unordered_dense
v4.5.0
Eine schnelle und dicht gespeicherte Hashmap und Hashset basierend auf Robin-Hood-Rückwärtsschichtdeletion für C ++ 17 und später.
Die Klassen ankerl::unordered_dense::map und ankerl::unordered_dense::set sind (fast) ein Drop-In-Ersatz von std::unordered_map und std::unordered_set . Obwohl sie nicht als starke Iterator- / Referenzstabilitätsgarantie haben, sind sie in der Regel viel schneller.
Zusätzlich gibt es ankerl::unordered_dense::segmented_map und ankerl::unordered_dense::segmented_set mit niedrigerer Peak -Speicherverwendung. und stabile Iterator/Referenzen auf dem Insert.
ankerl::unordered_dense::hashis_transparentstd::hashauto extract() && -> value_container_typeextract() einzelne Elemente[[nodiscard]] auto values() const noexcept -> value_container_type const&auto replace(value_container_type&& container)ankerl::unordered_dense::bucket_type::standardankerl::unordered_dense::bucket_type::bigsegmented_map und segmented_set Das gewählte Design hat einige Vorteile gegenüber std::unordered_map :
std::vector gespeichert, alle Daten sind zusammenhängend!absl::flat_hash_mapstd::allocators und polymorphe Allocatoren. Es gibt ankerl::unordered_dense::pmr Typedefs verfügbarstd::vector zum boost::interprocess::vector oder einem anderen kompatiblen zufälligen Zugriffsbehälter wechseln.std::vector anzeigen kann.Es gibt kein kostenloses Mittagessen, also gibt es ein paar Nachteile:
const Key in std::pair<Key, Value> Der Standard -Installationsort ist /usr/local .
Klonen Sie das Repository und führen Sie diese Befehle im geklonten Ordner aus:
mkdir build && cd build
cmake ..
cmake --build . --target install Überlegen Sie, ob Sie ein Installationspräfix einstellen, wenn Sie nicht das System breit unordered_dense installieren möchten, wie dies:
mkdir build && cd build
cmake -DCMAKE_INSTALL_PREFIX:PATH= ${HOME} /unordered_dense_install ..
cmake --build . --target installUm die installierte Bibliothek zu nutzen, fügen Sie dies Ihrem Projekt hinzu:
find_package (unordered_dense CONFIG REQUIRED)
target_link_libraries (your_project_name unordered_dense::unordered_dense) ankerl::unordered_dense unterstützt C ++ 20 Module. Kompilieren Sie einfach src/ankerl.unordered_dense.cpp und verwenden Sie das resultierende Modul, z. B. SO:
clang++ -std=c++20 -I include --precompile -x c++-module src/ankerl.unordered_dense.cpp
clang++ -std=c++20 -c ankerl.unordered_dense.pcm Um das Modul mit EG in module_test.cpp zu verwenden, verwenden Sie
import ankerl.unordered_dense;und mit z.
clang++ -std=c++20 -fprebuilt-module-path=. ankerl.unordered_dense.o module_test.cpp -o main Ein einfaches Demo -Skript finden Sie in test/modules .
ankerl::unordered_dense::hash ist ein schneller und hochwertiger Hash, der auf Wyhash basiert. Die ankerl::unordered_dense Map/Set unterscheidet zwischen Hashes von hoher Qualität (guter Lawiereffekt) und schlechter Qualität. Hashes mit guter Qualität enthalten einen speziellen Marker:
using is_avalanching = void ; Dies sind die Fälle für die Spezialisierungen bool , char , signed char , unsigned char , char8_t , char16_t , char32_t , wchar_t , short , unsigned short , int , unsigned int , long , long long , unsigned long , enum unsigned long long , T* , Std std::shared_ptr<T> std::unique_ptr<T> std::basic_string<C> std: und std::basic_string_view<C> .
Hashes, die keinen solchen Marker enthalten, werden von schlechter Qualität angenommen und erhalten einen zusätzlichen Mischschritt in der MAP/SET -Implementierung.
Betrachten Sie einen einfachen benutzerdefinierten Schlüsseltyp:
struct id {
uint64_t value{};
auto operator ==(id const & other) const -> bool {
return value == other. value ;
}
};Die einfachste Implementierung eines Hashs ist Folgendes:
struct custom_hash_simple {
auto operator ()(id const & x) const noexcept -> uint64_t {
return x. value ;
}
};Dies kann verwendet werden, z. B. mit
auto ids = ankerl::unordered_dense::set<id, custom_hash_simple>(); Da custom_hash_simple keine using is_avalanching = void; Marker Es wird als von schlechter Qualität angesehen, und im Set wird automatisch die zusätzliche Mischung von x.value bereitgestellt.
