PepGLAD
checkpoints
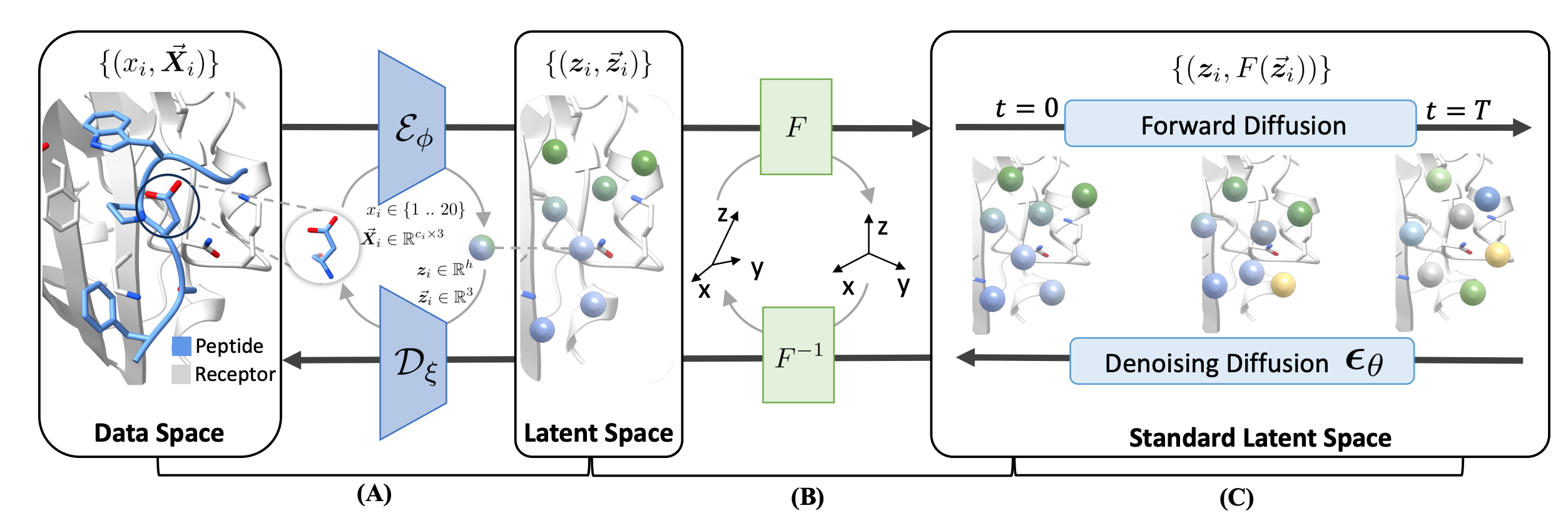
Die Conda -Umgebung kann mit der Konfiguration env.yaml konstruiert werden:
conda env create -f env.yaml Die Codes werden mit CUDA Version 11.7 und Pytorch Version 1.13.1 getestet.
Vergessen Sie nicht, die Umgebung zu aktivieren, bevor Sie die Codes ausführen:
conda activate PepGLADPyrosetta wird verwendet, um die Grenzflächenenergie erzeugter Peptide zu berechnen. Wenn Sie daran interessiert sind, befolgen Sie bitte die Anweisung hier, um sie zu installieren.
Diese Datensätze werden nur für Benchmarking -Modelle verwendet. Wenn Sie nur die geschulten Gewichte für die Inferenz in Ihren Fällen verwenden möchten, müssen diese Datensätze nicht heruntergeladen werden.
