KnowledgeVIS
v0.1.0
Vergleichen Sie visuell LLM-Aufforderungen der Fülle, um erlernte Vorurteile und Assoziationen aufzudecken!
????

Große Sprachmodelle (LLMs) wie Bert und GPT-3 haben erhebliche Verbesserungen der Leistung bei natürlichen Sprachaufgaben verzeichnet, sodass sie Menschen helfen können, Fragen zu beantworten, Aufsätze zu generieren, lange Artikel zusammenzufassen und vieles mehr. Es ist jedoch eine offene Herausforderung , zu verstehen, was diese Modelle gelernt haben und warum sie arbeiten . Für Forscher und Ingenieure für natürliche Sprachverarbeitung (NLP), die LLMs zunehmend als "Black Boxen" für die Erstellung von Text trainieren und einsetzen, untersuchen, wie sich das Lernen während des Trainings in nachgelagerten Aufgaben manifestiert, um die Modellentwicklung zu verbessern. zB durch die Flucht schädlicher Stereotypen .
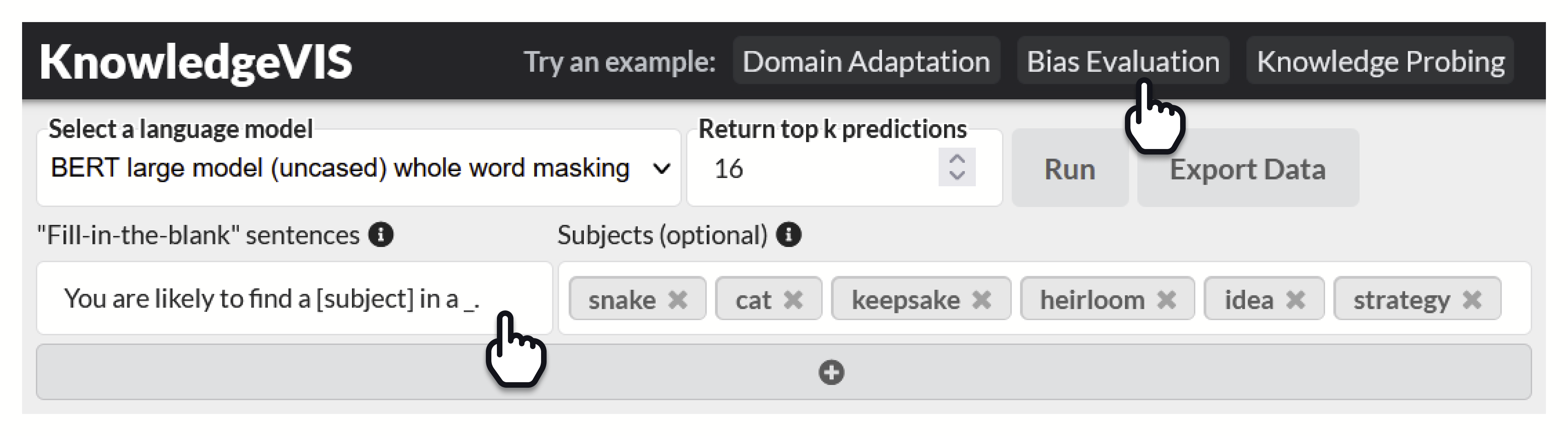
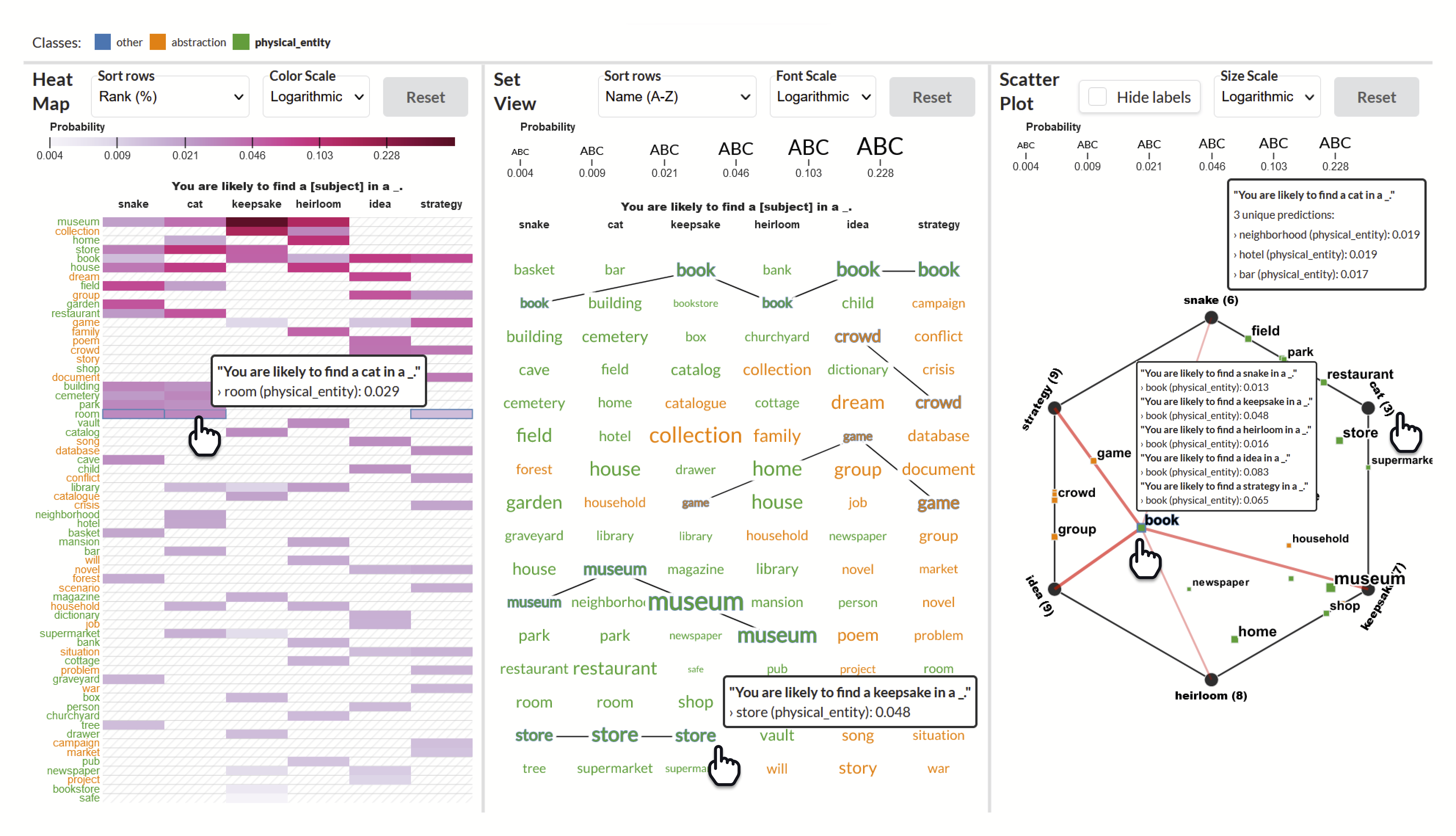
Knowledgevis ist ein visuelles Analytics-System des Menschen zum Vergleich von Aufforderungen an die Fülle, um Assoziationen aus erlernten Textdarstellungen aufzudecken. Knowledge Visvis hilft Entwicklern, effektive Sätze von Eingabeaufforderungen zu erstellen, mehrere Arten von Beziehungen zwischen Wörtern zu untersuchen, für verschiedene Lernverbände zu testen und Erkenntnisse in mehreren Vorhersagen für jedes BerT-basierte Sprachmodell zu finden.
Zusammengenommen helfen diese Visualisierungen dem Benutzer, die Wahrscheinlichkeit und Einzigartigkeit einzelner Vorhersagen zu identifizieren, Vorhersagen zwischen Eingabeaufforderungen zu vergleichen und Muster und Beziehungen zwischen Vorhersagen über alle Eingabeaufforderungen hinweg zusammenzufassen.
Dieser Code begleitet das Forschungsarbeit:
Knowledgevis: Sprachmodelle interpretieren, indem sie die Eingabeaufforderungen vergleicht
Adam Coscia, Alex Endert
IEEE -Transaktionen zu Visualisierung und Computergrafik (TVCG), 2023 (zu erscheinen)
| Papier |

Sehen Sie sich das Demo -Video für ein vollständiges Tutorial hier an: https://youtu.be/hbx4rsumr_i
