale Datenbank hochgeladen und von nun an, wenn Sie mit der DB-Datei arbeiten möchten, die Sie zum Check-out ausführen möchten. Beachten Sie, dass jede Binärdatei in allen Tools getrennt verarbeitet werden kann, aber nur eine DB -Datei pro Binärdatei und Tool können vorhanden sein.
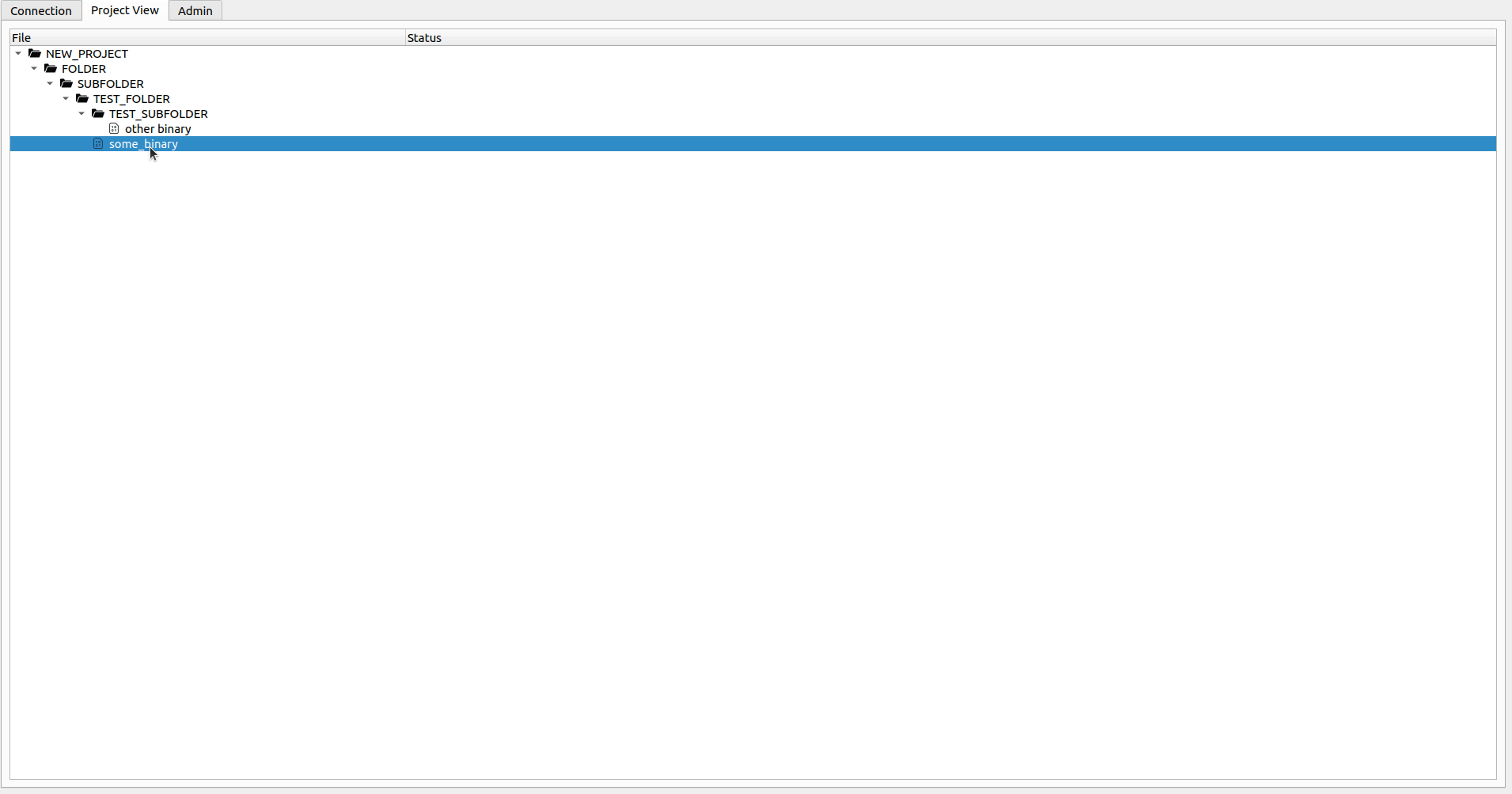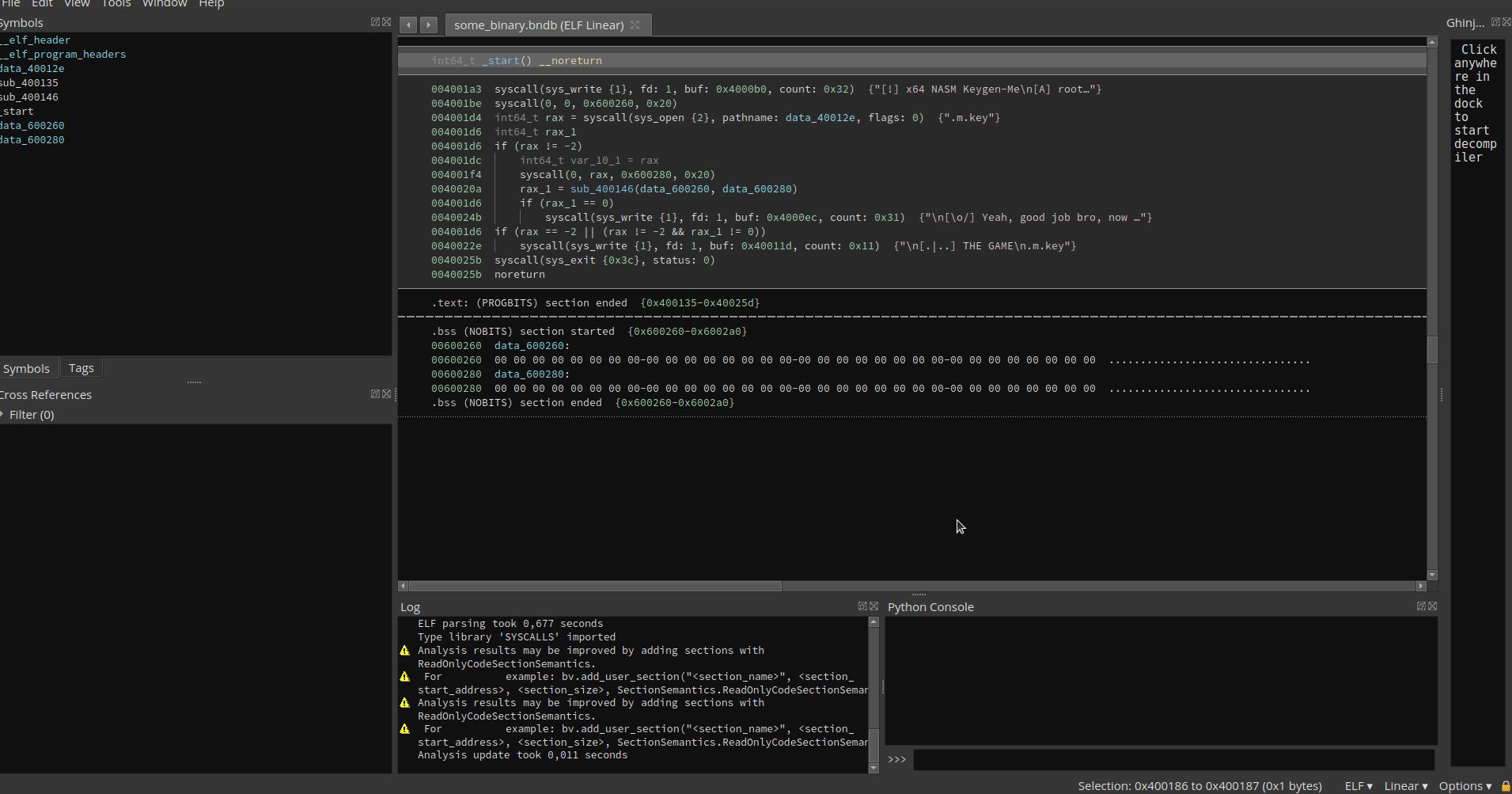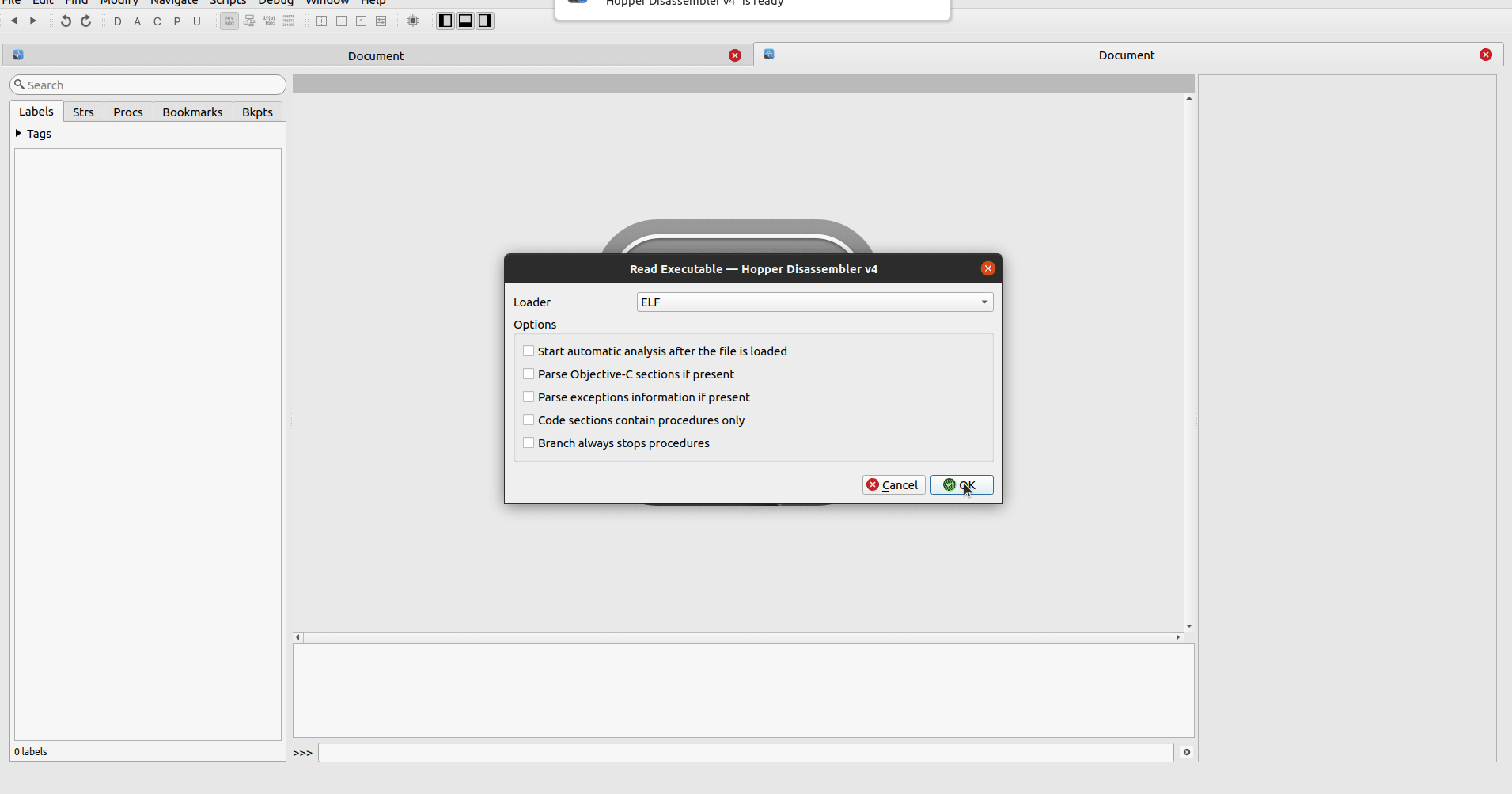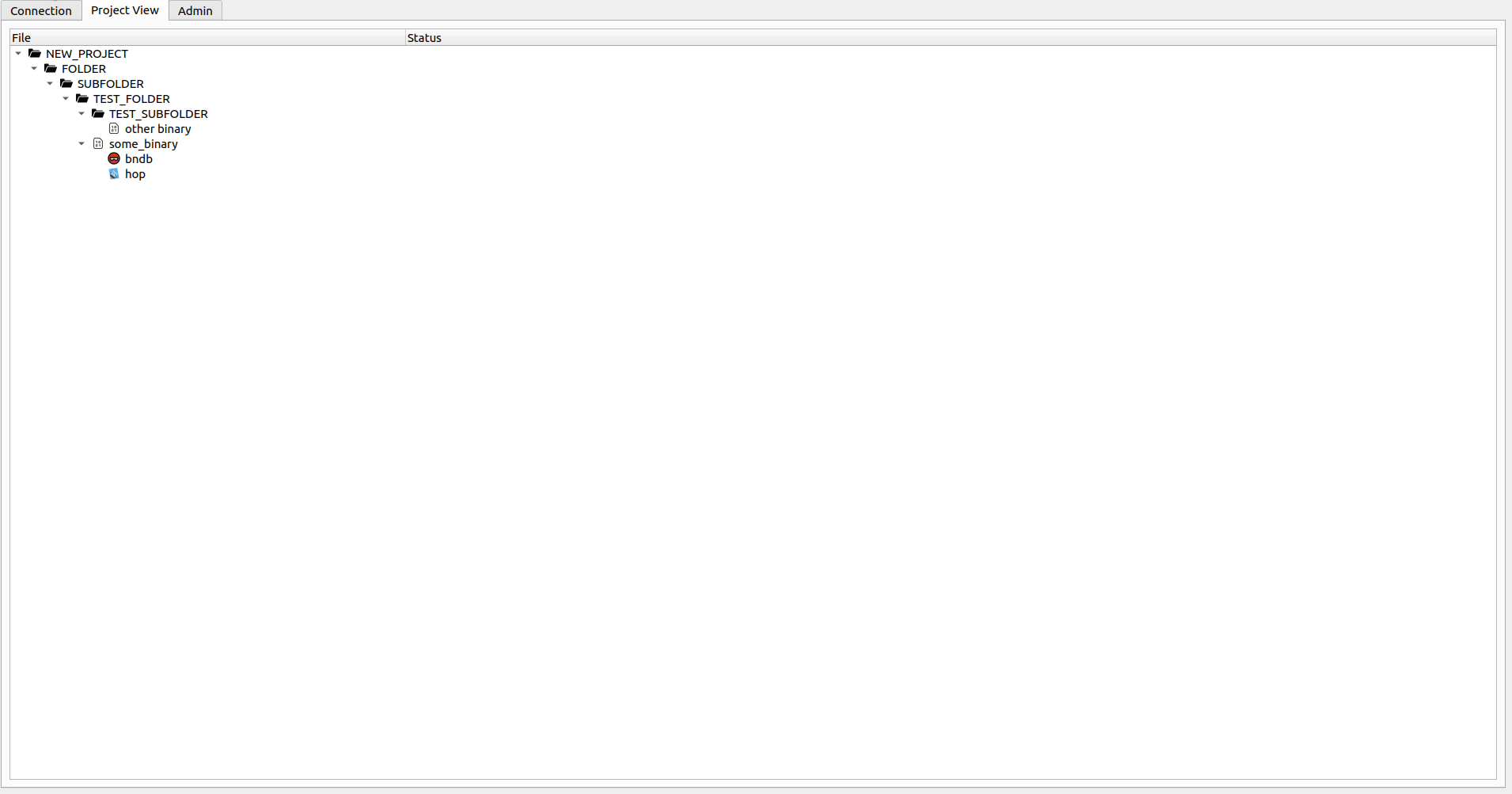
Wenn Sie nur die Datei inspizieren möchten, können Sie mit der rechten Maustaste auf die gewünschte DB-Datei klicken und die Option Open File auswählen (oder nur doppelklicken). Wenn die Datei mit Ihnen überprüft wird, öffnet dies die