JournalGPT
1.0.0
Willkommen im JournalGPT, einer leistungsstarken, multi-seitigen Stromanwendung, die die Funktionen mehrerer hochmodernen Technologien nutzt, um die Art und Weise zu revolutionieren, wie Benutzer Journaleinträge schreiben, Fragen zu ihren Zeitschriften stellen und interaktiv Journaleinträge erstellen.
Das ultimative Ziel dieser Anwendung ist es, als Selbstverbesserungsjournal zu dienen, mit dem Benutzer schwächende Gedankenmuster, Schwächen, Aufschubmuster usw. erkennen und die erforderlichen Ressourcen zur Verbesserung des allgemeinen Wohlbefindens bereitstellen können.
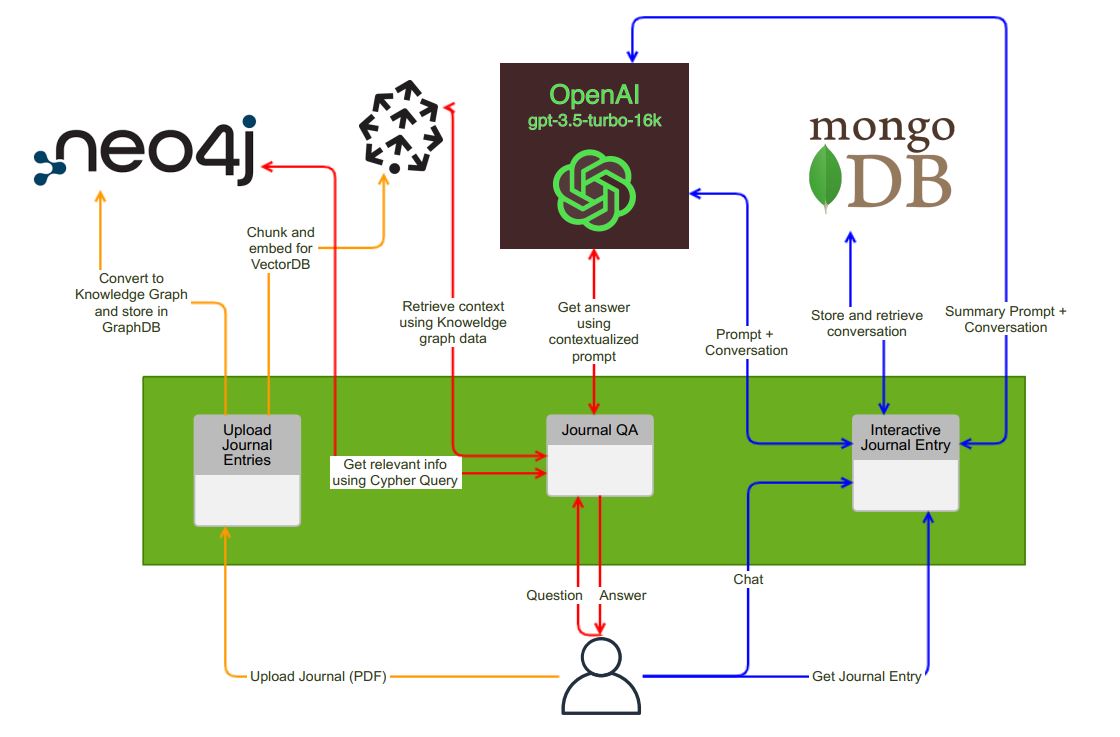
Der Journaleintragsassistent besteht aus drei verschiedenen Seiten, die jeweils einzigartige Funktionen bieten:
Auf der ersten Seite können Benutzer ihr Journal im PDF -Format hochladen. Beim Upload führt die Anwendung die folgenden Aufgaben aus:
Erstellung von Wissensgraphen : Das hochgeladene Dokument wird verarbeitet und in ein strukturiertes Wissensgraphen umgewandelt. Diese Grafik wird dann in einer NEO4J -Datenbank für ein effizientes Abrufen und Analyse gespeichert.
Text -Chunking und Einbettungen : Das Dokument ist geknackt und in Einbettungen umgewandelt. Diese Einbettungen werden in einer Vektordatenbank, insbesondere Pinecone, gespeichert. Dies ermöglicht eine leistungsstarke Suche und Abrufen relevanter Informationen.
Auf der zweiten Seite können Benutzer Fragen zum Inhalt ihres hochgeladenen Journals stellen. Die Anwendung enthält die folgenden Funktionen:
Kontextextraktion : Das System identifiziert die relevanten Kontextwörter im NEO4J -Wissensgraphen, um die Abfrage des Benutzers besser zu verstehen.
Vektor -Datenbankabfrage : Die identifizierten Kontextwörter werden für eine effiziente Vektorsuche an Pinecone gesendet. Dieser Schritt ruft den notwendigen Kontext für die Beantwortung der Frage des Benutzers ab.
Antworten auf LLM-Betrieben : Der abgerufene Kontext wird einem großen Sprachmodell (in diesem Fall OpenAI GPT-3.5) zusammen mit einer geeigneten Eingabeaufforderung zur Verfügung gestellt. Dies stellt sicher, dass die Anwendung genaue und aussagekräftige Antworten auf die Fragen des Benutzers liefert.
Auf der dritten Seite können Benutzer interaktiv Journaleinträge mit Unterstützung eines KI -Sprachmodells erstellen. Der Prozess ist wie folgt:
Interaktives Journaling : Benutzer tippen ihre Tagebucheinträge an, und das KI -Sprachmodell führt ein Gespräch und stellt nachdenkliche Fragen zu ihrem Tag. Dies hilft Benutzern, ihre Gedanken zu sammeln und ein umfassenderes Tagebuch zu generieren.
MongoDB -Speicher : Alle Interaktionen zwischen dem Benutzer und dem KI -Modell werden in einer MongoDB -Atlas -NoSQL -Datenbank gespeichert, wodurch ein Datensatz der Konversation erstellt wird.
Journaleintrag Generierung : Sobald der Benutzer seinen Eintrag beendet hat, kann er auf "Journaleintrag generieren" klicken. Das KI -Modell wird mit relevanten Informationen und einem geeigneten Titel aufgefordert und gibt dem Benutzer einen vollständigen Journaleintrag zurück. Optional können Benutzer es im DOCX -Format herunterladen.
.env.example -Datei hinzu..env.example -Datei hinzu..env.example -Datei hinzu..env.example hinzu.cp .env.example .env
docker build -t journal-gpt .
docker run -d --env-file .env -p 8501:8501 journal-gpt