Eine Live -Demo finden Sie unter: https://adamcoscia.com/papers/knowledgevis/demo/
? Sie können unsere Visualisierungen in nur wenigen einfachen Schritten auf Ihren eigenen LLMs testen!
v3.9.x (neueste Version)git clone [email protected]:AdamCoscia/KnowledgeVIS.git
# use --depth if you don't want to download the whole commit history
git clone --depth 1 [email protected]:AdamCoscia/KnowledgeVIS.gitNavigieren Sie zum Schnittstellenordner:
cd interfacepy -3.9 -m http.serverpython3.9 -m http.serverNavigieren Sie zu Localhost: 8000. Sie sollten sehen, wie Knowledgevis in Ihrem Browser läuft :)
Navigieren Sie zum Serverordner:
cd serverErstellen Sie eine virtuelle Umgebung:
# Start a virtual environment
py -3.9 -m venv venv
# Activate the virtual environment
. v env S cripts a ctivate # Start a virtual environment
python3.9 -m venv venv
# Activate the virtual environment
source venv/bin/activateAbhängigkeiten installieren:
python -m pip install -r requirements.txt Installieren Sie Pytorch v2.0.x (Anweisungen)
Pytorch ist separat installiert, da einige Systeme CUDA unterstützen können, was einen anderen Installationsprozess erfordert und das Tool erheblich beschleunigen kann.
Führen Sie dann den Server aus:
python main.pyUnter der Leitung von Adam Coscia ist Knowledge Visualisierungsexperten im menschlichen Zentrum und Interaktionsdesign von Georgia Tech eine Zusammenarbeit zwischen Visualisierungsexperten. Knowledgevis wird von Adam Coscia und Alex Endert erstellt.
Um mehr über Knowledgevis zu erfahren, lesen Sie bitte unser Forschungspapier (um in IEEE TVCG zu erscheinen).
@article { Coscia:2023:KnowledgeVIS ,
author = { Coscia, Adam and Endert, Alex } ,
journal = { IEEE Transactions on Visualization and Computer Graphics } ,
title = { KnowledgeVIS: Interpreting Language Models by Comparing Fill-in-the-Blank Prompts } ,
year = { 2023 } ,
volume = { } ,
number = { } ,
pages = { 1-13 } ,
doi = { 10.1109/TVCG.2023.3346713 }
}Die Software ist unter der MIT -Lizenz verfügbar.
Wenn Sie Fragen haben, können Sie ein Problem öffnen oder sich an Adam Coscia wenden.


