melgan multi
1.0.0
PyTorch implementation of MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis.
This implementation includes distributed support and uses the LJSpeech dataset.
data/LJSpeech-1.1/wavspython train.py --config=config.json --cps=cp_melganDefault checkpoint directory is cp_melgan
Tensorboard logs will be saved in cp_melgan/logs
python distributed.py --config=config.json --args_str="--cps=cp_melgan"Training code detects all GPUs and sets them automatically.
Current Samples (489K Steps)
Samples
Sample audio can be heard on the tensorboard also.
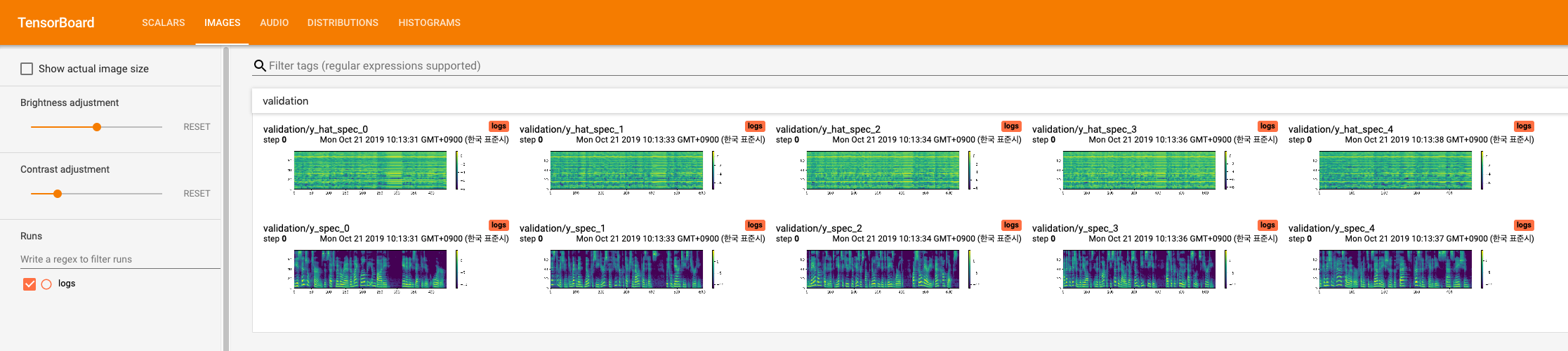
Generated spectrograme can be seen on the tensorboard.
Coming soon..
I will commit a full inference code soon.
I referred to waveglow to implement audio preprocessing.