Die ursprünglich in diesem Artikel eingeführten Datensätze werden in dieser URL auf Zenodo hochgeladen. Sie können sie wie folgt herunterladen:
mkdir datasets # all datasets will be put into this directory
wget https://zenodo.org/records/13373108/files/train_valid.tar.gz ? download=1 -O ./datasets/train_valid.tar.gz # training/validation
wget https://zenodo.org/records/13373108/files/LNR.tar.gz ? download=1 -O ./datasets/LNR.tar.gz # test set
wget https://zenodo.org/records/13373108/files/ProtFrag.tar.gz ? download=1 -O ./datasets/ProtFrag.tar.gz # augmentation datasettar zxvf ./datasets/train_valid.tar.gz -C ./datasets
tar zxvf ./datasets/LNR.tar.gz -C ./datasets
tar zxvf ./datasets/ProtFrag.tar.gz -C ./datasetspython -m scripts.data_process.process --index ./datasets/train_valid/all.txt --out_dir ./datasets/train_valid/processed # train/validation set
python -m scripts.data_process.process --index ./datasets/LNR/test.txt --out_dir ./datasets/LNR/processed # test set
python -m scripts.data_process.process --index ./datasets/ProtFrag/all.txt --out_dir ./datasets/ProtFrag/processed # augmentation dataset Der Index der verarbeiteten Daten für Zug-/Validierungsaufteilungen muss wie folgt generiert werden, was zu datasets/train_valid/processed/train_index.txt und datasets/train_valid/processed/valid_index.txt führt:
python -m scripts.data_process.split --train_index datasets/train_valid/train.txt --valid_index datasets/train_valid/valid.txt --processed_dir datasets/train_valid/processed/wget http://huanglab.phys.hust.edu.cn/pepbdb/db/download/pepbdb-20200318.tgz -O ./datasets/pepbdb.tgztar zxvf ./datasets/pepbdb.tgz -C ./datasets/pepbdbpython -m scripts.data_process.pepbdb --index ./datasets/pepbdb/peptidelist.txt --out_dir ./datasets/pepbdb/processed
python -m scripts.data_process.split --train_index ./datasets/pepbdb/train.txt --valid_index ./datasets/pepbdb/valid.txt --test_index ./datasets/pepbdb/test.txt --processed_dir datasets/pepbdb/processed/
mv ./datasets/pepbdb/processed/pdbs ./dataset/pepbdb # re-locate./checkpoint/codesign.ckpt./checkpoints/fixseq.ckptBeide können auf der Release -Seite heruntergeladen werden. Diese Kontrollpunkte wurden auf Pepbench trainiert.
Take ./assets/1ssc_A_B.pdb als Beispiel, wobei Kette A das Zielprotein ist:
# obtain the binding site, which might also be manually crafted or from other ligands (e.g. small molecule, antibodies)
python -m api.detect_pocket --pdb assets/1ssc_A_B.pdb --target_chains A --ligand_chains B --out assets/1ssc_A_pocket.json
# sequence-structure codesign with length in [8, 15)
CUDA_VISIBLE_DEVICES=0 python -m api.run
--mode codesign
--pdb assets/1ssc_A_B.pdb
--pocket assets/1ssc_A_pocket.json
--out_dir ./output/codesign
--length_min 8
--length_max 15
--n_samples 10 Dann werden 10 Generationen unter dem Ordner ausgegeben ./output/codesign .
Take ./assets/1ssc_A_B.pdb als Beispiel, wobei Kette A das Zielprotein ist:
# obtain the binding site, which might also be manually crafted or from other ligands (e.g. small molecule, antibodies)
python -m api.detect_pocket --pdb assets/1ssc_A_B.pdb --target_chains A --ligand_chains B --out assets/1ssc_A_pocket.json
# generate binding conformation
CUDA_VISIBLE_DEVICES=0 python -m api.run
--mode struct_pred
--pdb assets/1ssc_A_B.pdb
--pocket assets/1ssc_A_pocket.json
--out_dir ./output/struct_pred
--peptide_seq PYVPVHFDASV
--n_samples 10 Anschließend werden 10 Konformationen unter dem Ordner ausgegeben ./output/struct_pred .
Jede Aufgabe erfordert die folgenden Schritte, die wir in das Skript integriert haben ./scripts/run_exp_pipe.sh :
Auf der anderen Seite befolgen Sie die folgenden Anweisungen (zB Konformationsgenerierung), wenn Sie vorhandene Kontrollpunkte bewerten möchten:
# generate results on the test set and save to ./results/fixseq
python generate.py --config configs/pepbench/test_fixseq.yaml --ckpt checkpoints/fixseq.ckpt --gpu 0 --save_dir ./results/fixseq
# calculate metrics
python cal_metrics.py --results ./results/fixseq/results.jsonlCodessign -Experimente auf Pepbench:
GPU=0 bash scripts/run_exp_pipe.sh pepbench_codesign configs/pepbench/autoencoder/train_codesign.yaml configs/pepbench/ldm/train_codesign.yaml configs/pepbench/ldm/setup_latent_guidance.yaml configs/pepbench/test_codesign.yamlExperimente zur Konformationsgenerierung auf Pepbench:
GPU=0 bash scripts/run_exp_pipe.sh pepbench_fixseq configs/pepbench/autoencoder/train_fixseq.yaml configs/pepbench/ldm/train_fixseq.yaml configs/pepbench/ldm/setup_latent_guidance.yaml configs/pepbench/test_fixseq.yamlVielen Dank für Ihr Interesse an unserer Arbeit!
Bitte stellen Sie sich gerne zu Fragen zu den Algorithmen, Codes sowie zu Problemen beim Ausführen von Problemen, damit wir es klarer und besser machen können. Sie können entweder ein Problem im Github Repo erstellen oder uns unter [email protected] kontaktieren.
@article { kong2024full ,
title = { Full-atom peptide design with geometric latent diffusion } ,
author = { Kong, Xiangzhe and Huang, Wenbing and Liu, Yang } ,
journal = { arXiv preprint arXiv:2402.13555 } ,
year = { 2024 }
}