Zurück zum id -Beispiel können wir leicht einen Hash in höherer Qualität implementieren:
struct custom_hash_avalanching {
using is_avalanching = void ;
auto operator ()(id const & x) const noexcept -> uint64_t {
return ankerl::unordered_dense::detail::wyhash::hash (x. value );
}
}; Wir wissen, wyhash::hash von hoher Qualität ist, sodass wir using is_avalanching = void; Dadurch wird der zurückgegebene Wert direkt verwendet.
ankerl::unordered_dense::hash Anstatt eine neue Klasse zu erstellen, können Sie auch ankerl::unordered_dense::hash spezialisiert:
template <>
struct ankerl ::unordered_dense::hash<id> {
using is_avalanching = void ;
[[nodiscard]] auto operator ()(id const & x) const noexcept -> uint64_t {
return detail::wyhash::hash (x. value );
}
};is_transparent Diese Karte/Set unterstützt heterogene Überladungen wie in P2363 beschrieben, die assoziative Behälter mit den verbleibenden heterogenen Überladungen erweitern, die für C ++ 26 abzielt. Dies enthält Überladungen für find , count , contains , equal_range (siehe P0919R3), erase (siehe P2077R2) und try_emplace , insert_or_assign , operator[] , at und insert & emplace für Sets (siehe P2363R3).
Damit heterogene Überladungen Affekte ergreifen können, müssen sowohl hasher als auch key_equal das Attribut is_transparent set haben.
Hier ist eine Beispielimplementierung, die mit allen String -Typen verwendet werden kann, die mit std::string_view (z. B. char const* und std::string ) konvertierbar sind:
struct string_hash {
using is_transparent = void ; // enable heterogeneous overloads
using is_avalanching = void ; // mark class as high quality avalanching hash
[[nodiscard]] auto operator ()(std::string_view str) const noexcept -> uint64_t {
return ankerl::unordered_dense::hash<std::string_view>{}(str);
}
}; Um diesen Hash zu verwenden, müssen Sie ihn als Typ angeben, und auch als key_equal mit is_transparent wie std :: Equal_to <>:
auto map = ankerl::unordered_dense::map<std::string, size_t , string_hash, std::equal_to<>>(); Weitere Informationen finden Sie in den Beispielen in test/unit/transparent.cpp .
std::hash Wenn eine Implementierung für std::hash eines benutzerdefinierten Typs verfügbar ist, wird automatisch verwendet und angenommen, dass sie von schlechter Qualität ist (somit wird std::hash verwendet, es wird jedoch ein zusätzlicher Mischschritt durchgeführt).
Wenn der Typ eine eindeutige Objektdarstellung hat (keine Polsterung, trivial kopierbar), kann man nur den Speicher des Objekts haben. Betrachten Sie eine einfache Klasse
struct point {
int x{};
int y{};
auto operator ==(point const & other) const -> bool {
return x == other. x && y == other. y ;
}
};Ein schneller und hochwertiger Hash kann leicht wie SO bereitgestellt werden:
struct custom_hash_unique_object_representation {
using is_avalanching = void ;
[[nodiscard]] auto operator ()(point const & f) const noexcept -> uint64_t {
static_assert (std::has_unique_object_representations_v<point>);
return ankerl::unordered_dense::detail::wyhash::hash (&f, sizeof (f));
}
}; Zusätzlich zu der Standard -API std::unordered_map (siehe https://en.cppreference.com/w/cpp/container/unordered_map) haben wir zusätzliche API, die der Node -API etwas ähnlich ist, aber die Tatsache, dass wir einen zufälligen Zugangscontainer intern ähneln:
auto extract() && -> value_container_type Extrahiert den intern verwendeten Behälter. *this wird geleert.
extract() einzelne Elemente Ähnlich wie erase() habe ich einen API -Aufrufextrakt extract() . Es verhält sich genauso wie erase , außer dass der Rückgabewert das bewegte Element ist, das aus dem Container entfernt wird:
auto extract(const_iterator it) -> value_typeauto extract(Key const& key) -> std::optional<value_type>template <class K> auto extract(K&& key) -> std::optional<value_type> Beachten Sie, dass die API extract(key) ein std::optional<value_type> zurückgibt, das leer ist, wenn der Schlüssel nicht gefunden wird.
[[nodiscard]] auto values() const noexcept -> value_container_type const&Entellt den zugrunde liegenden Wertecontainer.
auto replace(value_container_type&& container)Verwaltet den intern gehaltenen Behälter und ersetzt ihn durch das, die übergeben wurden. Nicht einseitige Elemente werden entfernt und der Behälter wird teilweise neu angeordnet, wenn nicht eindeutige Elemente gefunden werden.
unordered_dense akzeptiert einen benutzerdefinierten Allocator, aber Sie können auch einen benutzerdefinierten Container für dieses Vorlagenargument angeben. Auf diese Weise ist es möglich, den intern verwendeten std::vector durch z. B. std::deque oder einen anderen Container wie boost::interprocess::vector zu ersetzen. Dies unterstützt ausgefallene Zeiger (z. B. offset_ptr), sodass der Container mit dem von boost::interprocess bereitgestellten EG -Shared -Speicher verwendet werden kann.
