Jiagu
1.0.0
Jiagu is trained using large-scale corpus. It will provide common natural language processing functions such as Chinese word segmentation, part-of-speech annotation, naming entity recognition, sentiment analysis, knowledge graph relationship extraction, keyword extraction, text summary, new word discovery, sentiment analysis, text clustering, etc. We have made reference to the advantages and disadvantages of major tools and will give back to everyone.
The functions provided are:
pip installation
pip install -U jiagu If it is slower, you can use Tsinghua's pip source: pip install -U jiagu -i https://pypi.tuna.tsinghua.edu.cn/simple
Source code installation
git clone https://github.com/ownthink/Jiagu
cd Jiagu
python3 setup.py install import jiagu
#jiagu.init() # 可手动初始化,也可以动态初始化
text = '厦门明天会不会下雨'
words = jiagu . seg ( text ) # 分词
print ( words )
pos = jiagu . pos ( words ) # 词性标注
print ( pos )
ner = jiagu . ner ( words ) # 命名实体识别
print ( ner ) import jiagu
text = '汉服和服装、维基图谱'
words = jiagu . seg ( text )
print ( words )
# jiagu.load_userdict('dict/user.dict') # 加载自定义字典,支持字典路径、字典列表形式。
jiagu . load_userdict ([ '汉服和服装' ])
words = jiagu . seg ( text ) # 自定义分词,字典分词模式有效
print ( words )It is only used for testing, you can use pip3 install jiagu==0.1.8, and you can only use the encyclopedia description for testing. The API will be opened later if the results are better.
import jiagu
# 吻别是由张学友演唱的一首歌曲。
# 《盗墓笔记》是2014年欢瑞世纪影视传媒股份有限公司出品的一部网络季播剧,改编自南派三叔所著的同名小说,由郑保瑞和罗永昌联合导演,李易峰、杨洋、唐嫣、刘天佐、张智尧、魏巍等主演。
text = '姚明1980年9月12日出生于上海市徐汇区,祖籍江苏省苏州市吴江区震泽镇,前中国职业篮球运动员,司职中锋,现任中职联公司董事长兼总经理。'
knowledge = jiagu . knowledge ( text )
print ( knowledge )Training data: https://github.com/ownthink/KnowledgeGraphData
import jiagu
text = '''
该研究主持者之一、波士顿大学地球与环境科学系博士陈池(音)表示,“尽管中国和印度国土面积仅占全球陆地的9%,但两国为这一绿化过程贡献超过三分之一。考虑到人口过多的国家一般存在对土地过度利用的问题,这个发现令人吃惊。”
NASA埃姆斯研究中心的科学家拉玛·内曼尼(Rama Nemani)说,“这一长期数据能让我们深入分析地表绿化背后的影响因素。我们一开始以为,植被增加是由于更多二氧化碳排放,导致气候更加温暖、潮湿,适宜生长。”
“MODIS的数据让我们能在非常小的尺度上理解这一现象,我们发现人类活动也作出了贡献。”
NASA文章介绍,在中国为全球绿化进程做出的贡献中,有42%来源于植树造林工程,对于减少土壤侵蚀、空气污染与气候变化发挥了作用。
据观察者网过往报道,2017年我国全国共完成造林736.2万公顷、森林抚育830.2万公顷。其中,天然林资源保护工程完成造林26万公顷,退耕还林工程完成造林91.2万公顷。京津风沙源治理工程完成造林18.5万公顷。三北及长江流域等重点防护林体系工程完成造林99.1万公顷。完成国家储备林建设任务68万公顷。
'''
keywords = jiagu . keywords ( text , 5 ) # 关键词
print ( keywords ) import jiagu
fin = open ( 'input.txt' , 'r' )
text = fin . read ()
fin . close ()
summarize = jiagu . summarize ( text , 3 ) # 摘要
print ( summarize ) import jiagu
jiagu . findword ( 'input.txt' , 'output.txt' ) # 根据文本,利用信息熵做新词发现。 import jiagu
text = '很讨厌还是个懒鬼'
sentiment = jiagu . sentiment ( text )
print ( sentiment ) import jiagu
docs = [
"百度深度学习中文情感分析工具Senta试用及在线测试" ,
"情感分析是自然语言处理里面一个热门话题" ,
"AI Challenger 2018 文本挖掘类竞赛相关解决方案及代码汇总" ,
"深度学习实践:从零开始做电影评论文本情感分析" ,
"BERT相关论文、文章和代码资源汇总" ,
"将不同长度的句子用BERT预训练模型编码,映射到一个固定长度的向量上" ,
"自然语言处理工具包spaCy介绍" ,
"现在可以快速测试一下spaCy的相关功能,我们以英文数据为例,spaCy目前主要支持英文和德文"
]
cluster = jiagu . text_cluster ( docs )
print ( cluster )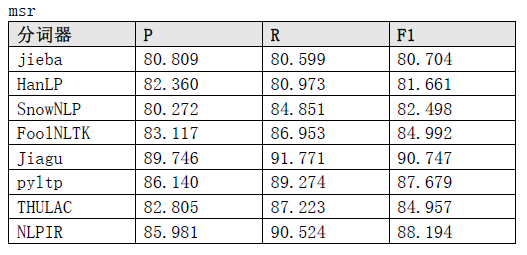
n 普通名词
nt 时间名词
nd 方位名词
nl 处所名词
nh 人名
nhf 姓
nhs 名
ns 地名
nn 族名
ni 机构名
nz 其他专名
v 动词
vd 趋向动词
vl 联系动词
vu 能愿动词
a 形容词
f 区别词
m 数词
q 量词
d 副词
r 代词
p 介词
c 连词
u 助词
e 叹词
o 拟声词
i 习用语
j 缩略语
h 前接成分
k 后接成分
g 语素字
x 非语素字
w 标点符号
ws 非汉字字符串
wu 其他未知的符号
B-PER、I-PER 人名
B-LOC、I-LOC 地名
B-ORG、I-ORG 机构名
人工智能qq群1:90780053(满)
人工智能qq群2:956936481(满)
人工智能qq群3:1160292084(满)
人工智能qq群4:1019825236(满)
人工智能qq群5:535614287
知识图谱qq群1:55152968
知识图谱qq群2:740104333(满)
知识图谱qq群3:586457987(满)
知识图谱qq群4:858829119
微信群可联系作者微信:MrYener,作者邮箱联系方式:[email protected]
Donate to the author (your encouragement is the author’s greatest motivation for open source!!!): Donate to thank you



