genai chatbot
1.0.0
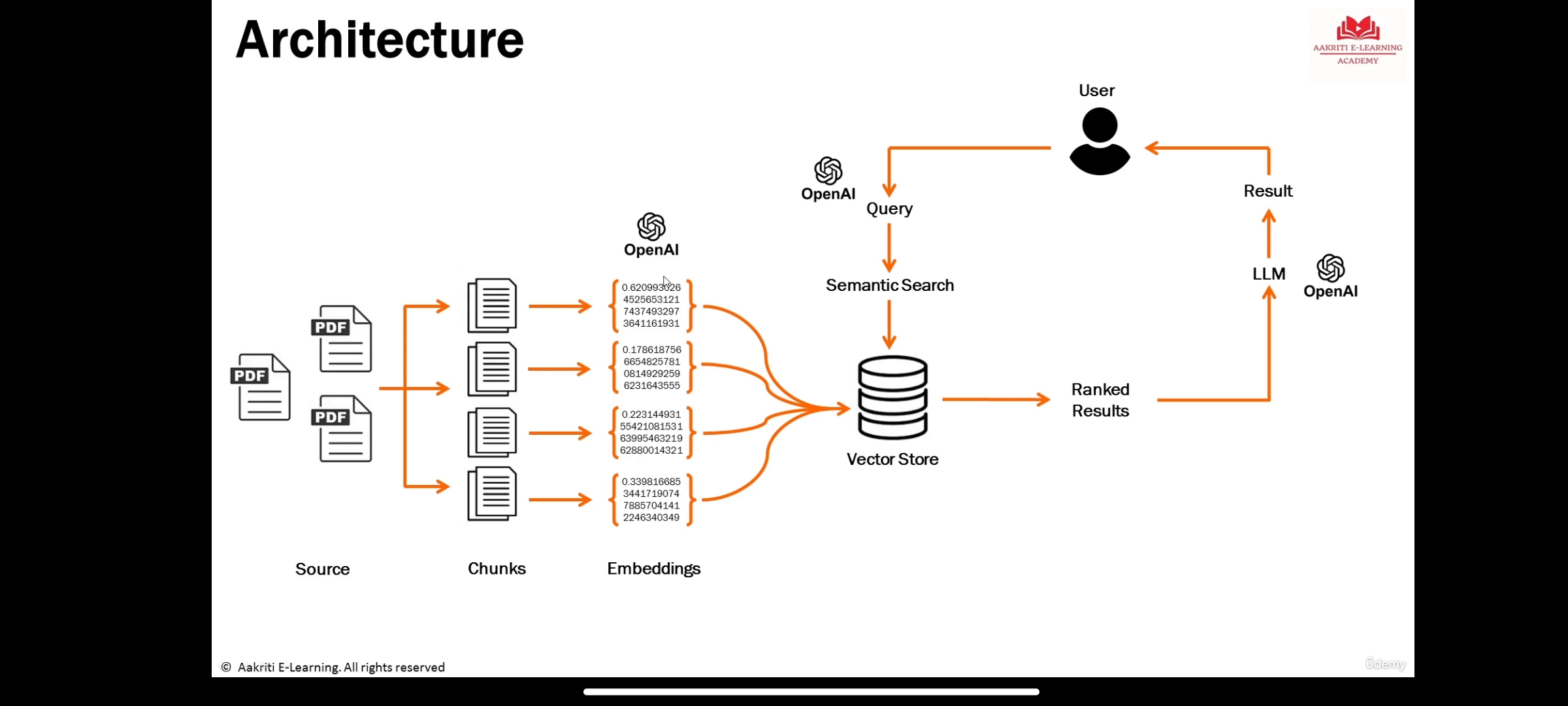
LLMS هي نماذج كبيرة للتعلم العميق المدربين مسبقًا على كميات كبيرة من البيانات التي يمكنها إنشاء ردود على استعلامات المستخدم
تمثيل المعلومات للمعنى الدلالي لنص أو كائنات مثل الصوت أو الفيديو أو الصور وما إلى ذلك. يجب استهلاكها بواسطة نماذج التعلم الآلي أو خوارزميات البحث المسلح (LLM).
هي قاعدة بيانات لتخزين التضمينات حيث يحدث البحث الدلالي.
import streamlit as st
from PyPDF2 import PdfReader
from langchain . text_splitter import RecursiveCharacterTextSplitter
from langchain_community . embeddings import OpenAIEmbeddings
from langchain_community . vectorstores import FAISS
from langchain . chains . question_answering import load_qa_chain
from langchain_community . chat_models import ChatOpenAI
OPENAI_API_KEY = "sk-Wr5VzIVOwRoIyzTkQTjiaLQ6lSc84" #Pass your key here
#Upload PDF files
st . header ( "My first Chatbot" )
with st . sidebar :
st . title ( "Your Documents" )
file = st . file_uploader ( " Upload a PDf file and start asking questions" , type = "pdf" )
#Extract the text
if file is not None :
pdf_reader = PdfReader ( file )
text = ""
for page in pdf_reader . pages :
text += page . extract_text ()
#st.write(text)
#Break it into chunks
text_splitter = RecursiveCharacterTextSplitter (
separators = " n " ,
chunk_size = 1000 ,
chunk_overlap = 150 ,
length_function = len
)
chunks = text_splitter . split_text ( text )
#st.write(chunks)
# generating embedding
embeddings = OpenAIEmbeddings ( openai_api_key = OPENAI_API_KEY )
# creating vector store - FAISS
vector_store = FAISS . from_texts ( chunks , embeddings )
# get user question
user_question = st . text_input ( "Type Your question here" )
# do similarity search
if user_question :
match = vector_store . similarity_search ( user_question )
#st.write(match)
#define the LLM
llm = ChatOpenAI (
openai_api_key = OPENAI_API_KEY ,
temperature = 0 ,
max_tokens = 1000 ,
model_name = "gpt-3.5-turbo"
)
#output results
#chain -> take the question, get relevant document, pass it to the LLM, generate the output
chain = load_qa_chain ( llm , chain_type = "stuff" )
response = chain . run ( input_documents = match , question = user_question )
st . write ( response )