lokale Datei und Sie können Änderungen an der DB-Datei frei ausführen. Wenn Sie fertig sind (oder wenn Sie einfach die Änderungen drücken möchten) können Sie die Option Check-in auswählen. Dadurch werden die Änderungen an den Server hochgeladen und Sie aufgefordert, ob Sie die Datei nach weiteren Änderungen überprüft halten möchten. Wenn Sie Ihre lokalen Änderungen verwerfen möchten, wählen Sie im Kontextmenü die Option Undo Check-out . Dadurch können Sie Ihre Änderungen verwerfen und Sie ermöglichen, mit der Datei vom Server fortzufahren. Das Öffnen einer Datei ohne Check-out -Operation wird sie in einem gefälschten schreibgeschützten Modus öffnen (Sie können Änderungen an der DB-Datei durchführen. Diese gehen jedoch beim nächsten Mal verloren, wenn Sie die Datei auschecken oder öffnen).
Das Tool unterstützt auch die Versionierung der DB-Dateien so, dass jede Check-in -Aktion als neue Version der DB-Datei gelten. Sie werden aufgefordert, einen Kommentar für die Version einzufügen, mit der die Änderungen, die in dieser Version angewendet werden, mehr Kontext geben. Es ist dann möglich, die vorherigen Versionen der Dateien zu öffnen oder zu überprüfen und daran zu arbeiten.
Der Plugins -Ordner in diesem Repository enthält Plugins für die unterstützten Tools, mit denen Sie Kommentare und Funktionsnamen zwischen den Tools freigeben können, falls Sie an einem Binärer mit mehreren Tools arbeiten. Befolgen Sie die Standardanweisungen für Plugin -Installationen für das Tool, an dem Sie interessiert sind. Jedes Plugin bietet einen Import und eine Export . Wenn Sie vorhaben, die Daten zwischen den Tools zu teilen, stellen Sie immer sicher, dass Sie zuerst Daten Import , um die Umbenennung von Funktionen zu vermeiden, die bereits von jemand anderem umbenannt wurden. Wenn das Plugin mit einigen Fängen ausgestattet ist, werden diese in der Readme -Datei des angegebenen Plugins erwähnt. Beachten Sie, dass die Plugins die Daten eher für eine gleichzeitige Zusammenarbeit mehrerer Personen in ein anderes Tool migrieren sollen.