Die Karte/Set unterstützt zwei verschiedene Eimer -Typen. Der Standard sollte für so ziemlich alle gut sein.
ankerl::unordered_dense::bucket_type::standardankerl::unordered_dense::bucket_type::bigsegmented_map und segmented_set ankerl::unordered_dense bietet eine benutzerdefinierte Container -Implementierung mit geringeren Speicheranforderungen als die Standard std::vector . Das Gedächtnis ist nicht zusammenhängend, kann aber Segmente zuweisen, ohne alle Elemente neu zuzuordnen und zu bewegen. Zusammenfassend führt dies zu
std::vector , da eine zusätzliche Indirektion erforderlich ist. Hier ist ein Vergleich mit absl::flat_hash_map und dem ankerl::unordered_dense::map beim Einfügen von 10 Millionen Einträgen 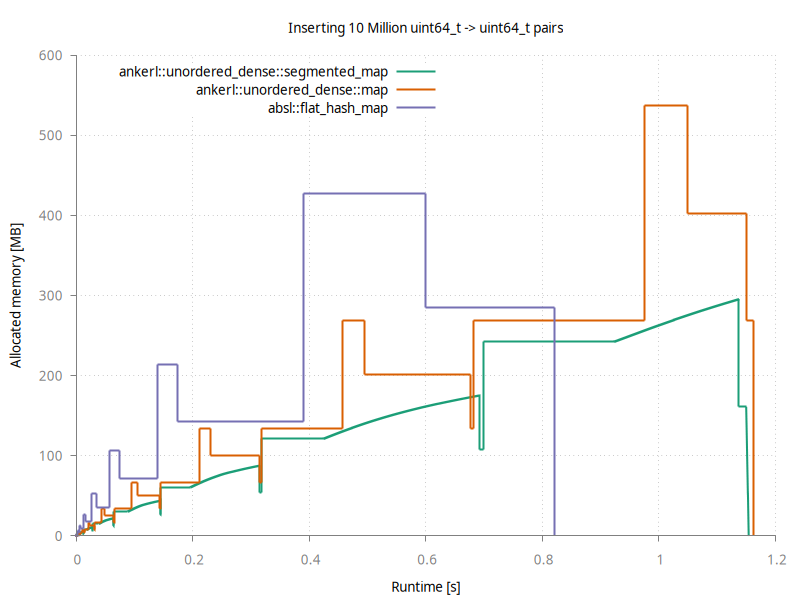
Abseil ist für diesen einfachen Einfügungstest am schnellsten und dauert etwas mehr als 0,8 Sekunden. Die Nutzung des Spitzengedächtnisses beträgt ca. 430 MB. Beachten Sie, wie die Speicherverwendung nach dem letzten Peak sinkt. Wenn es auf ~ 290 MB sinkt, hat es das Wiederauflösen abgeschlossen und kann den zuvor gebrauchten Speicherblock befreien.
ankerl::unordered_dense::segmented_map hat diese Peaks nicht und hat stattdessen eine reibungslose Erhöhung der Speicherverwendung. Beachten Sie, dass es immer noch plötzliche Abfälle und Erhöhungen des Speichers gibt, da die Anforderungen an die Indexierungsdaten um einen festen Faktor noch erhöhen müssen. Da die Daten jedoch in einem separaten Container gehalten werden, können wir zuerst die alte Datenstruktur befreien und dann eine neue, größere Indexierungsstruktur zuordnen. Daher haben wir keine Peaks.
Die Karte/Set verfügt über zwei Datenstrukturen:
std::vector<value_type> , das alle Daten enthält. Map/Set Iteratoren sind nur std::vector<value_type>::iterator ! Immer wenn ein Element hinzugefügt wird, wird es emplace_back an den Vektor. Der Schlüssel ist gehasht und am entsprechenden Ort im Eimer -Array wird ein Eintrag (Eimer) hinzugefügt. Der Eimer hat diese Struktur:
struct Bucket {
uint32_t dist_and_fingerprint;
uint32_t value_idx;
};Jeder Eimer speichert 3 Dinge:
dist_and_fingerprint )dist_and_fingerprint )Diese Struktur ist speziell für die Kollisionsauflösungsstrategie Robin-Hood Hashing mit Rückwärtsverschiebungsdeletion ausgelegt.
Der Schlüssel ist gehasht und das Eimer -Array wird durchsucht, wenn es einen Eintrag an diesem Ort mit diesem Fingerabdruck hat. Wenn gefunden wird der Schlüssel im Datenvektor verglichen, und wenn der Wert gleichermaßen zurückgegeben wird.
Da alle Daten in einem Vektor gespeichert sind, sind die Entfernungen etwas komplizierter:
value_idx des bewegten Elements. Dies erfordert eine weitere Suche. Am 2023-09-10 habe ich eine schnelle Suche bei GitHub durchgeführt, um festzustellen, ob diese Karte in beliebten Open-Source-Projekten verwendet wird. Hier sind einige der Projekte, die ich gefunden habe. Bitte senden Sie mir eine Notiz, wenn Sie möchten, auf dieser Liste!


